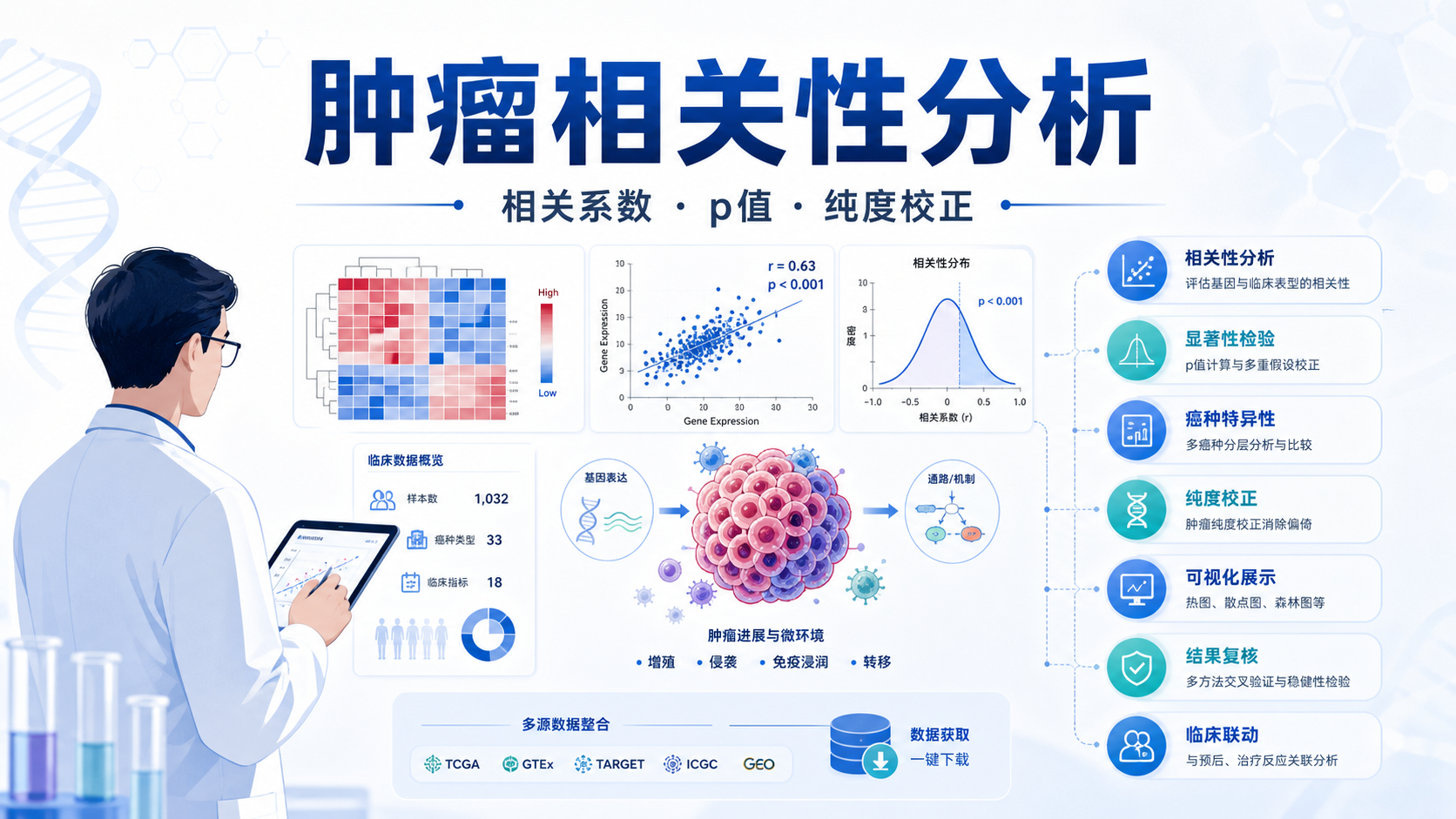
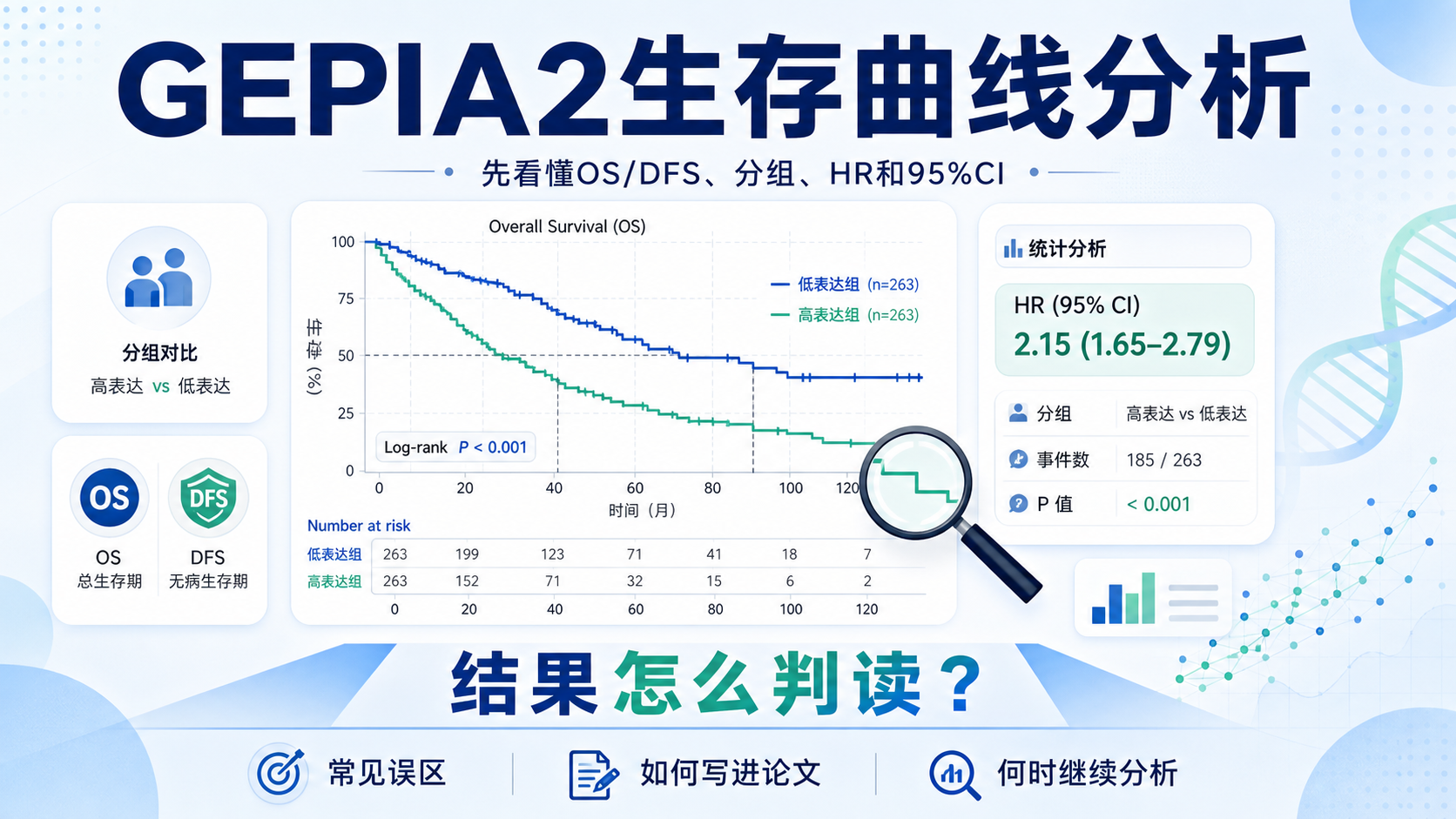
引言Introduction
UALCAN甲基化分析 是肿瘤研究里很实用的一步。很多基因在表达上异常,但原因不一定来自突变。启动子甲基化常常是更早、更稳定的调控层。对医学生、医生和科研人员来说,关键问题不是“能不能查”,而是“为什么要查,查什么,怎么解读”。
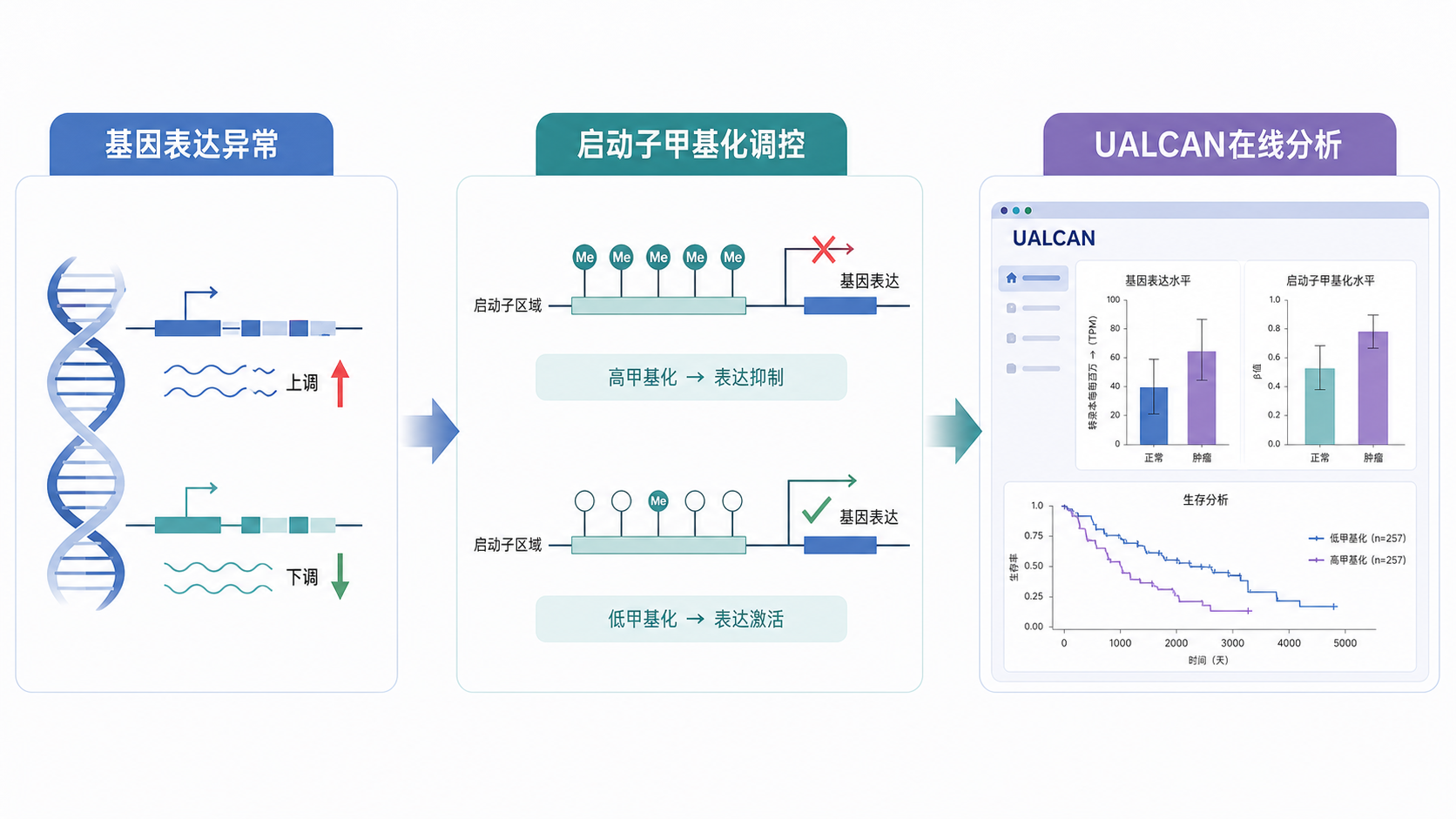
1. UALCAN甲基化分析到底解决什么问题
1.1 从“表达异常”追到“表观遗传原因”
UALCAN甲基化分析的核心价值,是帮助研究者从表达现象回溯到甲基化机制。很多肿瘤中,基因表达下降并不等于基因突变失活。启动子区,尤其是TSS附近CpG岛高甲基化,常与转录沉默相关。
这意味着,你看到的低表达,可能是甲基化在上游“关灯”。
在机制研究中,这一步很重要。它能把“相关性”往“调控关系”推进。对后续设计验证实验也有指导意义,比如 bisulfite 测序、甲基化特异性PCR,或者结合ChIP、luciferase进一步做机制闭环。
1.2 适合哪些研究场景
UALCAN甲基化分析适合做以下几类问题:
- 候选抑癌基因是否存在启动子高甲基化。
- 某个基因在不同肿瘤分期、亚型中的甲基化差异。
