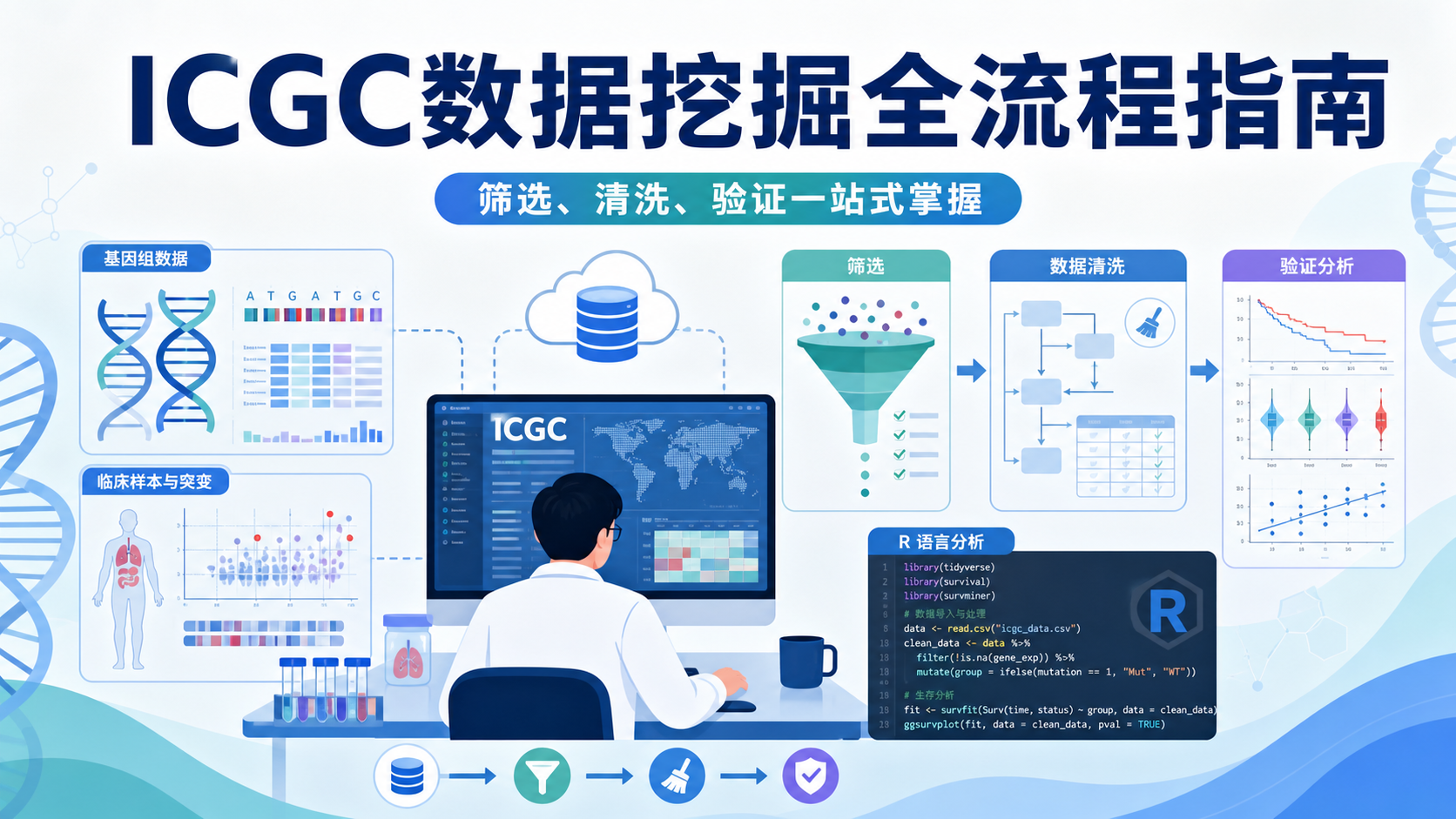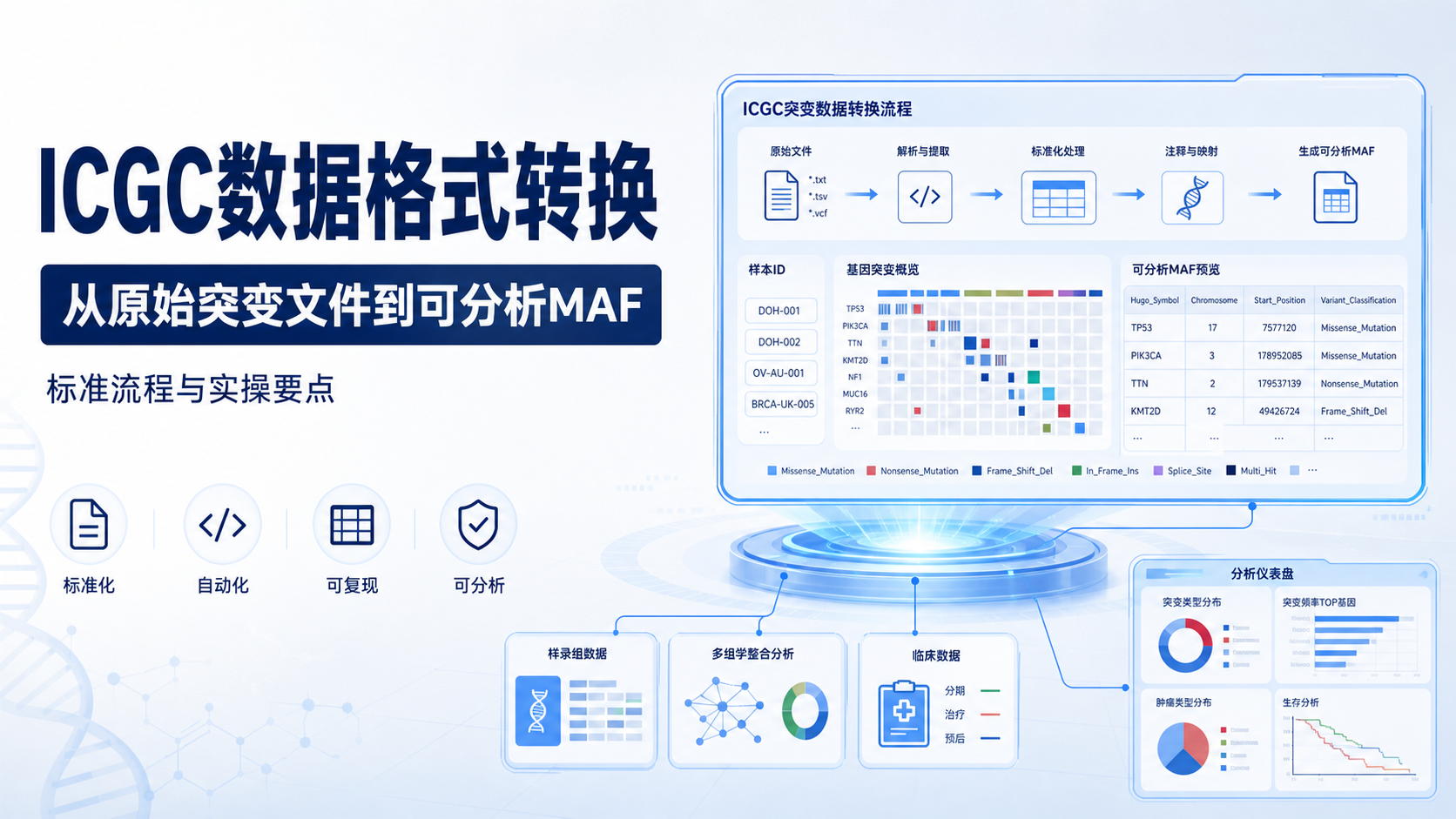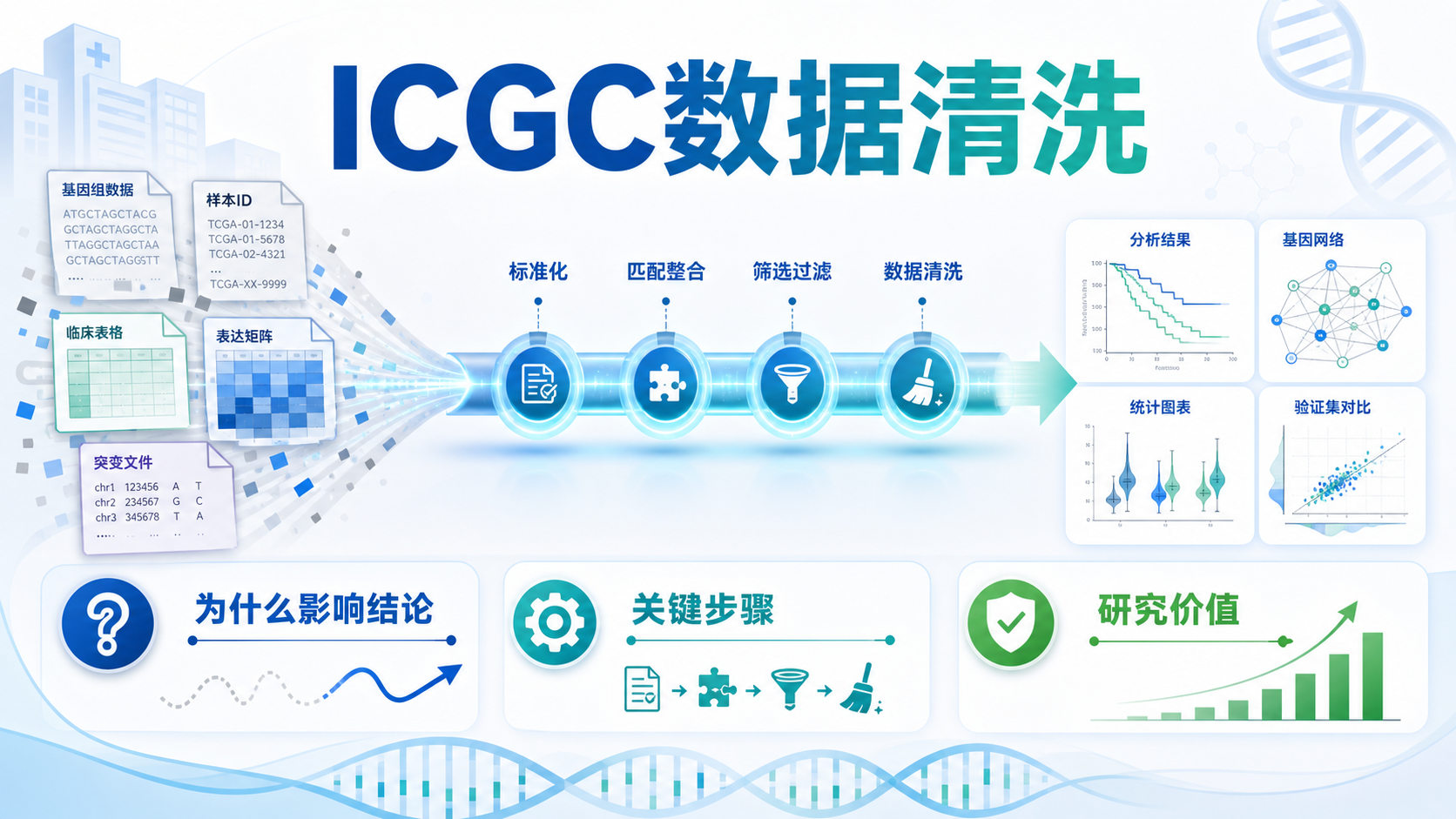
引言Introduction
ICGC数据清洗,是很多肿瘤生信项目最容易被低估的一步。数据看起来已经下载好了,但如果样本ID、表达矩阵、突变文件没有处理一致,后续分析就会出错,甚至得出相反结论。对医学生、医生和科研人员来说,先理解icgc数据清洗的价值,再谈建模和发表,才是更稳妥的路径。

1.ICGC数据为什么不能直接用于分析
1.1 数据来源复杂,格式并不统一
ICGC是一个全球共享的肿瘤数据库,来源于不同国家和地区的项目。它覆盖多种肿瘤类型,但不同项目的数据粒度、字段结构和命名方式并不完全一致。这意味着下载到本地的数据,通常不能直接进入统计分析。
从知识库信息可以看出,ICGC更适合“在线检索”和“下载后清洗”结合使用。在线功能方便快速筛选分子,下载功能则用于进一步验证和组学分析。若跳过清洗步骤,后续很容易出现样本对应错误、字段缺失、重复记录等问题。
