引言Introduction
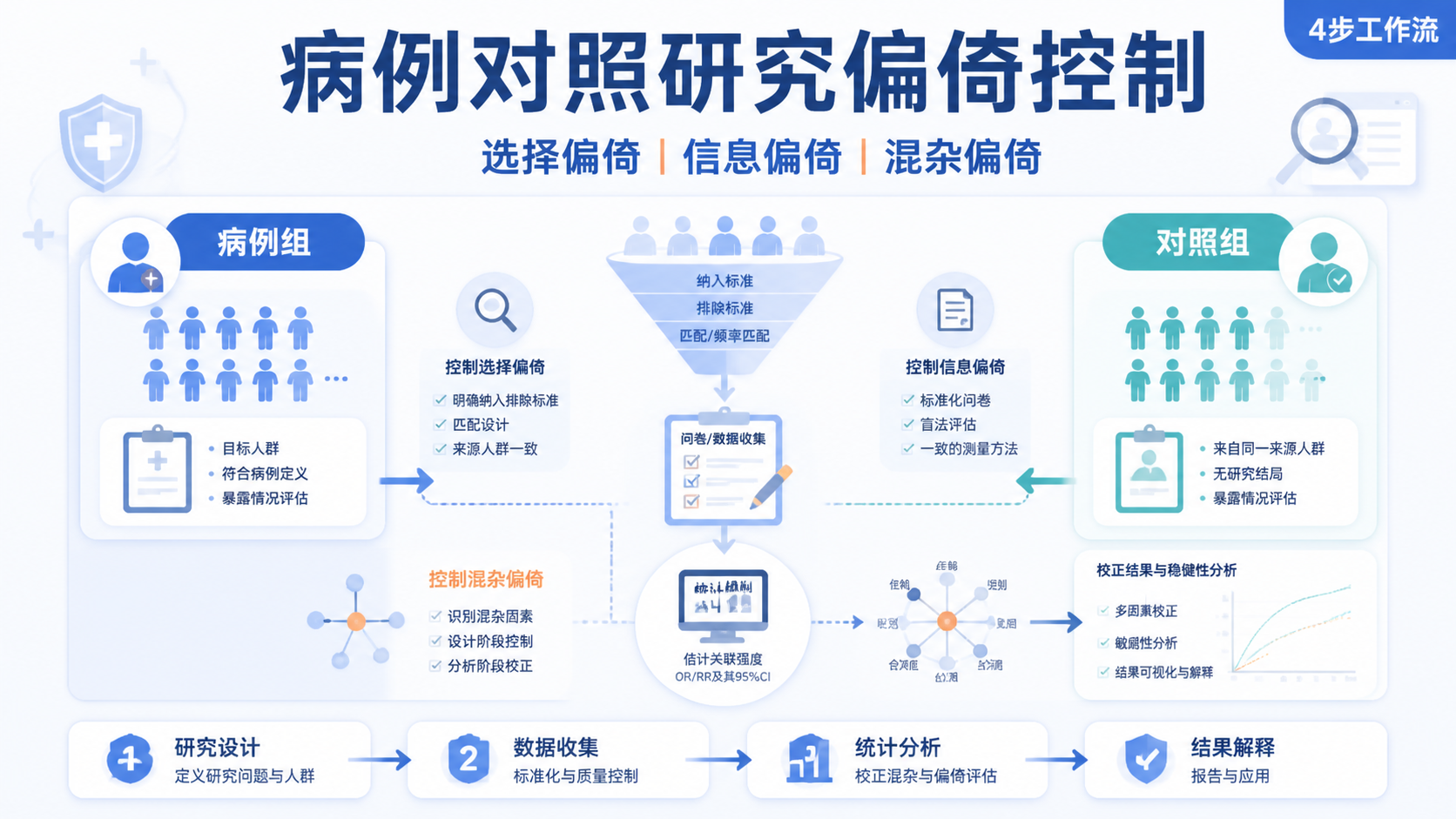
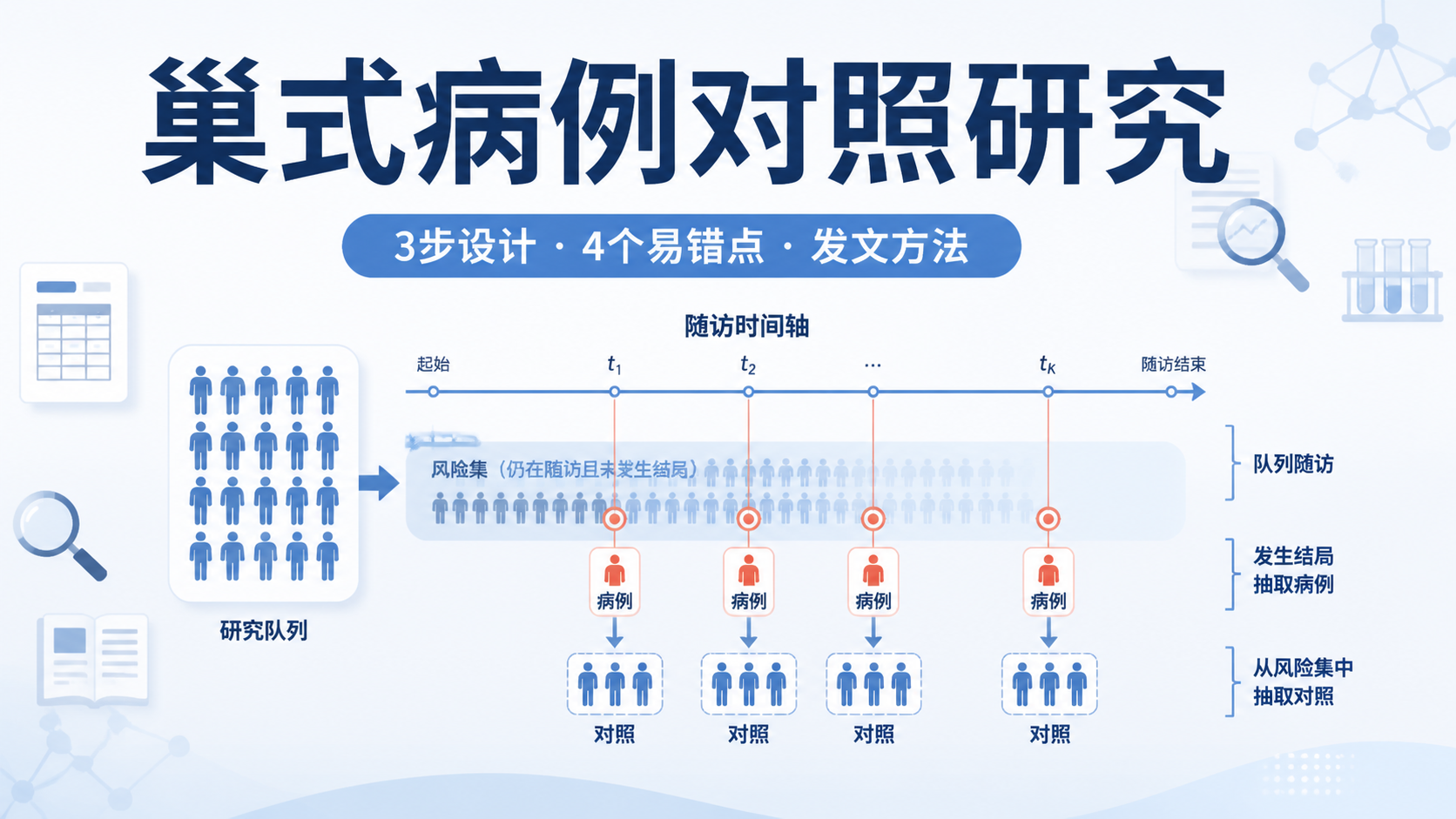
病例对照研究统计分析为什么总出错?核心原因往往不是软件,而是研究设计、对照选择和混杂控制不到位。对医学生、医生和科研人员来说,病例对照研究统计分析的难点在于如何把“暴露”和“结局”真正分开看清 。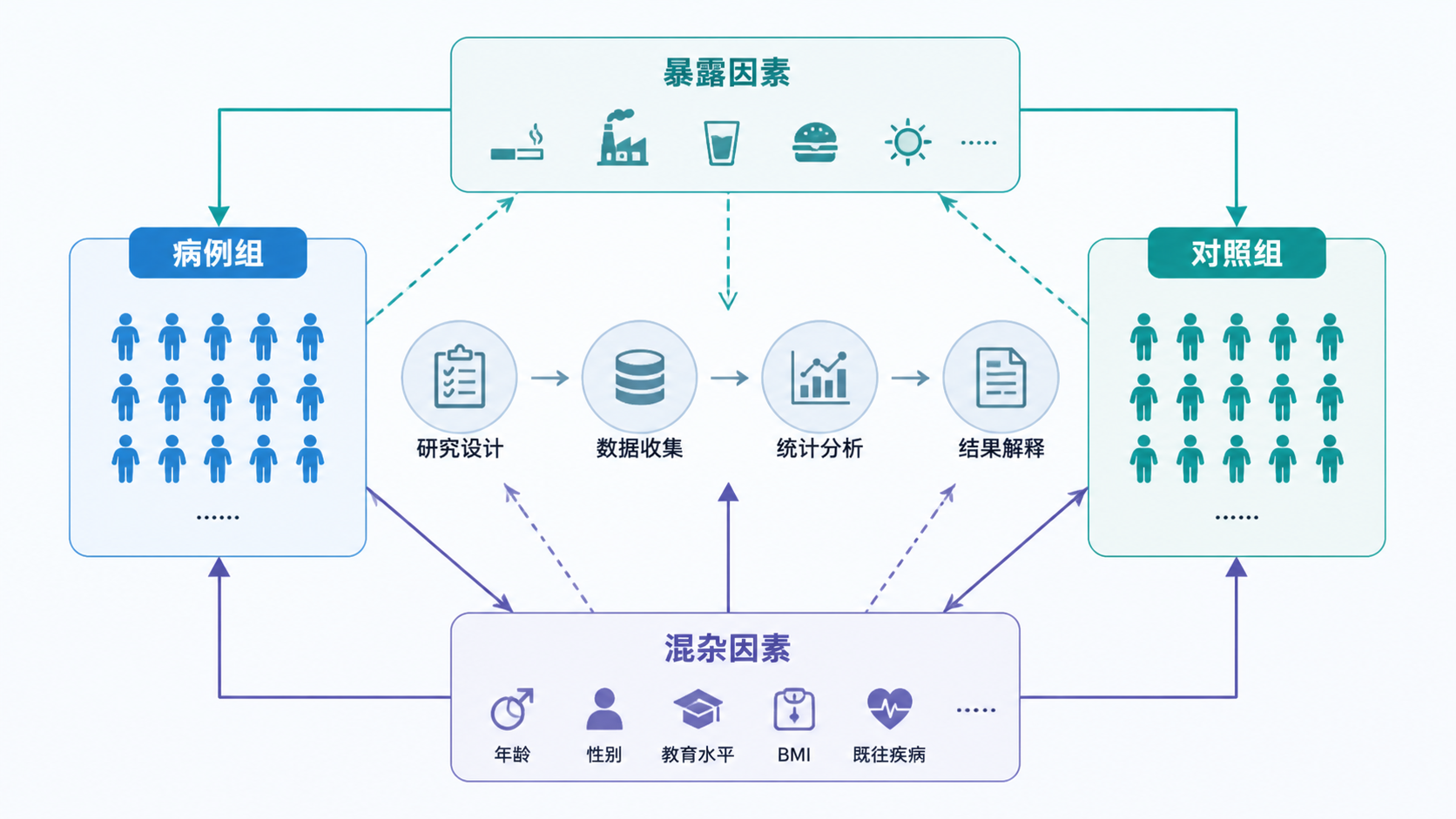
1. 病例对照研究统计分析,先错在研究设计
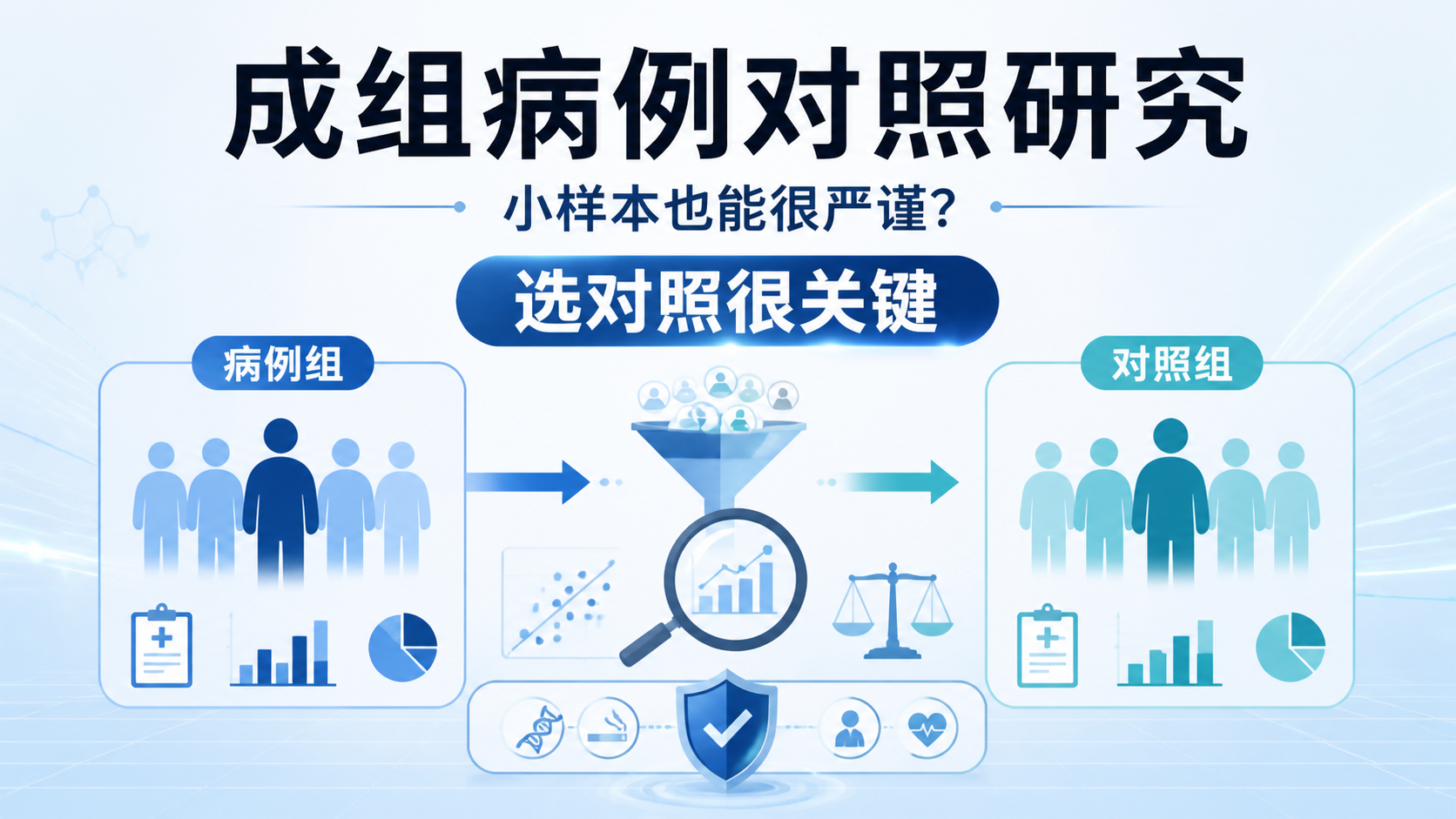
1.1 对照选错,后面再补救也有限
病例对照研究是先有结局,再回顾暴露。它的第一步不是回归模型,而是病例和对照是否可比。知识库明确指出,对照的选择必须未患研究结局、代表可能发病人群、且独立于研究暴露 。这三点任一出错,统计结果就会偏。