- 甲基化变化是否与表达变化一致。
- 甲基化是否可能影响患者预后。
如果你的课题目标是筛选肿瘤标志物,UALCAN甲基化分析可以作为第一轮快速筛查工具。 它不是终点,但很适合作为起点。
2. 为什么优先考虑UALCAN甲基化分析
2.1 数据来源更接近真实肿瘤队列
UALCAN提供公开癌症OMICS数据分析,覆盖TCGA、MET500、CPTAC、CBTTC等资源。对甲基化研究而言,TCGA是最常用的数据入口之一。
它的优势在于,数据来自真实患者样本,不是单一细胞系推断。对于临床相关性判断,这一点很重要。
此外,UALCAN不仅能看甲基化,还能联动表达、生存、泛癌和临床分层信息。这使甲基化结果不再是孤立图表,而是可放入同一分析框架中解释。
2.2 对新手更友好,适合快速定位候选基因
相较于自行下载TCGA原始数据、清洗矩阵、做批次校正,UALCAN甲基化分析的门槛更低。
你只需要明确:
- 目标癌种。
- 候选基因。
- 想看的是总体差异,还是分期差异,还是与预后的关联。
对于研究初期,先用UALCAN甲基化分析确认“这个基因是否值得继续做” ,效率通常更高。尤其在课题筛选阶段,它能显著减少无效验证。
3. UALCAN甲基化分析怎么读结果
3.1 先看甲基化是否真的异常
做UALCAN甲基化分析时,第一步不是急着下结论,而是看差异是否清晰。
如果肿瘤组与正常组之间存在稳定差异,才说明这个基因有继续挖掘价值。常见情况包括:
