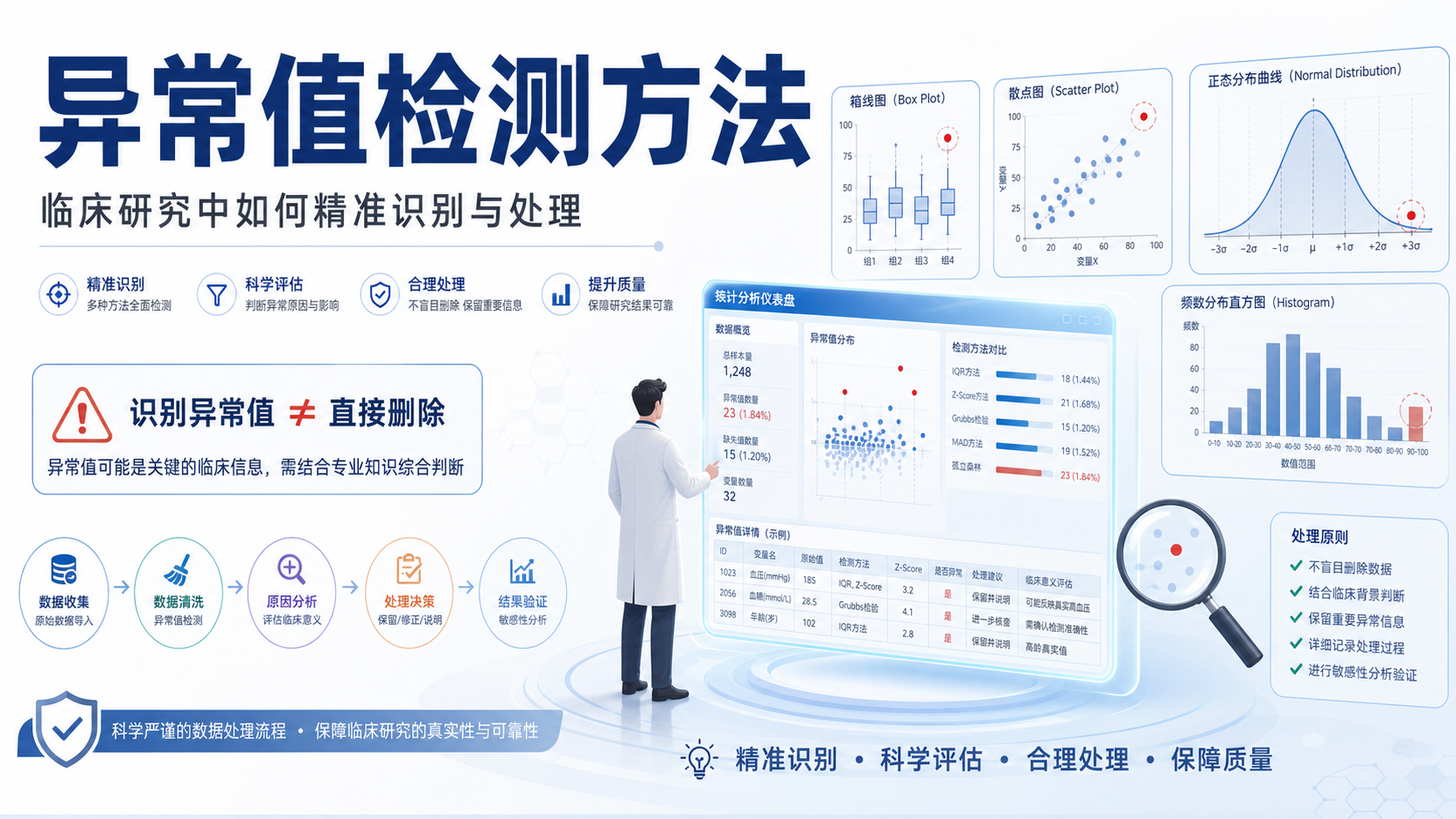
引言Introduction
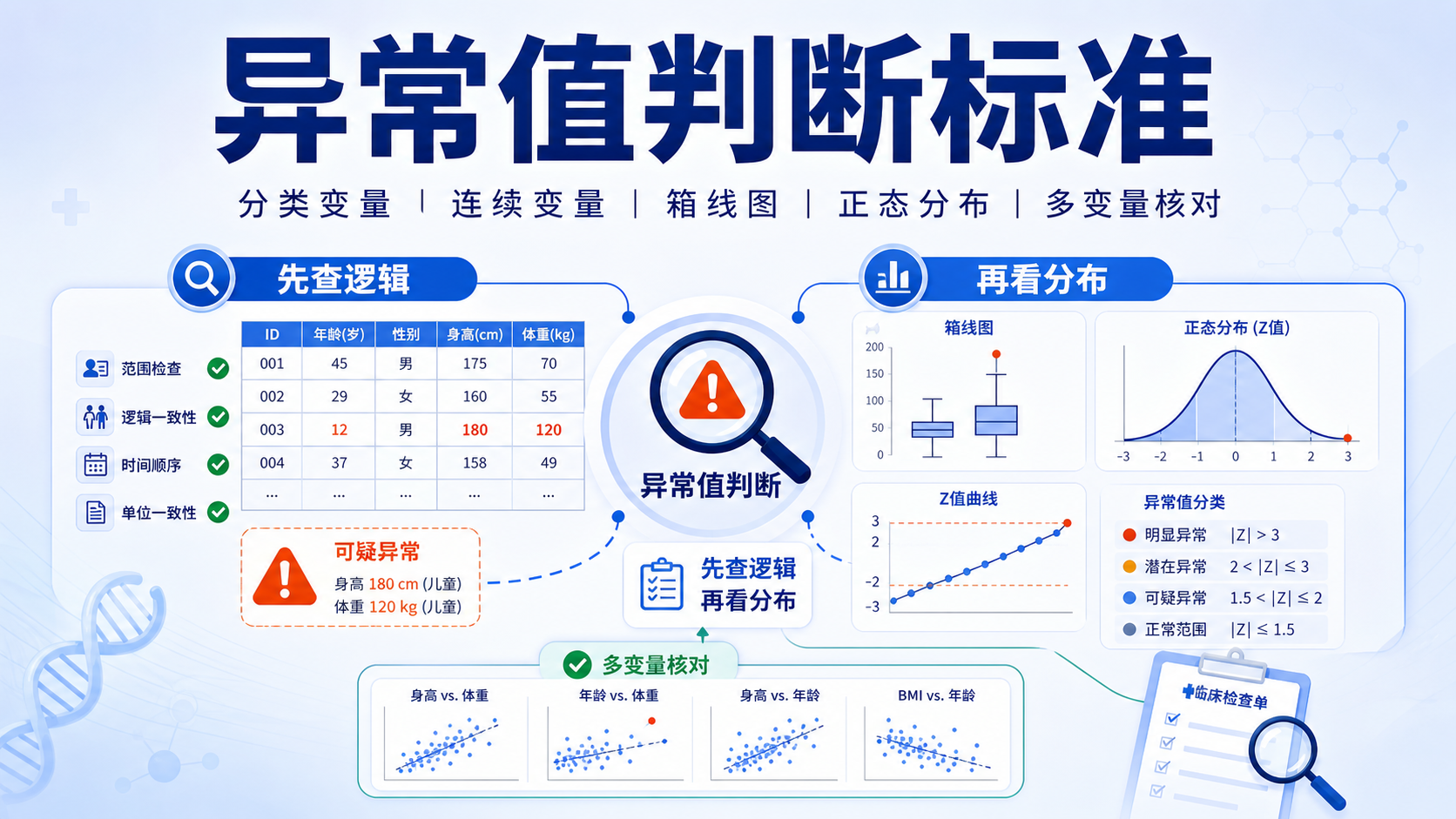
异常值判断标准是临床研究数据清洗的第一道关口。很多医学生和科研人员都遇到过同样的问题。数据看起来“离谱”,却不敢删;看起来“合理”,又担心漏掉真正的错误。判断异常值,不能只看数值大小,还要看变量逻辑、分布形态和临床常识。
1. 先理解异常值判断标准的核心逻辑
1.1 异常值不等于极端值
在临床数据里,异常值主要分两类。第一类是逻辑错误。第二类是分布异常。前者是“本身就不可能”。后者是“统计上显著偏离”。
异常值判断标准的本质,是先判断数据是否违背研究定义,再判断它是否偏离整体分布。 这两步顺序不能反。
比如性别变量若规定1代表男性、2代表女性,就不应出现3、2.5。再如年龄出现205岁、-1岁,明显不符合常理。还有一些更隐蔽的情况,例如“是否吸烟=否”,但“每日吸烟支数”不为0,这也是逻辑冲突。
1.2 先查逻辑,再看分布
临床数据清洗中,建议先做逻辑核查,再做统计识别。因为很多异常值根本不需要复杂模型,直接用常识就能发现。
常见核查点包括:
- 变量取值范围是否符合定义
- 分类变量是否出现非法编码
