






引言Introduction
RNA 的功能不只取决于“是什么”,还取决于“在哪里”。对医学生、医生和科研人员来说,亚细胞定位数据库 能帮助快速判断 RNA 更可能参与储存、加工、翻译还是降解,从而减少盲目实验。
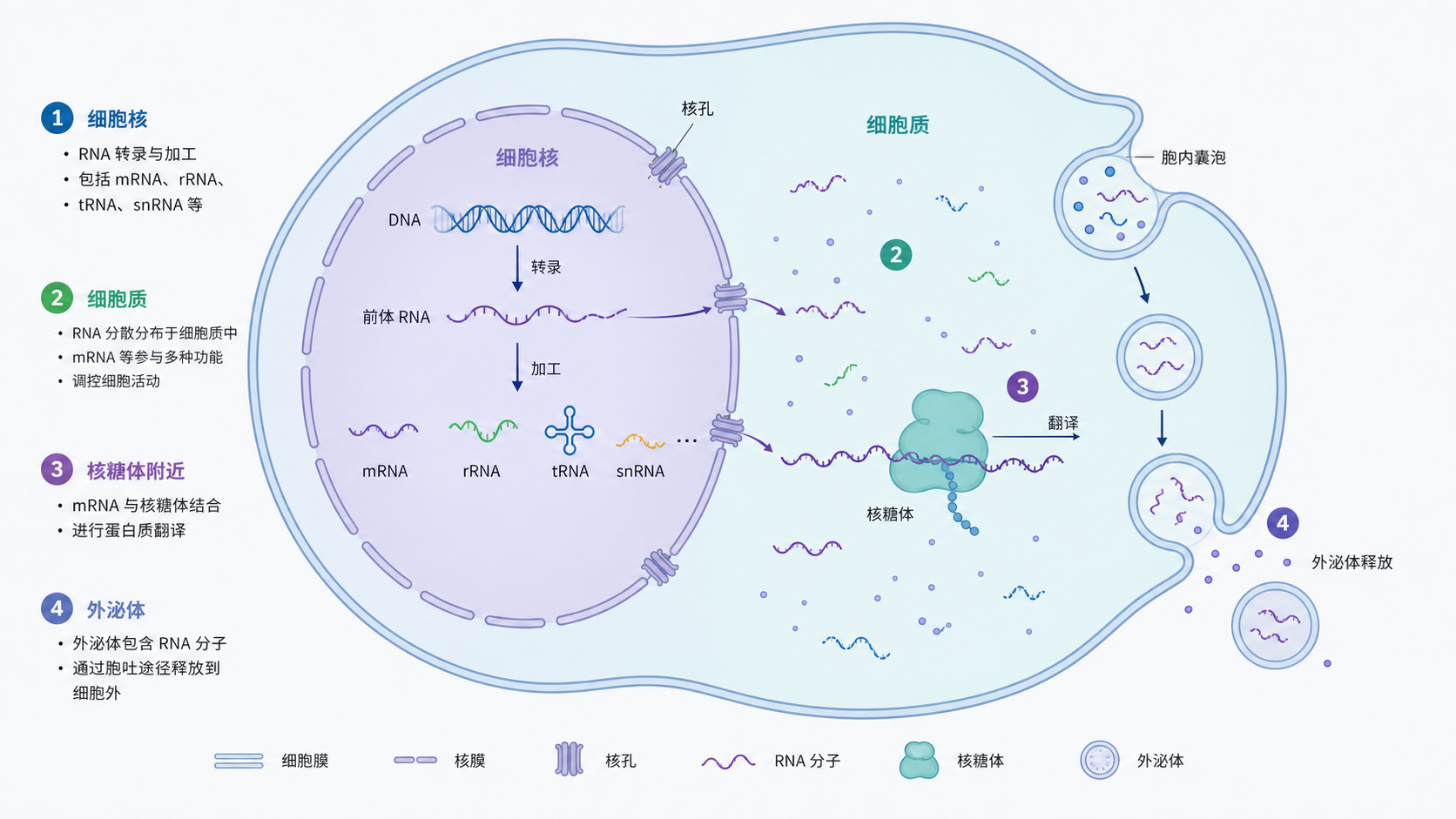
1. 为什么亚细胞定位数据库值得优先使用
1.1 先看定位,再谈功能
RNA 的亚细胞位置,常常直接影响其生物学命运。它位于细胞核,可能更偏向转录后调控。它位于细胞质,可能更接近翻译过程。它出现在特定区室,还可能提示疾病相关机制。
这也是亚细胞定位数据库最核心的价值。 它把“位置”变成可检索、可比较、可追溯的证据。
1.2 解决的是实验前的关键问题
在实际研究中,研究者常会先问三个问题。
- 这个 RNA 是否有已知定位证据。
- 这个定位证据来自实验还是预测。
- 不同组织、细胞系或物种中的定位是否一致。
亚细胞定位数据库能在正式做实验前,先完成证据筛查和方向判断。 这对课题设计、靶点筛选和机制假设都很重要。
1.3 适合多层次研究场景
这类数据库不仅适合基础研究,也适合转化研究。
- 研究 lncRNA 机制时,可先查定位是否支持核内调控。
- 做疾病关联分析时,可结合定位与疾病注释。
- 做方法学研究时,可直接使用数据库构建训练集或验证集。
因此,亚细胞定位数据库并不是单一查询工具,而是研究路线的入口。
2. 核心优势一:数据来源更全面,且强调实验依据
2.1 实验注释是最大的信任基础
以 RNALocate 为例,数据库整合了文献检索、数据库整合和 RNA-seq 数据集筛选,收录了超过二十万个具有实验证据的 RNA 亚细胞定位条目 ,覆盖104 个物种、171 个亚细胞定位、十万余种 RNA 。
这意味着它不是只给出一个预测结果,而是提供可追溯的实验背景。
2.2 更新频率决定时效性
RNALocate 自 2015 年首次发布后持续更新,2021 年升级到 2.0 版本,纳入了更多新技术带来的证据,例如 RNA-seq、MERFISH 等。
对于科研人员来说,数据库是否更新,直接影响结果是否还能代表当前研究进展。
2.3 细节注释有助于复核
这类数据库通常还会提供实验方法、对应图、RNA 同源信息、RNA 相互作用、RNA 相关疾病等条目。部分 RNA-seq 数据集还包含 GO 富集分析。
这让研究者可以从“看见结果”进一步走向“验证来源”。
3. 核心优势二:覆盖多物种、多定位和多RNA类型