1.2 ICGC与TCGA类似,但用途不同
很多人会把ICGC和TCGA放在一起比较。它们都属于泛癌研究资源,但差异明显。TCGA数据更全,类型更多,通常是主分析数据库。ICGC常被用作辅助验证集,尤其适合用于验证TCGA筛到的候选分子。
也正因为它常用于验证,数据质量更需要严格把关。验证集一旦样本错配,结论就会失真。对于想做生信文章的人来说,icgc数据清洗不是附加步骤,而是研究可信度的基础。
2.ICGC数据清洗到底在清什么
2.1 样本ID与临床信息匹配
ICGC数据清洗的第一步,通常是处理样本ID。知识库明确提到,数据库下载的数据中包含样本ID、捐赠者ID、突变位点、表型等信息。实际分析时,研究者往往需要把这些信息和临床表型、表达矩阵、突变数据对应起来。
如果ID不统一,表达数据和临床信息就无法正确匹配。
这会直接影响分组分析、差异分析和生存分析。对于多组学研究,错误匹配还会导致突变状态与转录组结果不一致,影响下游解释。
2.2 表达矩阵与突变文件标准化
ICGC数据清洗还包括表达矩阵和突变文件的整理。知识库中提到,转录组数据清洗和突变数据整理是最常见的两类任务。尤其是突变文件,体积大、字段多,直接打开和人工处理都非常低效。