- 相关变量之间是否互相矛盾
- 单位是否录错,如厘米写成米
- 关键生理指标是否违反临床规律,如舒张压高于收缩压
如果逻辑上站不住,往往就可以直接判定为异常。 这一步是异常值判断标准中最容易被忽视,但最重要的一步。
2. 场景一:分类变量的异常值判断标准
2.1 看编码是否落在允许范围内
分类变量的判断最直接。只要先定义了编码,后续就要严格按编码检查。比如肿瘤分级定义为1到4级,就不能出现5或6。性别若只设定为1和2,就不能出现其他数值。
这种类型的异常,通常属于录入错误或编码错误。它的处理优先级很高,因为它不是“统计波动”,而是“规则失配”。
2.2 看频数分布是否出现不合逻辑的类别
对分类变量,也可以通过频数分布辅助判断。若某个类别在研究设计中根本不存在,却被录入数据表中,就要立刻复核。
例如:
- 本研究仅纳入成人,却出现“儿童组”
- 变量仅有“是/否”,却出现“未知”且未定义
- 结局事件为二分类,却混入第三类状态
分类变量的异常值判断标准,核心是“编码合法性”和“研究定义一致性”。 这类错误不依赖复杂统计软件,靠规则核对就能发现。
3. 场景二:连续变量的极值判断标准
3.1 先用临床常识设下限和上限