常见问题是对照来源不当。比如研究NSAID与结肠癌关系时,如果把关节炎住院患者当对照,对照组NSAID暴露率会偏高,效应值可能被低估。若把消化性溃疡患者当对照,又可能因其不宜用NSAID而高估效应值。这类错误不是统计软件能修正的。
1.2 匹配不是越多越好
很多人一听到混杂,就想尽量匹配。其实过度匹配会把真实关联“匹”掉。知识库中提到,病例对照研究常用的控制方法包括直接配对和PSM倾向评分匹配,但匹配的前提是围绕已知关键混杂因素,而不是把一切变量都绑死。
匹配做得好,可以提高可比性。匹配做得差,可能引入新的偏倚。因此,病例对照研究统计分析出错,常常是前期设计已经埋雷。
2. 病例对照研究统计分析,为什么总卡在混杂控制
2.1 混杂控制是观察性研究的首要任务
在观察性研究中,混杂控制是统计分析的首要任务。知识库强调,随机对照试验可以依靠随机化均衡已知和未知混杂,而病例对照研究没有随机化,只能靠限制、配对、分层和多因素分析来补救。
这里最容易犯的错,是把“调整了几个变量”误当成“混杂已经控制住了”。实际上,是否控制住混杂,取决于变量选取是否合理、是否存在残余混杂、以及暴露和结局的定义是否准确 。如果变量本身测量不准,再复杂的模型也只能得到更复杂的偏差。