在实际操作中,常见清洗目标包括:
- 统一样本顺序。
- 去除无效字段。
- 识别重复样本。
- 提取关键突变信息。
- 转换为后续分析可用的标准格式。
这一步决定了数据能不能被统计模型正确读取。
如果格式不规范,哪怕样本数很多,也只是“看上去可用”。
3.icgc数据清洗为什么会直接影响结论
3.1 错配会放大假阳性和假阴性
生信分析最怕的不是结果少,而是结果错。样本错配、字段缺失、分组错误,都会让差异基因、突变频率、通路富集结果产生偏移。清洗不彻底,假阳性和假阴性都会增加。
例如,在突变分析中,如果把突变样本和野生型样本分组错误,后续比较出来的差异表达基因就不再可信。即便图形看起来漂亮,也不能说明结论可靠。
3.2 清洗质量影响可重复性
科研工作尤其强调可重复性。ICGC数据清洗做得规范,别人才能按同样规则复现你的结果。反之,如果你依赖手工筛选、缺乏明确规则,后续复现会非常困难。
知识库强调,ICGC的在线功能可以帮助快速定位目标,数据下载与清洗则决定能否进入真正的分析阶段。对科研人员来说,清洗步骤本质上是在建立研究的可追溯性。
3.3 不同项目测序深度不同