- 肿瘤组甲基化升高,提示可能抑制表达。
- 肿瘤组甲基化降低,提示可能解除沉默或伴随基因组不稳定。
- 分期越高,甲基化变化越明显,提示可能与进展相关。
注意,甲基化变化不等于功能改变。 还要结合表达数据一起看。甲基化高、表达低,这种方向一致的结果更有机制意义。
3.2 结合生存信息判断临床意义
UALCAN的另一个重要价值,是可以把甲基化结果放进临床语境。
如果某个基因在肿瘤中高甲基化,并且伴随低表达,同时与较差生存相关,这个候选基因的优先级就会明显提高。
这类结果更适合写进文章的“临床相关性”部分。对后续投稿来说,“有差异”不够,“和预后有关”更有说服力。
当然,生存结果仍需结合独立队列验证,不能仅凭一个数据库直接定论。
4. UALCAN甲基化分析与其他数据库的配合方式
4.1 先用UALCAN筛,再用GEPIA2和KM Plotter补强
在预后和表达联动分析里,UALCAN甲基化分析更像入口。
常见的合理路径是:
- 用UALCAN看甲基化差异。
- 用GEPIA2看表达和生存关联。
- 用KM Plotter进一步验证单基因或多基因预后效应。
这种组合能避免只看单一维度。 因为肿瘤分子机制往往不是单点决定,而是表达、甲基化和临床结局共同作用。
4.2 适合和机制实验形成闭环
UALCAN甲基化分析本身属于计算机模拟验证。真正有价值的是,它能指导后续实验。