2.2 限制、配对、分层、多因素,各有边界
知识库把观察性研究中的混杂控制分为设计阶段和分析阶段。设计阶段常用限制和配对。分析阶段常用分层分析和多因素分析。实践中最常见的问题是:
- 设计阶段没有做好,分析阶段想靠模型“救回来”。
- 分层太多,样本量被切碎,估计不稳定。
- 多因素模型纳入变量过多,出现过拟合。
病例对照研究统计分析的本质,是在样本有限的前提下尽可能逼近真实关联,而不是追求变量越多越好。
3. 病例对照研究统计分析,模型用错比不建模更糟
3.1 单因素显著,不等于可以直接下结论
病例对照研究常见套路是先做单因素分析,再做多因素分析。知识库明确提到,单因素分析通常先看OR值、置信区间和P值,再进入逻辑回归、条件逻辑回归等模型。但很多文章的错误就在于,把单因素显著直接写成结论。
单因素分析只能提示关联。它不能自动排除混杂。真正用于推断因素与结局关系的,通常是多因素分析结果,而不是单因素P值。
3.2 逻辑回归和条件逻辑回归不能混用
病例对照研究里,最常见的模型是逻辑回归。若病例与对照做了匹配,则常用条件逻辑回归。知识库中提到,睾酮与血栓、绝经后雌激素与阿尔茨海默症等病例对照研究,都使用了匹配分析和条件逻辑回归来校正混杂。
这意味着,是否匹配,决定了模型选择 。如果做了配对,却用普通逻辑回归,可能忽略配对结构。如果没做配对,却机械使用条件逻辑回归,也不合适。模型错配,会直接影响OR估计和置信区间。
3.3 结局事件少时,模型更要谨慎
知识库还提到,在结局发生率很低时,也可能考虑泊松回归等方法。但病例对照研究的核心仍是OR,而不是RR或HR。很多初学者把这些指标混用,导致结果解释错误。
病例对照研究统计分析必须先分清研究类型,再决定效应量。病例对照研究的专业指标是OR,不是随意替换成别的比值。
4. 病例对照研究统计分析,结果解释最容易被误读
4.1 OR不等于风险,置信区间才是关键