知识库还提示了一个关键事实。不同项目的测序深度不同,测出来的突变类型和突变位点数量也会不同。也就是说,ICGC数据清洗不仅是格式问题,还涉及技术背景的识别。
如果忽略项目间差异,简单合并数据,结果可能混入技术偏倚。尤其在泛癌分析、跨项目比较和多组学整合中,这一点更重要。清洗的目的之一,就是尽量减少非生物学差异。
4.做ICGC数据清洗时,最该关注哪些步骤
4.1 先明确研究目的
知识库多次强调,使用ICGC前要先明确目的。是为了筛分子,还是为了做生信文章,还是为了结合实验验证。研究目的不同,清洗重点也不同。
如果目标是筛选候选分子,重点在样本和表型匹配。
如果目标是做文章,重点在数据标准化、分组和可重复性。
如果目标是多组学整合,还要特别注意突变、转录组和临床信息的一一对应。
4.2 优先处理两类核心数据
从教程内容看,ICGC最重要的两类处理对象是:
- 转录组数据。
- 突变数据。
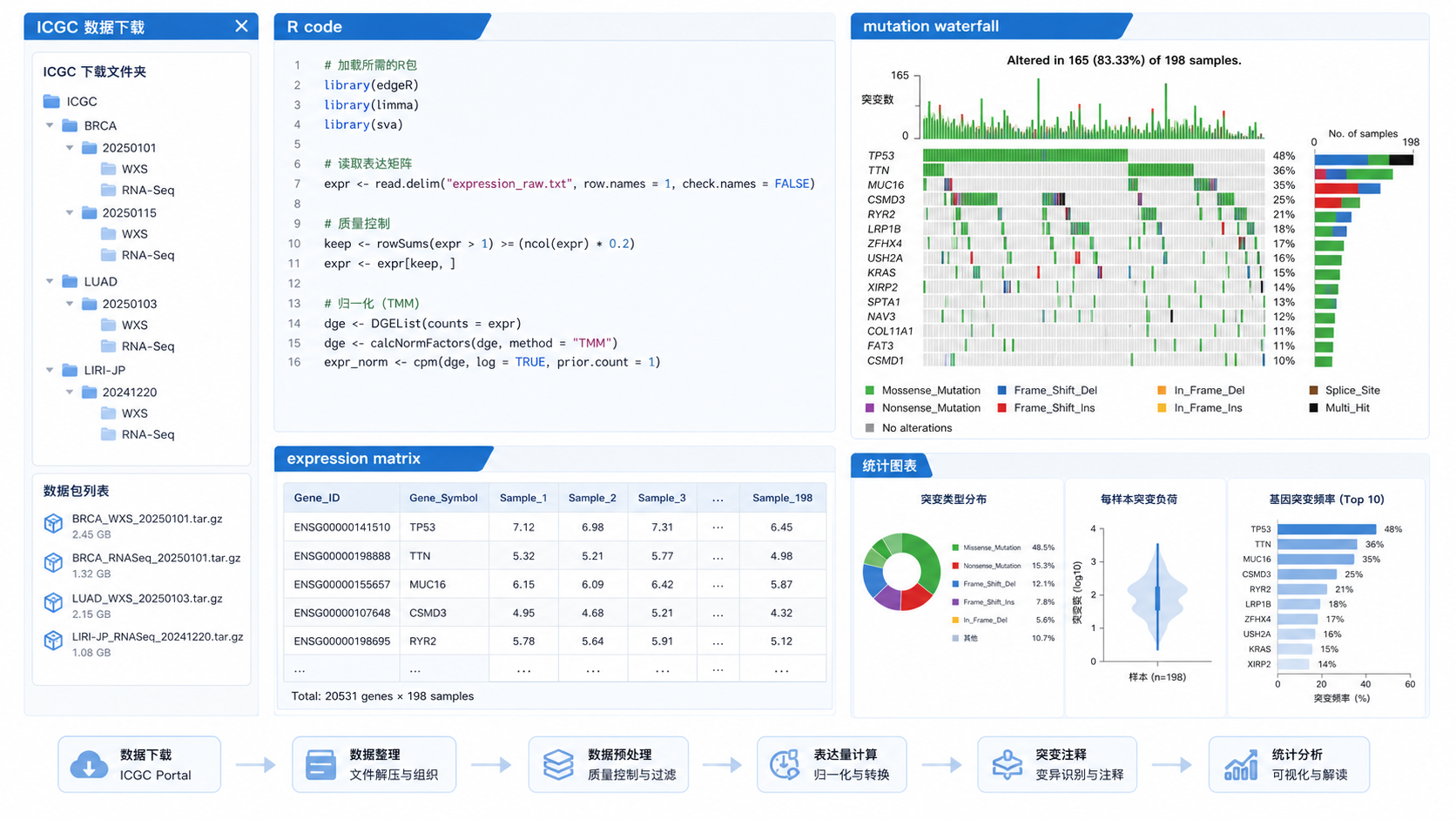
转录组数据适合做表达差异和分组比较。突变数据适合做瀑布图、突变频率和位点分析。这两类数据一旦清洗规范,后续分析效率会明显提升。