连续变量最先要做的是“合理区间判断”。例如年龄不应为负值,身高若单位为厘米,则1.78这种记录往往提示单位混淆。
临床上很多变量都有天然边界。比如:
- 年龄不应出现负数
- 生命体征应符合生理范围
- 实验室指标应结合检测方法和单位解释
异常值判断标准不是一刀切的固定数字,而是“变量定义+临床可解释范围”的组合。 这是科研数据清洗里最实用的思路。
3.2 重点关注单位错误和字段串位
连续变量里,最常见的不是“真的异常”,而是“录入方式错误”。比如升高变量设定单位是厘米,却录成1.78。再比如舒张压和收缩压放反,也会造成表面异常。
这类数据需要回到原始病例或采集记录核对。若无法核对,且变量又非常关键,就要谨慎处理。对结局变量、暴露变量的异常值,通常不能轻率删掉。
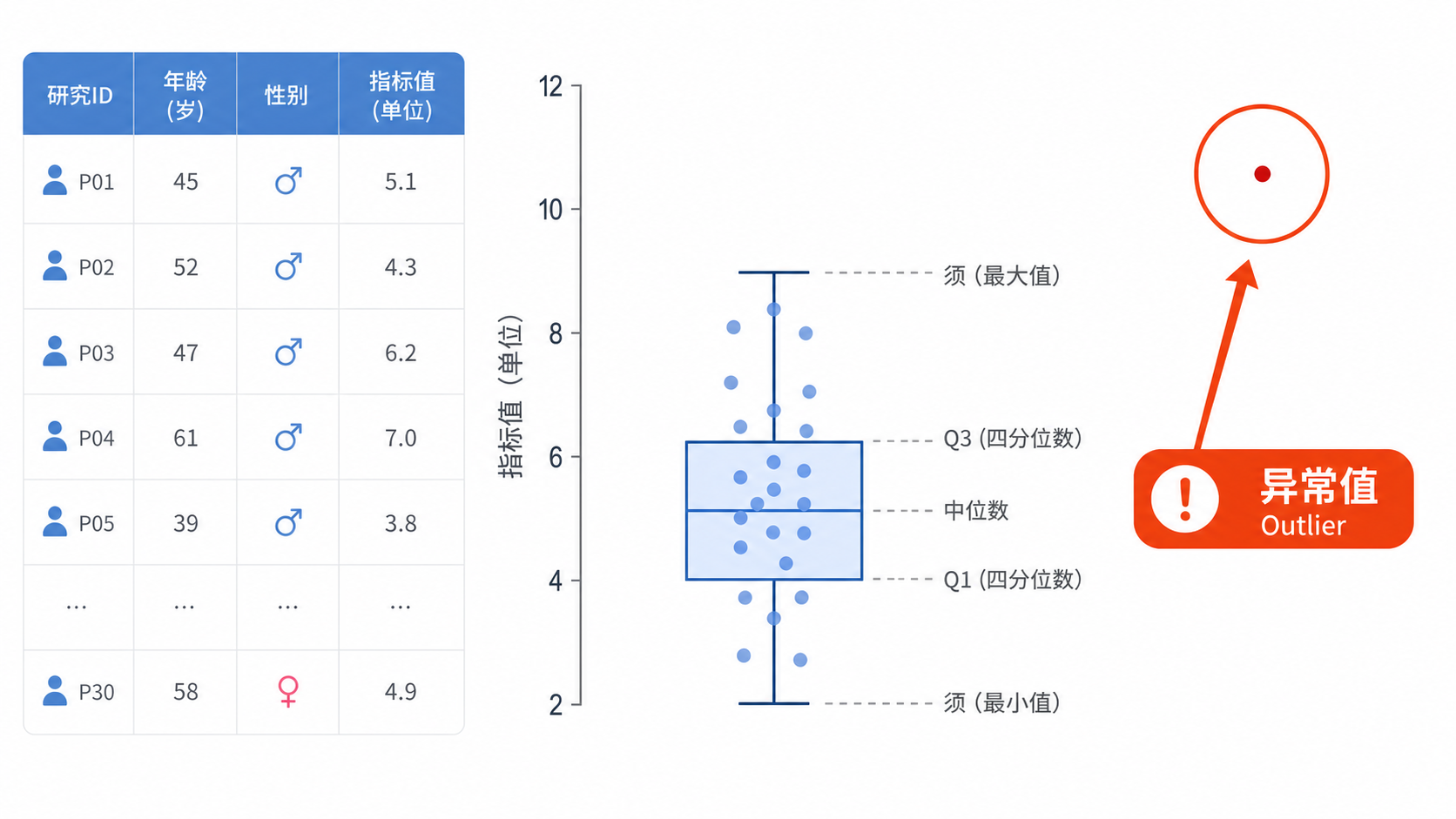
4. 场景三:箱线图下的异常值判断标准
4.1 1.5倍四分位间距是最常用规则
当处理连续变量时,箱线图是最常见的异常值识别工具。其常用判断标准是:
- 上界 = Q3 + 1.5×IQR
- 下界 = Q1 - 1.5×IQR
其中IQR是四分位间距。
如果数据点落在这个范围之外,系统通常会标记为异常值。这也是很多统计软件默认采用的异常值判断标准。
4.2 为什么箱线图适合临床研究