OR值反映暴露与结局的关联强度。知识库指出,OR等于1表示无关联,大于1可能是危险因素,小于1可能是保护因素。但前提是变量编码方向正确,且结局确实指向不良事件。
很多错误来自“看见OR>1就说危险因素”。这并不严谨。还要看95%置信区间是否跨1,P值是否支持,以及变量编码是否反向。如果编码方向错了,OR的临床含义也会完全反过来。
4.2 P值不能单独代表证据强度
在病例对照研究中,P值只是统计学显著性的参考,不是最终证据。知识库多次强调,抽样研究存在抽样误差,因此不能只看P值,而要结合效应值和置信区间综合判断。
临床论文常见错误有三类:
- 只报P值,不报效应量。
- 只报OR,不报置信区间。
- 只追求显著性,不讨论临床意义。
高质量的病例对照研究统计分析,应该让读者一眼看到效应方向、效应大小和不确定性。
5. 病例对照研究统计分析,变量处理不规范也会出错
5.1 缺失值、异常值、变量筛选,都不能随便
知识库指出,观察性研究常面临缺失值和异常值问题。缺失比例较低时,可用剩余数据或合适方法处理;缺失过高时,填补风险很大。若缺失达到三分之一甚至更多,结果可能失真。
变量筛选也一样。不是所有变量都应机械纳入模型。应结合文献、临床意义和样本量。协变量越多,样本量需求越大,模型越容易不稳定。
5.2 基线比较不是形式,而是判断可比性的入口
不少病例对照研究在基线表上只放数值,不做解释。实际上,基线比较的意义在于评估病例组和对照组是否平衡。若差异明显,后续必须考虑匹配、分层或回归调整。
尤其在未严格匹配时,建议报告组间差异性比较。不比较,不代表没有偏倚。
6. 把病例对照研究统计分析做对,关键是三步走
6.1 第一步,先把设计做扎实
明确病例来源、对照来源和纳排标准。确保对照独立于暴露。必要时使用限制或配对。研究问题若偏因果推断,更要优先考虑混杂控制。
6.2 第二步,再选择正确模型
未匹配研究常用逻辑回归。匹配研究常用条件逻辑回归。若结局稀少或变量类型复杂,应结合数据特征选择合适模型。不要为了“高级”而选错模型。
6.3 第三步,结果只讲证据,不讲情绪
报告OR、95%CI、P值,并解释变量编码方向。讨论中应承认局限性。病例对照研究本质上是探索性研究,因果关系通常需要前瞻性研究进一步确认。
