





引言Introduction
病例对照研究暴露评估,决定了研究结果是否可信。很多论文看似设计完整,却因为回忆偏倚、信息偏移或对照选择不当,导致关联被高估或低估。如果暴露测量不准,后续OR值再漂亮也可能失真。
1. 病例对照研究中,为什么暴露评估最容易出问题
1.1 暴露信息多依赖回忆,天然存在误差
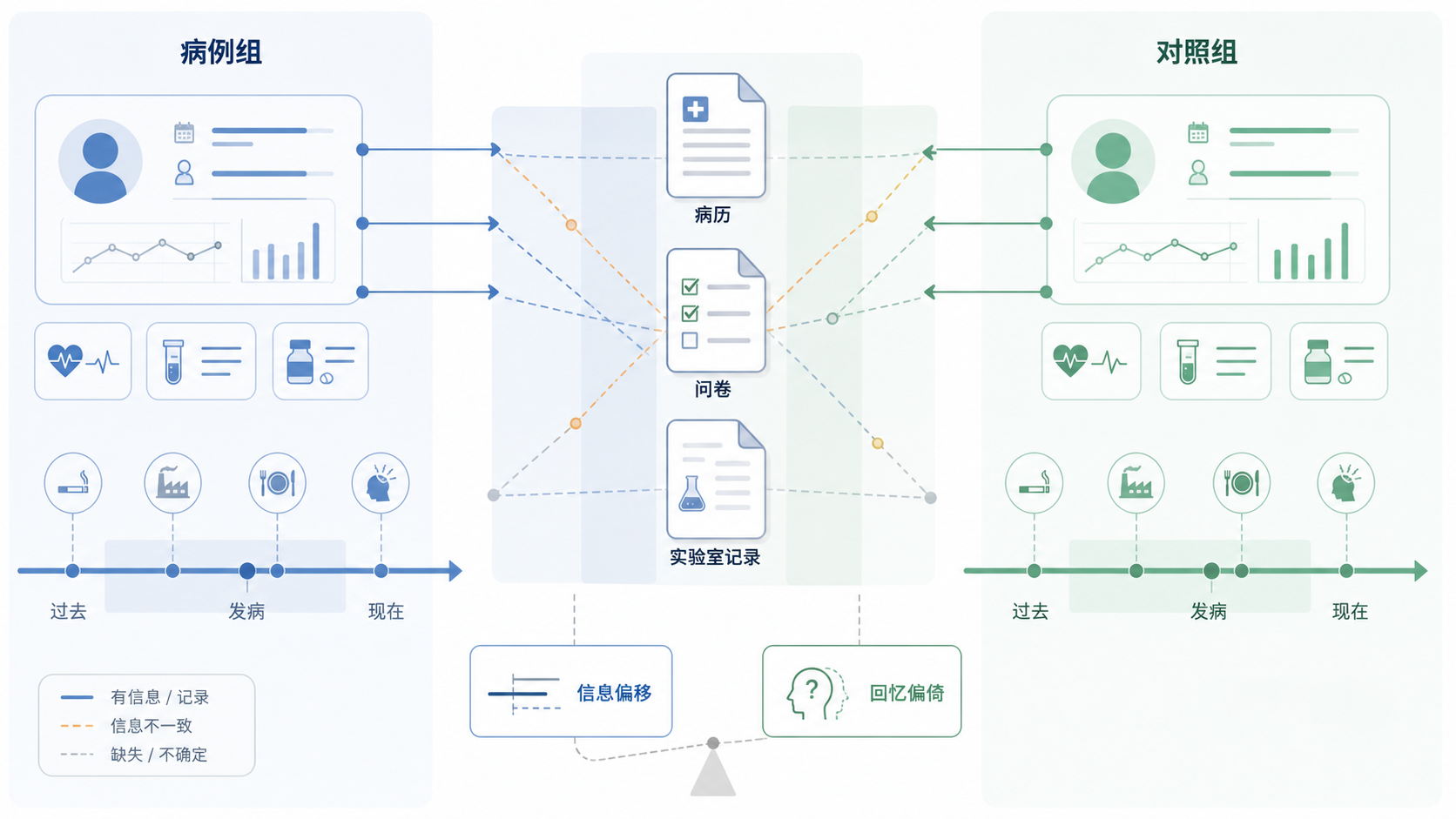
病例对照研究的核心,是回过头去比较病例组和对照组既往暴露水平。问题在于,很多暴露并没有被前瞻性记录,只能依赖研究对象回忆。记忆本身就不稳定,疾病诊断后还会改变回忆方式。
病例往往会更主动地回想“自己为什么会生病”,对烧烤、熬夜、用药等因素更敏感。对照则可能因为没有患病,不会特别留意过去暴露。这种差异会造成差异性错分 ,直接影响效应量。
1.2 关注后效应会放大信息偏移
疾病发生后,病例常出现“关注后效应”。也就是得病后才开始追溯可能原因。这个过程会让病例组暴露报告更细致,甚至更容易把无关因素也记成相关因素。这会把真实关联放大,或者制造出不存在的关联。
对照组则常常缺少这种反思压力,暴露回忆更粗略。两组测量方式不一致时,结果就不再只是“随机误差”,而是系统性偏差。对于科研写作和审稿,这类问题比单纯样本量不足更致命。
2. 提升病例对照研究暴露评估准确性的关键方法
2.1 优先使用结局发生前的客观记录
提升准确性的第一原则,是尽量不用纯回忆,改用结局前记录的数据 。例如病案资料、体检记录、实验室结果、处方记录、注册数据库等。只要记录时间早于结局发生,信息偏移风险就会明显下降。
这类数据的优势是可追溯、可核查、可重复。尤其在药物暴露、实验室指标、既往诊断等研究中,客观记录比访谈更可靠。能用既往记录,就不要只靠口头回忆。
2.2 统一暴露定义和测量流程
暴露评估不准,很多时候不是因为“没有数据”,而是因为定义不统一 。病例组和对照组如果使用不同的问题、不同时间窗、不同判定标准,结果必然失真。
实际研究中建议做到以下几点。
- 提前写清楚暴露定义。
- 设定一致的回顾时间窗。
- 使用同一套量表或问卷。
- 对关键暴露设置明确阈值。
例如,若研究“长期吸烟”,就要明确包年、频率和持续时间。若研究用药史,就要定义剂量、疗程和停药时间。没有标准化定义,就没有高质量暴露评估。
3. 盲法如何帮助减少暴露评估偏差
3.1 对研究对象设盲,减少主观修正