3.1 适用范围广
RNALocate 涵盖 mRNA、lncRNA 等多类 RNA。Annolnc2 则聚焦人和小鼠 lncRNA,整合序列、结构、表达、调控、基因关联和演化等多维注释。
覆盖面越广,越适合做跨物种比较和机制推断。
3.2 定位维度更细
亚细胞定位并不只是“核”与“质”的二分法。实际研究中,核糖体、外泌体等区室同样重要。iLoc-LncRNA 的预测结果就展示了细胞核、细胞质、核糖体和外泌体等定位信息。
这类细分维度有助于提高定位解释的准确度。
3.3 支持组织或细胞系差异
lncRNA 的定位常具有组织特异性。更新后的 lnclocator 就构建了15 个细胞系的 lncRNA 亚细胞定位基准数据集 ,并以转录本级数据训练模型。
这比把所有数据混合训练更符合真实生物学场景。
4. 核心优势三:兼具“查询”和“预测”双重能力
4.1 查询功能适合已有目标
RNALocate 提供精确检索、模糊检索和批量检索。研究者可输入 RNA symbol 或 ID,按物种、定位类型和 RNA 类型筛选。
这对已知靶点的快速核实非常高效。
4.2 预测功能适合新序列
RNALocate v2.0 还整合了 DM3Loc、iLoc-lncRNA 和 iLoc-mRNA,用于预测 lncRNA 或 mRNA 的亚细胞定位。
lnclocator 也支持输入转录本序列或 FASTA 文件,在指定细胞系中进行预测。
对于新发现的序列,预测功能可以先给出方向,再决定后续实验设计。
4.3 两类功能互为补充
查询依赖已有证据,预测依赖模型学习。前者强调事实,后者强调推断。
真正有价值的亚细胞定位数据库,通常是“证据型资源”和“预测型工具”的结合。
5. 核心优势四:能提高研究效率和课题质量
5.1 减少重复劳动
如果一个 RNA 已经有明确的亚细胞定位证据,研究者就不必从零开始重复筛查。
这能节省实验时间,也能避免将资源消耗在低优先级候选上。
5.2 帮助构建更合理的假设
比如某个 lncRNA 明显定位于细胞核,那么它更可能参与转录调控、染色质调控或核内复合物形成。
如果它主要位于细胞质,则可优先考虑转录后调控、miRNA 海绵或翻译调节。
定位信息本质上是在帮你缩小机制范围。
5.3 为后续分析提供起点
Annolnc2 这类一站式注释平台,还能进一步联通表达、结构、互作、调控和演化信息。
研究者可以从亚细胞定位出发,继续延伸到:
- 差异表达分析
- RBP 互作分析
- GO 富集分析
- 疾病关联分析