4.3 尽量使用标准化流程
知识库中提到,突变数据处理常常需要借助R语言和特定函数,如将ICGC体细胞突变文件转换为可分析格式。对研究者来说,标准化流程至少有三个好处:
- 降低人工操作错误。
- 提高处理效率。
- 方便批量复现。
对于R语言基础较弱的人,视频实操比纯文字更容易上手。这里也体现出解螺旋课程的优势。把复杂的清洗步骤拆成可执行流程,能显著降低入门门槛。
5.icgc数据清洗在实际研究中的价值
5.1 作为TCGA验证集更稳
在现有研究中,TCGA常作为主分析数据,ICGC常用于验证。这个组合非常常见。前提是,ICGC数据清洗必须足够严谨,才能真正承担验证职责。
如果验证集没有处理好,主分析就算正确,也可能因为验证失败而无法发表。所以ICGC不是“备用数据库”,而是必须认真对待的独立证据来源。
5.2 支持突变与表达联动分析
知识库中的示例说明,清洗后的ICGC数据可以用来识别TP53突变样本,再进一步比较突变组和野生型组的转录组差异。这个思路非常典型。
它说明icgc数据清洗不是单纯整理文件,而是在为后续分析铺路。样本分组清晰后,研究者才可以进一步探究:
- 突变与表达的关系。