如果你在UALCAN里发现某基因启动子高甲基化,并且表达下调,那么下一步可以考虑:
- 设计甲基化位点验证。
- 做qPCR确认表达差异。
- 结合干预实验观察表达是否可逆。
- 再看下游通路是否恢复。
这就是从数据库发现问题,到实验室验证机制的标准路径。
5. 做UALCAN甲基化分析时要注意什么
5.1 不要只看“显著性”
数据库分析常见误区,是只盯着P值。
但对于UALCAN甲基化分析,更重要的是效应方向和生物学合理性。
需要同时判断:
- 甲基化差异是否足够稳定。
- 方向是否符合基因功能预期。
- 是否与表达数据一致。
- 是否能对应到已知的启动子调控逻辑。
统计显著,不代表生物学上一定有意义。
5.2 结果需要二次验证
UALCAN甲基化分析适合发现线索,不适合直接作为最终结论。
原因很简单,数据库分析受样本构成、平台差异、亚型分布等因素影响。
因此,严谨的写法应该是:
- 先报告UALCAN中的差异趋势。
- 再结合独立数据库和文献。
- 最后用实验验证。
这也是符合 E-E-A-T 的写作和研究逻辑。证据链越完整,结论越稳。
6. 为什么很多课题最后还是离不开UALCAN甲基化分析
6.1 它能快速提高选题命中率
对课题设计来说,时间最贵。
UALCAN甲基化分析的价值在于,它可以帮助你快速判断一个基因有没有“故事”。
如果一个基因在肿瘤中既有甲基化异常,又能解释表达变化,还可能关联预后,那么它就更值得投入实验资源。