在病例对照研究中,可以考虑对研究对象进行一定程度的设盲,尤其是对危险因素的提示进行控制 。例如,不直接强调某个暴露是研究重点,避免受访者有意迎合研究假设。
如果过早暴露研究目的,病例组更容易“补齐记忆”,对照组则可能忽视相关经历。
当然,完全盲法并不总是可行。尤其在面对面访谈、病史采集时,研究对象往往能猜到研究方向。因此,设盲更多是降低偏差,而不是完全消除偏差。
3.2 对观察者设盲,更适合标准化测量
如果由研究人员判断暴露是否成立,观察者设盲 尤其重要。让测量者不知道研究对象属于病例还是对照,可以降低主观倾向。
例如,在影像判读、病理分级、实验室结果解释中,盲法更容易执行,也更有价值。
知识库强调,可以通过引入虚拟危险因素来检查信息偏移。如果一个与疾病无关的“假暴露”在病例组和对照组间出现显著差异,就提示测量过程可能存在系统误差。这是判断暴露评估质量的实用思路。
4. 设计层面上,如何减少暴露评估误差
4.1 选择合适的病例和对照来源
暴露评估是否准确,不只取决于测量本身,也取决于病例和对照是否可比 。如果病例来自医院,对照却来自完全不同的时间和空间环境,暴露机会本身就不一致。这样即使测量方法相同,结果也可能失真。
知识库建议,若研究人群已知,最好从全体人群中选择对照;如果不可行,就随机抽样。若人群未知,则尽量选择时间、空间上接近病例的对照。对照组的选择独立于暴露因素,是暴露评估可靠的前提。
4.2 每个病例最多配到4个对照
在病例较少时,可以增加对照数来提高研究把握度。知识库指出,1:1最有效率,但对照数增加到4:1以内仍有意义,超过4:1后把握度提升很有限。
这条规则对暴露评估也有间接帮助。更多对照能提高统计稳定性,但不能替代高质量测量。换句话说,样本更多,不等于信息更准。
4.3 必要时设置第二个对照组
如果主要对照来源拿不准,可以设置第二个对照组进行交叉验证。
例如,一组来自医院,一组来自普通人群。若两组结果方向一致,说明暴露评估和对照选择更稳健;若差异很大,就要回头检查是否存在选择偏移或信息偏移。双对照设计不是为了炫技,而是为了验证真实性。
5. 暴露评估后,如何判断结果是否可信
5.1 不能只看OR值,还要看置信区间
病例对照研究常用OR值评价关联强度,但OR值本身不能单独证明因果。必须结合95%置信区间和P值一起看。
如果暴露评估存在偏差,OR值可能被高估或低估,甚至方向都可能错误。
