引言Introduction
在做t检验、方差分析或回归前,方差齐性检验 往往是先要确认的一步。很多人会卡在“该用哪个函数”“R里怎么写代码”“结果怎么看”。本文围绕方差齐性检验 R 语言代码 ,用最常见的思路帮你快速上手。
1. 什么是方差齐性检验
1.1 先理解它的作用
方差齐性检验的核心,是判断不同组数据的离散程度是否相近 。如果各组方差差异很大,很多经典参数检验的前提就不成立。
在医学研究里,这一步很常见。比如比较对照组和治疗组的指标均值,或比较多组临床分组的结局变量,先看方差是否齐,能减少后续分析走弯路。
简单说,方差齐性检验是在回答:不同组的数据波动是否一致。
1.2 为什么R语言适合做这件事
R语言本身就是统计运算工具。它的优势是函数多,脚本可重复,适合科研场景。
根据常见R语法,数值、向量、因子等对象都可以直接参与后续统计分析。尤其是分类变量转成因子后,分组信息更清晰,方便接入方差检验函数。
对医学生、医生和科研人员来说,R的价值在于:一次写好代码,后续可以反复用于不同数据。
2. 方差齐性检验R语言代码的基础准备
2.1 数据格式先整理好
做方差齐性检验前,通常至少要有两列数据。
- 一列是分组变量,例如
group - 一列是连续变量,例如
value
如果分组变量是字符型,建议先转成因子。这样更符合统计分析的习惯,也便于后续调用函数。
group.f <- as.factor(group)
如果分组有顺序,比如低、中、高,也可以设为有序因子。不同类型变量在R里有不同语义,这一点很重要。
2.2 先看数据类型,再写代码
在R里,类型不对,很多函数会直接报错。比如字符串不能直接做数值运算。做检验前,建议先检查:
class(group)
class(value)
如果 value 不是数值型,先转换。若源数据本来就是数字,只是被读成了字符,可以用:
value <- as.numeric(value)
这一步看似简单,但能避免大量“结果不对”的隐性错误。
3. 常见的方差齐性检验R语言代码
3.1 先用基础思路理解方差比较
R基础语法里,向量、因子、逻辑判断都很常用。方差齐性检验本质上也是对分组数据做统计比较。
如果你已经把分组变量和连续变量整理好了,就可以进入具体函数。不同函数适合不同场景,但核心流程类似:
- 准备数据
- 按组比较方差
- 根据P值判断是否拒绝原假设
原假设通常是:各组方差相等。
3.2 代码示例一:用Bartlett检验
Bartlett检验是经典的方差齐性检验方法,适合数据接近正态分布的情况。
bartlett.test(value ~ group.f, data = mydata)
这里:
value是连续变量group.f是分组因子mydata是数据框
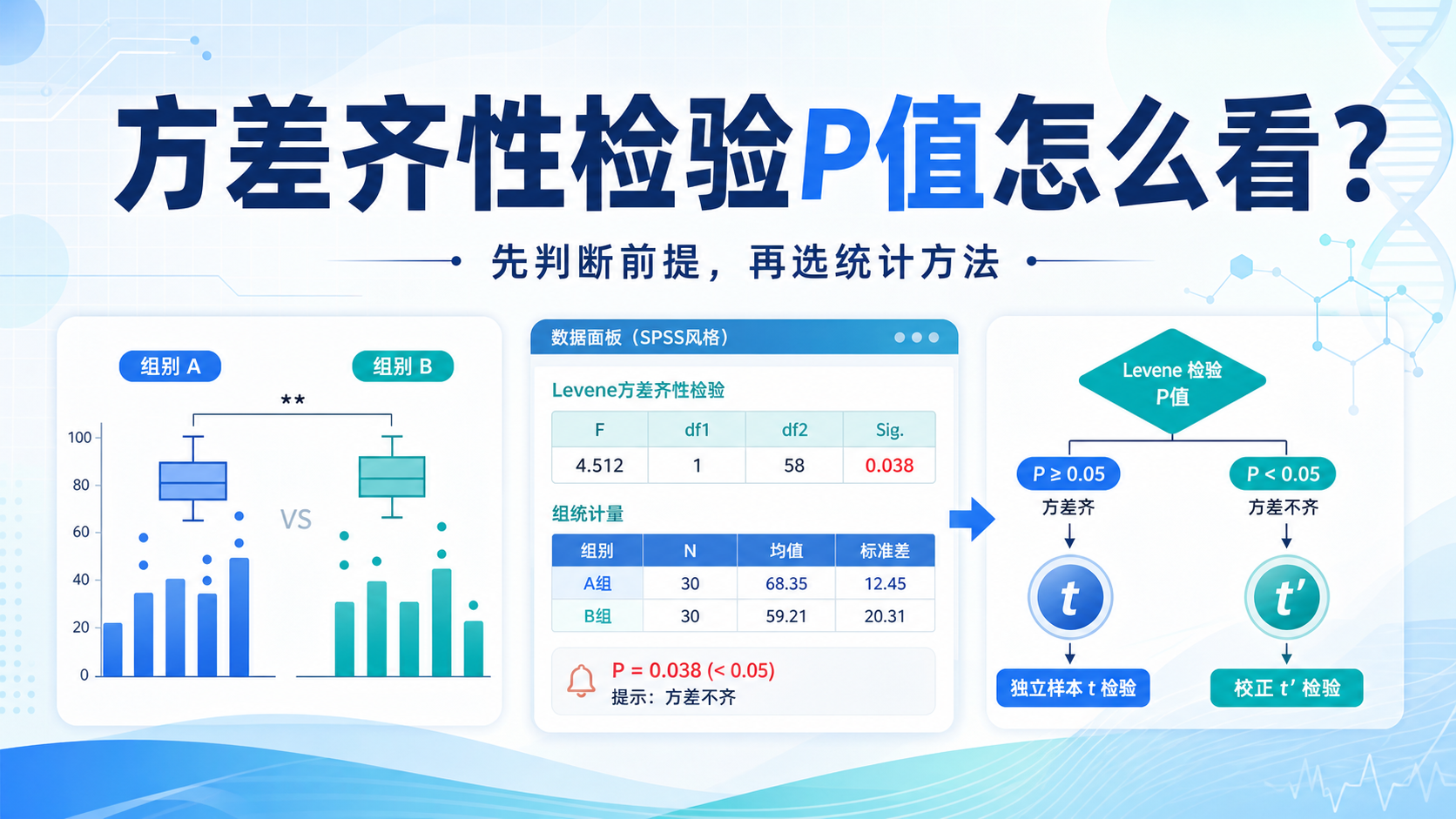
结果中最关键的是 p-value。如果 p < 0.05,通常认为方差不齐;如果 p >= 0.05,则可认为方差齐。
Bartlett检验对正态性较敏感。若数据偏离正态较明显,要谨慎解释。
3.3 代码示例二:用Fligner-Killeen检验
如果数据不太符合正态分布,可以考虑更稳健的方法。Fligner-Killeen检验常用于方差齐性判断,对分布要求相对宽松。
fligner.test(value ~ group.f, data = mydata)
它的写法和 Bartlett 很像,适合快速替换比较。
在实际科研中,如果你不确定数据分布是否理想,Fligner-Killeen检验通常更稳妥。
3.4 代码示例三:先自己算方差再查看
如果你想先看每组方差差异,也可以直接计算:
tapply(mydata$value, mydata$group.f, var)
这个结果能直观显示每组方差。虽然它不是正式检验,但很适合预览数据。
你还可以进一步看每组均值和标准差,帮助判断数据波动是否明显不同。