箱线图的优点是直观。它不要求数据必须正态分布,适合多数临床变量初筛。尤其在样本量较大、分布偏态明显时,箱线图比单纯看均数更可靠。
例如在一组连续型指标中,若第31号和第81号个案落在箱体外,且超出1.5倍IQR的界限,就应优先标记,而不是直接忽略。
箱线图的价值,不在于“删不删”,而在于先把可疑点找出来。
5. 场景四:正态分布下的异常值判断标准
5.1 用Z值判断偏离程度
当数据近似正态分布时,可以用Z值评估异常。Z值公式为:
Z = (当前值 - 均值)/ 标准差
经验上,若Z值大于2,常提示该值偏离较明显。正态分布中,约68.26%的数据位于1个标准差内,约95%位于2个标准差内。也就是说,超过2个标准差之外的点,比例已经很小。
在正态分布场景下,异常值判断标准可以理解为“距离均值太远”。 这个方法适合标准化后比较,也便于跨变量横向判断。
5.2 不要把“偏远”自动等于“错误”
需要注意,Z值大并不一定代表错误。它只说明“少见”。如果研究对象本身存在真实极端值,比如危重患者的某些实验室指标,本来就可能偏离常规范围。
因此,Z值法更适合提示可疑点,而不是最终裁决。最终仍需结合临床背景、采集过程和研究设计判断。
6. 场景五:多变量逻辑核对的异常值判断标准
6.1 看变量之间是否互相矛盾