总结Conclusion
病例对照研究统计分析为什么总出错?归根结底,是因为很多人把问题都归咎于模型,却忽略了对照选择、混杂控制、变量编码和结果解释。真正可靠的病例对照研究统计分析,是设计、分析和解释三者一致。
如果你正在做病例对照研究,想少走弯路,可以借助解螺旋的科研方法与统计支持,把研究设计、模型选择和结果呈现一步步做规范。这样,OR、置信区间和结论才更有说服力。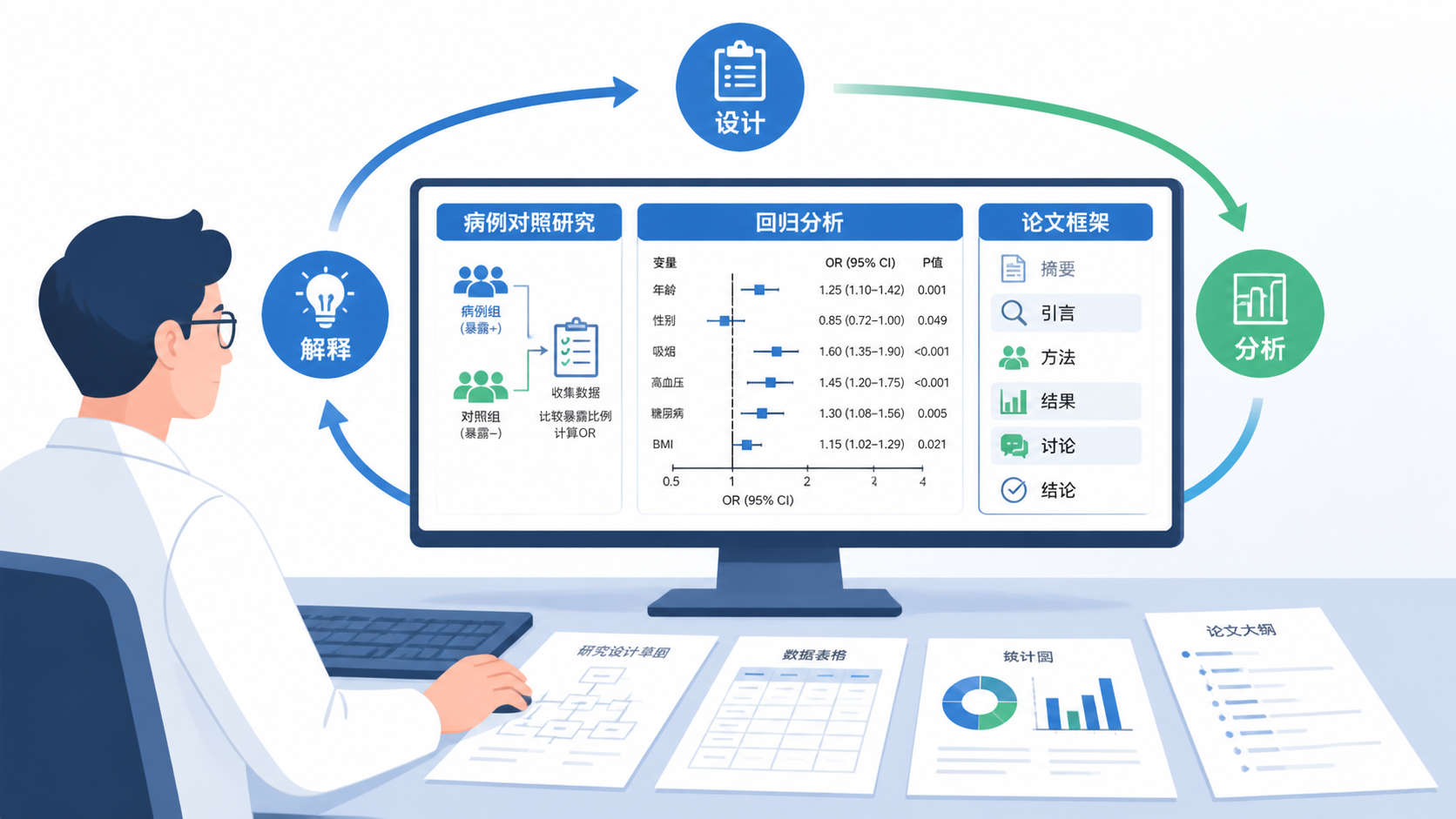
- 引言Introduction
- 1. 病例对照研究统计分析,先错在研究设计
- 2. 病例对照研究统计分析,为什么总卡在混杂控制
- 3. 病例对照研究统计分析,模型用错比不建模更糟
- 4. 病例对照研究统计分析,结果解释最容易被误读
- 5. 病例对照研究统计分析,变量处理不规范也会出错
- 6. 把病例对照研究统计分析做对,关键是三步走
- 总结Conclusion