这让数据库不只是“查结果”,而是“搭框架”。
6. 核心优势五:对方法学研究和模型验证很友好
6.1 可作为基准数据集
iLoc-LncRNA 等预测工具,基于高质量基准数据集开发,并在严格交叉验证中实现了86.72% 的最大总体准确率 。
这说明亚细胞定位数据库不仅服务于单个课题,也能支撑算法开发和模型评估。
6.2 便于交叉验证
科研中最怕单一来源偏差。数据库提供的实验注释、预测结果和多工具比对,能帮助研究者进行交叉验证。
当不同资源给出一致结论时,结果可信度通常更高。
6.3 有利于论文设计
对于想做生信分析的研究者,亚细胞定位数据库可直接成为选题入口。
常见思路包括:
- 已知疾病相关 lncRNA 的定位归纳
- 某类 RNA 的核/质分布差异
- 多数据库联合注释
- 预测结果与实验结果一致性分析
7. 如何高效使用这类数据库
7.1 先明确研究对象
先确定是 mRNA、lncRNA,还是更广义的 RNA。
再确定是否关注特定物种、细胞系或疾病场景。
目标越明确,检索效率越高。
7.2 先查证据,再看预测
推荐顺序是:
- 先在 RNALocate、Annolnc2 等资源中查已知定位。
- 再用 lnclocator 或 iLoc-LncRNA 做补充预测。
- 最后结合实验设计验证。
7.3 注意区分定位与功能推断
定位只能提示可能的作用场景,不能直接等同于功能。
研究者仍需结合表达、互作、结构和实验验证来完成机制闭环。
这是使用亚细胞定位数据库时必须保持的科学边界。
总结Conclusion
亚细胞定位数据库的核心优势,可以概括为四点。数据更全,证据更强,功能更实用,研究效率更高。 它不仅帮助我们快速判断 RNA 在哪里,更帮助我们判断下一步该怎么做。
对医学生、医生和科研人员来说,这类数据库是连接基础机制和研究设计的重要工具。
如果你希望把定位查询、序列预测和多维注释整合到同一条研究路径中,可以借助解螺旋品牌提供的数据库整合与分析支持 ,更高效地完成从问题发现到课题设计的转化。

- 引言Introduction
- 1. 为什么亚细胞定位数据库值得优先使用
- 2. 核心优势一:数据来源更全面,且强调实验依据
- 3. 核心优势二:覆盖多物种、多定位和多RNA类型
- 4. 核心优势三:兼具“查询”和“预测”双重能力
- 5. 核心优势四:能提高研究效率和课题质量
- 6. 核心优势五:对方法学研究和模型验证很友好
- 7. 如何高效使用这类数据库
- 总结Conclusion