知识库也提醒,病例对照研究的关联强弱判定只是相对标准。一般可将0.33到3视为潜在偏移区,更严格时小于0.25或大于4才更值得重点关注。前提是分析方法正确,混杂控制也要到位。没有准确暴露评估,关联强弱的解释就站不住。
5.2 讨论部分要主动说明局限
高质量论文不会回避暴露评估问题,而是会明确说明。
建议在讨论中写清楚:
- 暴露是否来自客观记录。
- 是否存在回忆偏倚。
- 是否进行了盲法或标准化测量。
- 是否可能存在差异性错分。
这种写法符合E-E-A-T,也更容易获得审稿人信任。把局限讲明白,往往比硬说“结果可靠”更专业。
6. 写作和实操中,怎样把暴露评估做得更稳
6.1 先定变量,再定数据源
很多研究失败,不是分析做错,而是变量定义先天模糊。建议在研究开始前先明确:
- 暴露变量是什么。
- 暴露窗口多长。
- 以什么作为阳性标准。
- 数据从哪里来。
- 谁来判定。
这样做能显著减少后期补数据和改定义的风险。对于医学生、医生和科研人员来说,这一步比统计软件更重要。病例对照研究暴露评估,本质上是研究设计问题,不只是统计问题。
6.2 优先使用可核查、可复现的数据
如果暴露可以被病历、处方、实验室结果或登记系统验证,就尽量不要只靠主观访谈。
如果必须依赖回忆,就应尽量:
- 缩短回顾时间。
- 提供时间锚点帮助回忆。
- 使用统一问卷。
- 由受过培训的人员采集。
这些方法不能消除偏差,但能降低偏差幅度。更准确的暴露评估,来自更少的主观判断。
总结Conclusion
病例对照研究暴露评估的核心,不是“问得更多”,而是“测得更准”。优先使用结局前记录,统一定义和流程,合理设盲,必要时设置第二对照组,才能最大限度减少回忆偏倚和信息偏移。真正可靠的病例对照研究,靠的是设计先行,而不是事后补救。
如果你正在做病例对照研究,或准备撰写相关论文,建议优先使用解螺旋 的科研工具和方法框架,系统梳理病例、对照和暴露变量,减少设计漏洞,让数据更可信,写作更高效。

- 引言Introduction
- 1. 病例对照研究中,为什么暴露评估最容易出问题
- 2. 提升病例对照研究暴露评估准确性的关键方法
- 3. 盲法如何帮助减少暴露评估偏差
- 4. 设计层面上,如何减少暴露评估误差
- 5. 暴露评估后,如何判断结果是否可信
- 6. 写作和实操中,怎样把暴露评估做得更稳
- 总结Conclusion