很多异常值不是单个字段的问题,而是多个字段之间不一致。典型例子包括:
- 选择“否吸烟”,但每日吸烟支数大于0
- 舒张压高于收缩压
- 身高单位与数值不匹配
- 结局发生时间早于暴露时间
这些都属于逻辑冲突。在临床研究中,这类异常值判断标准比单变量极值更重要。
6.2 用变量关系提高清洗质量
单看一个数值,可能误判。联合变量一起看,判断会更准确。尤其在预后研究、回顾性队列和多中心数据库中,字段之间的联动核查非常必要。
建议建立基础核查清单:
- 人口学变量核查
- 生命体征核查
- 暴露与结局顺序核查
- 单位与编码核查
- 缺失与异常联动核查
这套思路能显著提高数据质量,也更符合E-E-A-T所强调的专业性和可信度。
7. 场景六:异常值处理前后的判断标准
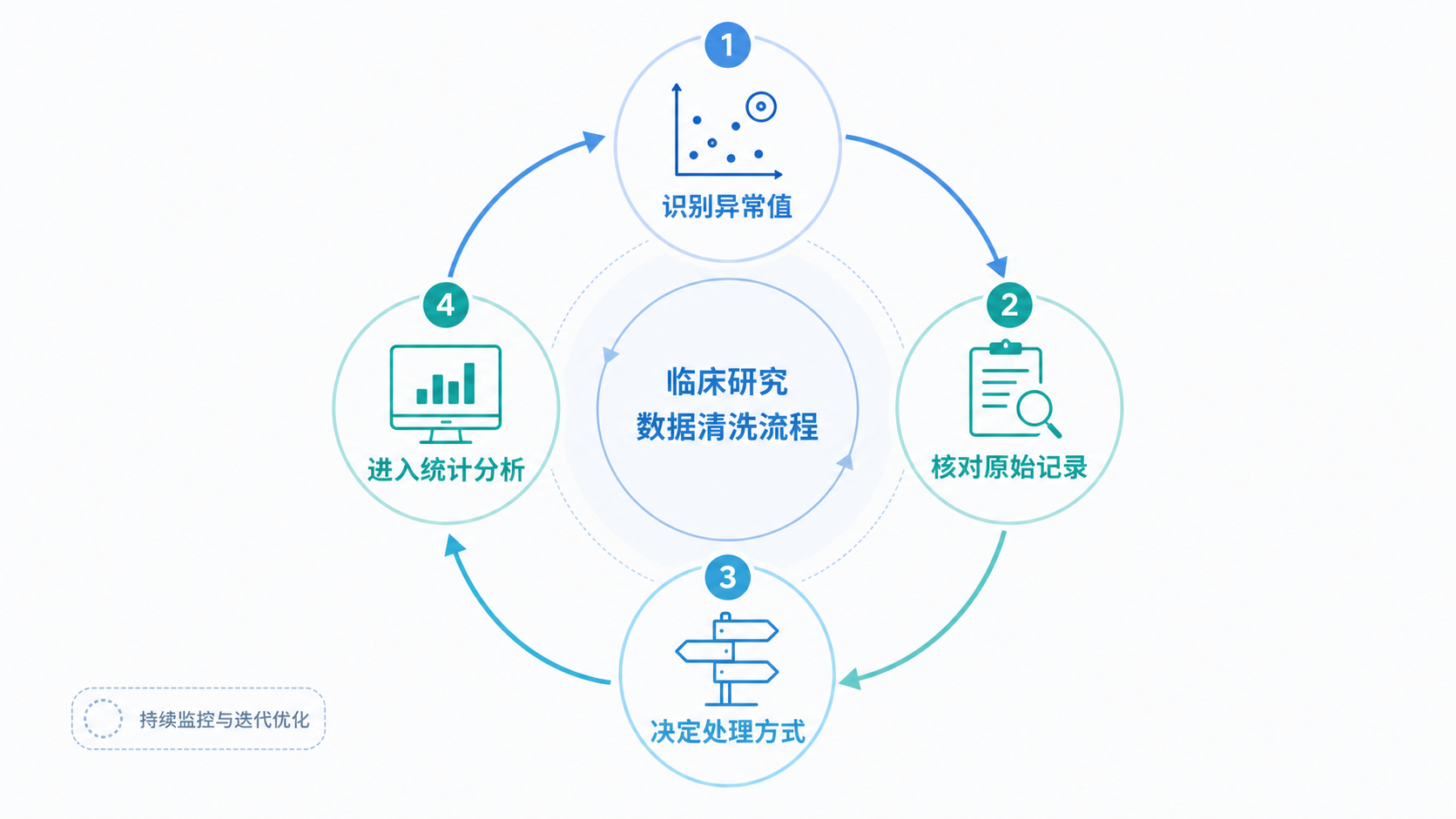
7.1 不要只问“是不是异常”,还要问“能不能处理”
识别出异常值后,下一步不是机械删除,而是评估处理方式。常见做法包括:
- 回查原始资料并修正
- 个案删除
- 改为缺失值后再处理
- 保留异常值但加标记
- 做稳健分析,如用中位数或截尾均数
异常值判断标准最终要服务于分析结论,而不是停留在识别层面。
7.2 重要变量要更谨慎
