






引言Introduction
皮肤专科研究常见痛点是,样本分散、疾病亚型复杂、公共数据难复用,导致选题慢、验证贵、发文难。皮肤专科生信数据库 把疾病、临床变量和多组学数据整合到同一框架里,能明显提升选题效率和研究深度。
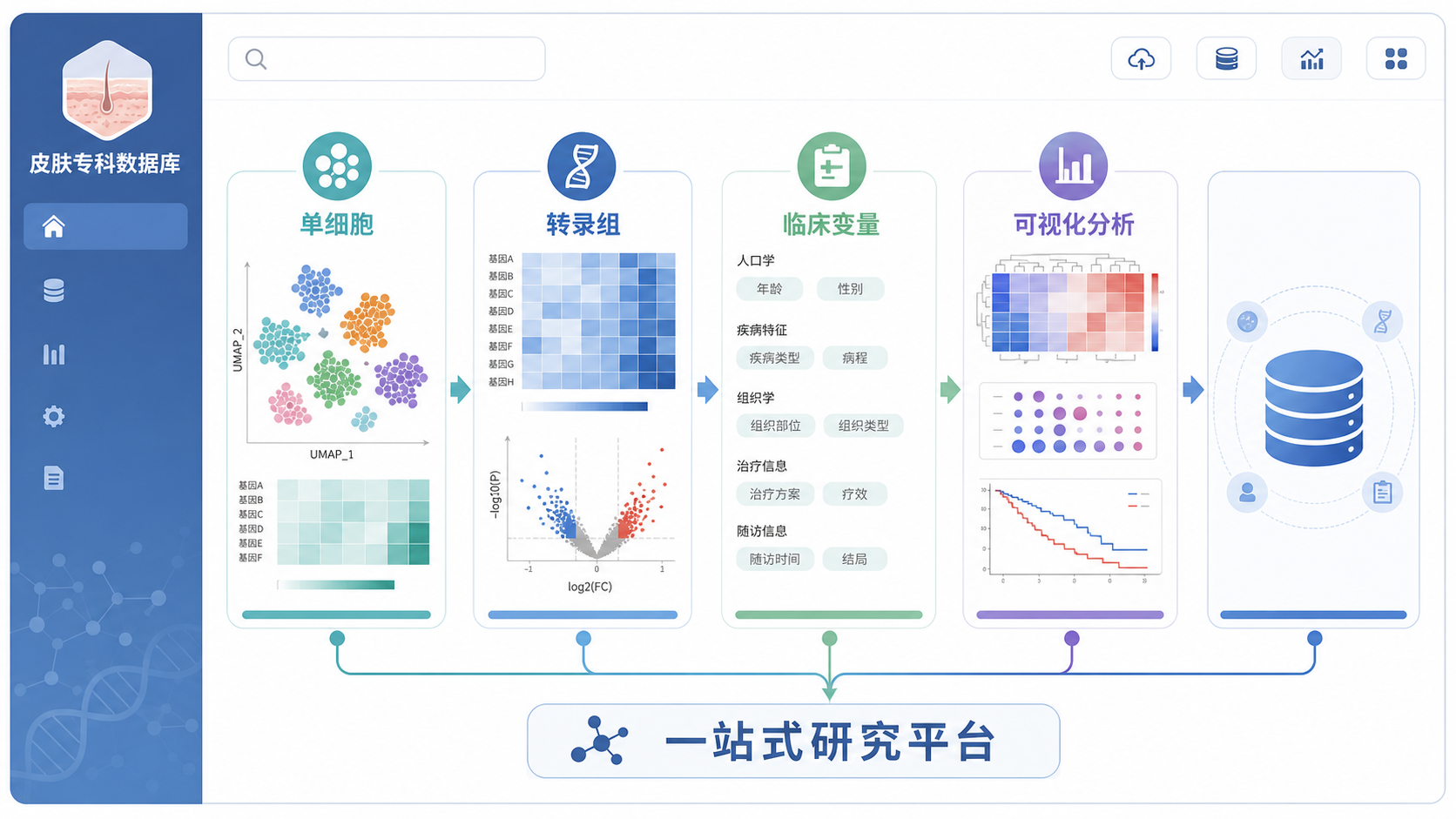
1. 皮肤专科生信数据库的核心价值:把“找数据”变成“找答案”
1.1 从零散公开数据到可直接分析的研究入口
皮肤病研究经常面临一个现实问题。疾病分型多,病例来源散,单中心样本量有限。很多课题卡在数据收集阶段。皮肤专科生信数据库的第一层优势,就是把分散的公共数据整理成可直接进入分析的入口。
知识库中提到,纯公共数据挖掘已经可以支持高质量文章。关键不只是“有数据”,而是“数据是否被整理好,能否快速形成研究链条”。对于皮肤领域来说,这一点尤其重要。因为皮肤病既有炎症性疾病,也有肿瘤、感染、免疫异常和遗传相关疾病,适合做数据库整合分析。
1.2 支持从疾病到机制的连续分析
一个成熟的皮肤专科生信数据库 ,不只是数据仓库,更是分析平台。它可以把疾病分组、差异表达、功能富集、免疫浸润、关键基因筛选、预后分析串联起来。
这类连续分析的价值在于,研究者不必每次都重新清洗和拼接数据。 这样能显著缩短从选题到成图的周期。
知识库还提示,单细胞转录组、空间转录组、多组学联合分析已经成为热门方向。对于皮肤这种组织结构复杂、细胞异质性强的领域,单细胞和空间信息尤其有价值。它能帮助研究者把“一个病”拆成“多个细胞亚群和空间微环境问题”来研究。
2. 皮肤专科生信数据库的3个关键优势
2.1 优势一,提升选题效率,降低重复风险
皮肤科研最怕两件事。第一,选题撞车。第二,数据不够新。知识库中反复强调,好的数据库能把公开数据转化为新的问题 。比如从疾病亚型、左右位置、年龄分层、性别差异、预后分层等切入,都可能形成新故事。
这对医学生和青年医生很关键。因为临床工作繁忙,最缺的是高效率选题工具。一个完善的皮肤专科生信数据库,可以帮助研究者先看文献,再看可用数据,再定问题。这样就能减少无效重复,避免在同一方向上反复试错。