这比盲目筛很多基因更节省时间,也更节省经费。
6.2 它适合写进论文的结果链条
在论文结构里,UALCAN甲基化分析常用于以下位置:
- 候选基因筛选。
- 机制线索提出。
- 临床相关性补充。
- 预后价值初筛。
如果你想让文章更完整,通常需要把甲基化、表达和生存连起来。UALCAN正好能提供这条链条中的关键一环。
总结Conclusion
为什么做UALCAN甲基化分析?因为它能把“基因异常”拆解成更可解释的表观遗传机制。 对肿瘤研究者来说,它适合用于候选基因筛选、临床相关性判断和后续实验设计。
如果你正在做 TCGA 相关分析,或想把甲基化结果真正转化为可发表、可验证的课题线索,建议把 UALCAN 作为第一步入口。再结合解螺旋品牌的课程与工具支持,可以更高效地完成从数据库挖掘到机制验证的完整路径。
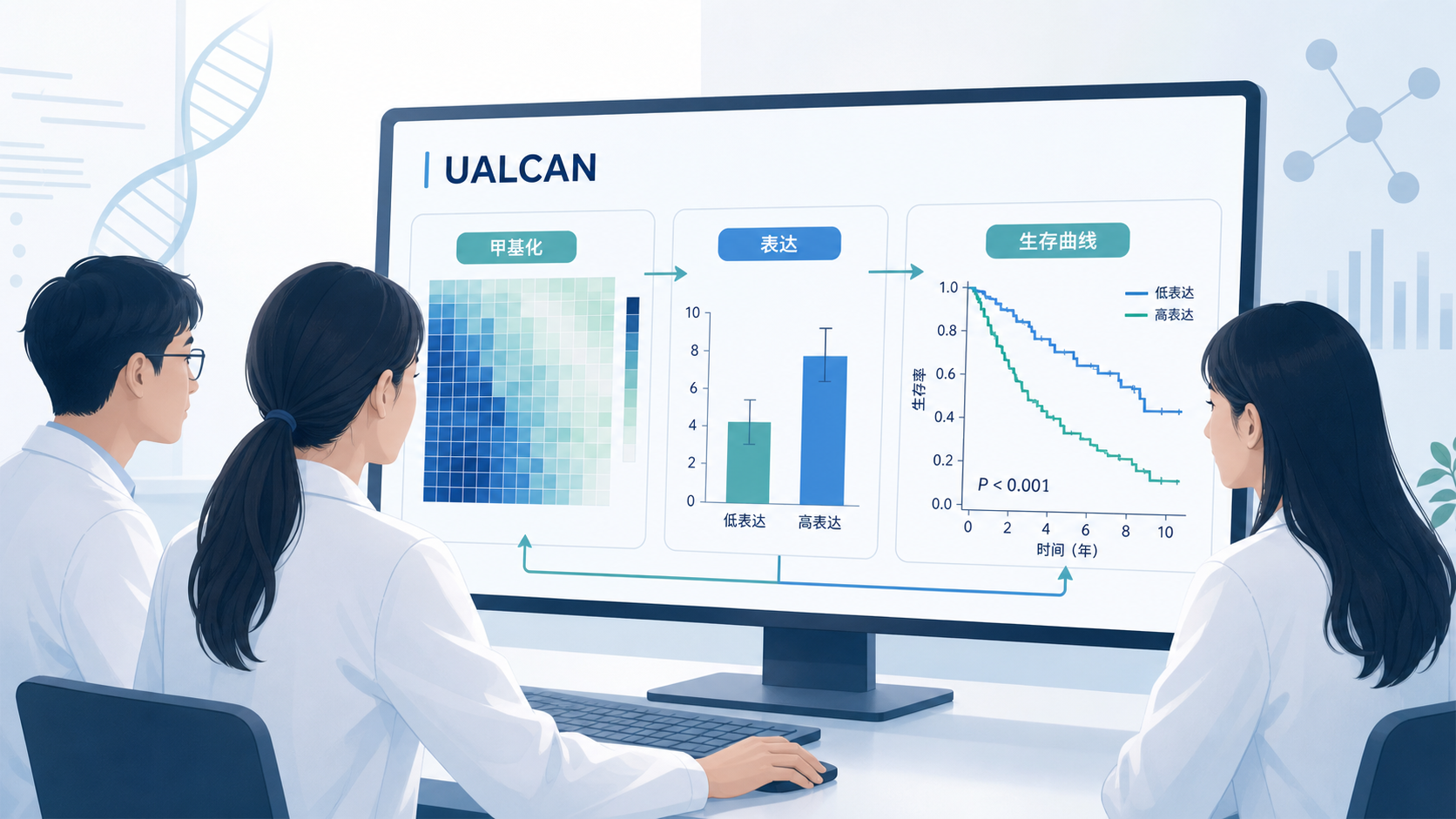
- 引言Introduction
- 1. UALCAN甲基化分析到底解决什么问题
- 2. 为什么优先考虑UALCAN甲基化分析
- 3. UALCAN甲基化分析怎么读结果
- 4. UALCAN甲基化分析与其他数据库的配合方式
- 5. 做UALCAN甲基化分析时要注意什么
- 6. 为什么很多课题最后还是离不开UALCAN甲基化分析
- 总结Conclusion