- 不同亚组的分子差异。
- 候选靶点是否具有验证价值。
5.3 让结果更适合发表
发表级分析通常要求流程清楚、样本明确、结果可追溯。icgc数据清洗做好了,文章的方法部分就更容易写清楚,结果部分也更容易被审稿人接受。
清洗不是耗时,而是节省返工。
前期多花一点时间,后面可以少走很多弯路。
总结Conclusion
ICGC数据清洗之所以重要,是因为它决定了样本能否正确匹配、数据能否稳定分析、结论能否被重复验证。对于医学生、医生和科研人员来说,ICGC最有价值的地方,不只是“能下载”,而是“能规范地用”。先清洗,再分析,才是更可靠的科研路径。
如果你想更高效地完成icgc数据清洗,减少格式整理和代码试错,可以借助解螺旋的相关课程与实操资源,把在线检索、数据下载和清洗流程一次打通,让你的肿瘤生信分析更快进入可发表阶段。
- 引言Introduction
- 1.ICGC数据为什么不能直接用于分析
- 2.ICGC数据清洗到底在清什么
- 3.icgc数据清洗为什么会直接影响结论
- 4.做ICGC数据清洗时,最该关注哪些步骤
- 5.icgc数据清洗在实际研究中的价值
- 总结Conclusion