2.2 优势二,增强分析深度,适合做多组学和单细胞
知识库显示,单细胞分析应用非常广泛,且已与多组学联合分析一起形成高热度方向。对于皮肤病而言,这种优势更明显。皮肤组织本身包含角质形成细胞、成纤维细胞、免疫细胞、血管相关细胞等多类细胞。只看整体表达,往往会丢失关键信号。
皮肤专科生信数据库如果支持单细胞、空间转录组、转录组和临床信息联动,就能让研究从“基因是否变化”进一步走向“哪类细胞在变化、变化发生在哪里、与临床结局是否相关”。
这类分析通常包括:
- 细胞亚群重注释。
- 差异基因筛选。
- 细胞通讯分析。
- GSEA或GSVA功能富集。
- WGCNA筛选关键模块。
- 预后或临床相关性验证。
这类链条化分析,正是高水平皮肤生信研究的基础。
2.3 优势三,减少实验依赖,提高发文与转化效率
知识库明确指出,数据库类研究的突出特点之一是,很多工作可以不依赖额外分子实验验证。对于预算有限、样本有限的皮肤专科团队,这一点非常现实。
数据库先筛选,再决定是否做实验,是更高效的研究路径。
比如在皮肤炎症或皮肤肿瘤研究中,先用数据库锁定候选基因和关键通路,再做少量验证,通常比直接铺开实验更稳妥。这样既能控制成本,也能缩短周期。
从研究转化角度看,数据库还能进一步升级为在线分析工具或Shiny应用。知识库提到,数据库不仅能支持文章输出,还能成为同行复用的研究工具。一旦数据库被持续使用,引用率和学术可见度也会随之提升。
3. 皮肤专科生信数据库适合哪些研究场景
3.1 炎症性皮肤病
银屑病、特应性皮炎、湿疹样疾病等,都很适合用数据库做公共数据挖掘。原因很简单。它们常有明确的分组信息,也常涉及免疫细胞、炎症通路和皮肤屏障变化。
在这种场景下,皮肤专科生信数据库 可以帮助研究者快速完成差异分析、免疫相关分析和通路富集分析。
3.2 皮肤肿瘤与癌前病变
知识库中提到,单细胞、泛癌分析、多组学联合是当前高热度方向。皮肤肿瘤也同样适用。
如果数据库能整合临床结局、分子分型和公共队列,就可以支持预后分析、风险评分模型和验证集分析。对于需要快速形成SCI论文的团队,这类框架非常实用。
3.3 罕见病和难收样本疾病