tapply(mydata$value, mydata$group.f, sd)
正式检验和描述性统计最好结合看,结论会更完整。
4. 方差齐性检验结果怎么解读
4.1 重点看P值,不要只看检验名称
很多初学者会把注意力放在函数名上,而忽略P值。其实判断依据很简单。
p < 0.05,拒绝原假设,认为方差不齐p >= 0.05,不能拒绝原假设,可认为方差齐
但这里要注意,“不能拒绝原假设”不等于“证明完全相等” 。它只是说明当前数据下,没有足够证据表明方差不同。
4.2 结果要和后续统计方法联动
如果方差齐性成立,很多常规参数检验可以继续使用。
如果方差不齐,就要考虑:
- 使用Welch校正
- 选择非参数检验
- 对数据做适当变换
- 采用更适合的模型方法
方差齐性检验不是终点,而是决定后续统计路径的分岔口。
5. 在R里快速写出可复用代码
5.1 最小可用代码模板
如果你想快速实现,下面这个模板最实用:
mydata$group.f <- as.factor(mydata$group)
bartlett.test(value ~ group.f, data = mydata)
fligner.test(value ~ group.f, data = mydata)
先把分组变量转成因子,再分别做两种检验。这样你可以在同一份数据上比较不同方法的结果。
5.2 结合数据检查一起写
更稳妥的写法,是先检查类型,再做检验:
class(mydata$group)
class(mydata$value)
mydata$group.f <- as.factor(mydata$group)
mydata$value <- as.numeric(mydata$value)
tapply(mydata$value, mydata$group.f, var)
bartlett.test(value ~ group.f, data = mydata)
这类流程化代码最适合科研脚本。可重复,也便于审稿时说明分析步骤。
5.3 适合初学者的操作建议
如果你刚开始学R,可以记住这个顺序:
- 导入数据
- 确认变量类型
- 将分组变量转为因子
- 看各组方差
- 再做正式检验
这个顺序和R语言的基础语法一致。先理解对象类型,再做统计分析,效率会高很多。
6. 常见错误与处理思路
6.1 变量类型不对
最常见的问题是把字符型数值直接拿去检验。这样要么报错,要么结果无意义。
处理方法很直接:
mydata$value <- as.numeric(mydata$value)
如果转换后出现 NA,说明原始数据可能夹杂了非数字字符,需要先清洗。
6.2 分组变量没有转成因子
如果分组变量还是字符型,函数有时也能跑,但不够规范。建议直接转因子。
mydata$group.f <- factor(mydata$group)
科研代码里,规范的数据类型会显著减少后期返工。
6.3 样本量太小或组间极不平衡
方差齐性检验也受样本结构影响。组内样本过少时,结果稳定性会下降。
因此,解释P值时要结合样本量、分布形态和研究设计一起看。
总结Conclusion
方差齐性检验是统计分析里非常基础,但也非常关键的一步。你只要记住:先整理变量类型,再用R语言代码做检验,最后结合P值和数据分布判断 ,就能快速完成大多数科研场景下的分析。
如果你想把这些步骤做成更规范的科研脚本,建议直接使用解螺旋 的R语言学习与科研工具内容。它能帮助你把数据整理、函数调用和结果解读串成完整流程,减少重复试错,提高分析效率。
- 引言Introduction
- 1. 什么是方差齐性检验
- 2. 方差齐性检验R语言代码的基础准备
- 3. 常见的方差齐性检验R语言代码
- 4. 方差齐性检验结果怎么解读
- 5. 在R里快速写出可复用代码
- 6. 常见错误与处理思路
- 总结Conclusion