如果异常值出现在分组变量、暴露因素或结局变量中,处理一定要谨慎。因为一旦删除,可能影响样本量和结论稳定性。通常建议先比较删除前后的分析结果,再决定是否保留。
如果两次结果一致,说明该异常值影响有限。若结果明显变化,就要重新评估处理决策。这一步能避免因过度清洗而扭曲真实结论。
总结Conclusion
异常值判断标准不是单一规则,而是一个分层决策过程。先看逻辑,再看分布。先判定是否违背研究定义,再判断是否偏离整体分布。分类变量重在编码合法性,连续变量重在临床合理范围,箱线图和Z值则用于辅助识别。
对于医学生、医生和科研人员来说,真正高质量的数据清洗,不是“把异常都删掉”,而是“把异常分清楚、处理对”。如果你希望把异常值识别、处理、回查和稳健分析做得更系统,可以结合解螺旋的临床研究课程与工具内容,提升数据清洗效率和分析可信度。
- 引言Introduction
- 1. 先理解异常值判断标准的核心逻辑
- 2. 场景一:分类变量的异常值判断标准
- 3. 场景二:连续变量的极值判断标准
- 4. 场景三:箱线图下的异常值判断标准
- 5. 场景四:正态分布下的异常值判断标准
- 6. 场景五:多变量逻辑核对的异常值判断标准
- 7. 场景六:异常值处理前后的判断标准
- 总结Conclusion