皮肤专科还有一个现实难点。部分疾病样本非常少,单中心很难积累到足够规模。此时,数据库的价值更高。
当实验样本不足时,公共数据库就是最现实的研究突破口。 它能帮助研究者先完成假设生成,再考虑后续验证。知识库中提到的多数据库联合、最新更新数据、个性化定制,正说明数据库方法的灵活性。
4. 研究者如何真正用好皮肤专科生信数据库
4.1 先明确问题,再选数据
不要一上来就做大而全的分析。建议按以下顺序推进:
- 明确疾病亚型。
- 明确结局变量。
- 明确可用公开队列。
- 再决定做转录组、单细胞还是多组学。
- 最后补充功能验证路径。
先问题,后数据,最后方法。 这是避免研究发散的关键。
4.2 把分析流程标准化
一篇高质量数据库文章,通常离不开标准化流程。知识库中提到的常见模块包括:
- 数据纳入与排除。
- 差异表达分析。
- 细胞亚群注释。
- 火山图、热图和相关性分析。
- WGCNA或机器学习筛选。
- 预后模型与外部验证。
- DCA和ROC评估。
如果这些步骤能在皮肤专科生信数据库中被规范集成,研究者的效率会明显提升。
标准化越强,复现性越好,文章质量也越稳定。
总结Conclusion
皮肤研究进入数据驱动时代后,真正稀缺的不再只是样本,而是高质量、可复用、可扩展的分析平台。皮肤专科生信数据库的3个关键优势,分别是提升选题效率、增强分析深度、减少实验依赖。 对医学生、医生和科研人员来说,这意味着更快找到问题,更稳完成分析,更高效产出成果。
如果你正在做皮肤相关课题,或者想把公共数据做成可发表、可转化的研究工具,可以优先考虑借助解螺旋品牌的定制化生信数据库方案 。它更适合把疾病数据、单细胞、多组学和临床分析整合到一个清晰框架里,帮助你更快完成高质量选题与成果输出。
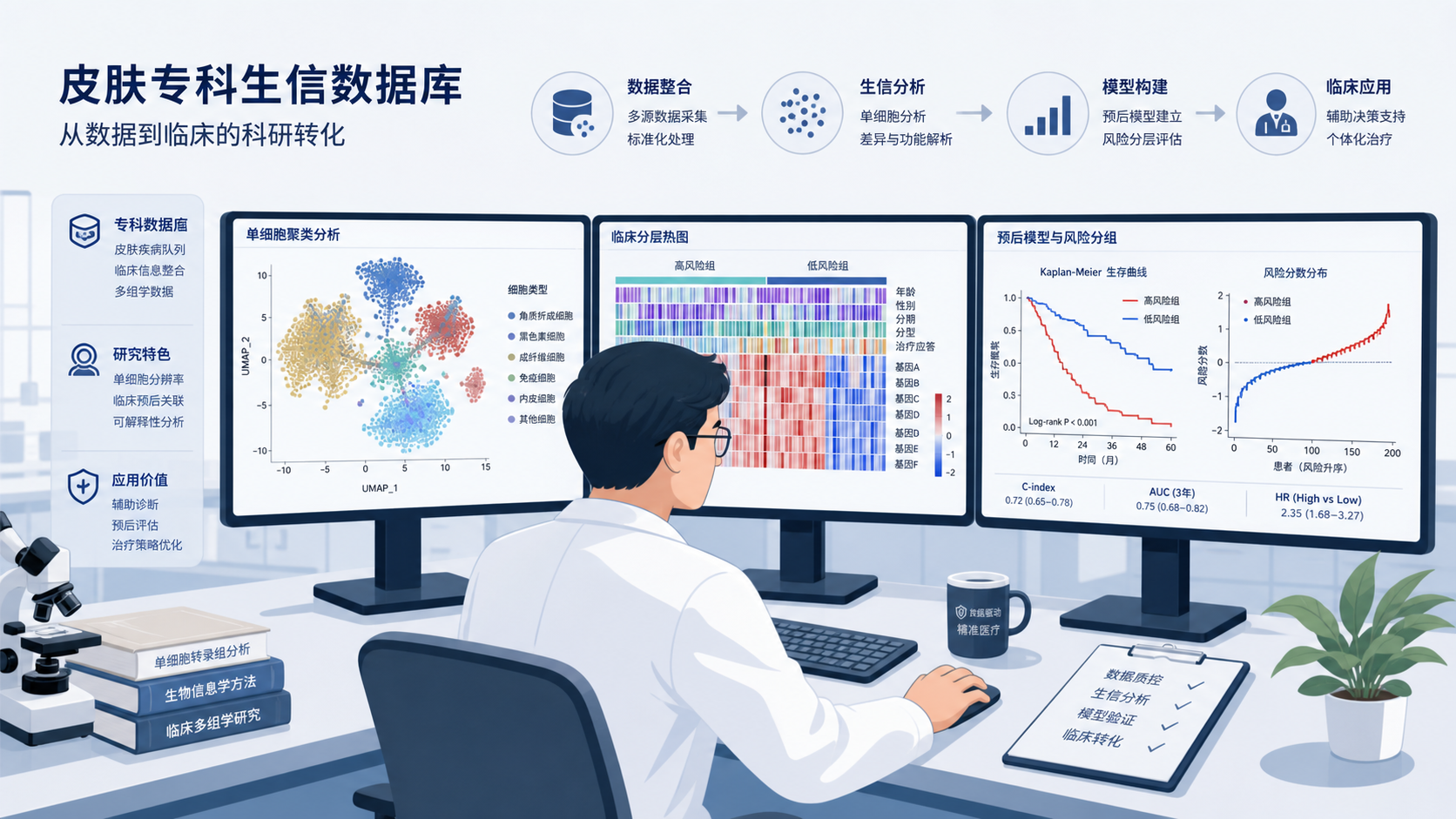
- 引言Introduction
- 1. 皮肤专科生信数据库的核心价值:把“找数据”变成“找答案”
- 2. 皮肤专科生信数据库的3个关键优势
- 3. 皮肤专科生信数据库适合哪些研究场景
- 4. 研究者如何真正用好皮肤专科生信数据库
- 总结Conclusion



