引言Introduction
队列研究统计基础,是很多医学生和科研人员做课题时最先卡住的部分。研究设计清楚了,却不知道怎么分组、随访、算发生率,也不清楚HR和RR该怎么解释。如果统计基础不扎实,队列研究很容易出现偏倚、结论不稳、投稿被拒。
1. 先搞清楚队列研究的统计逻辑
1.1 队列研究到底在比较什么
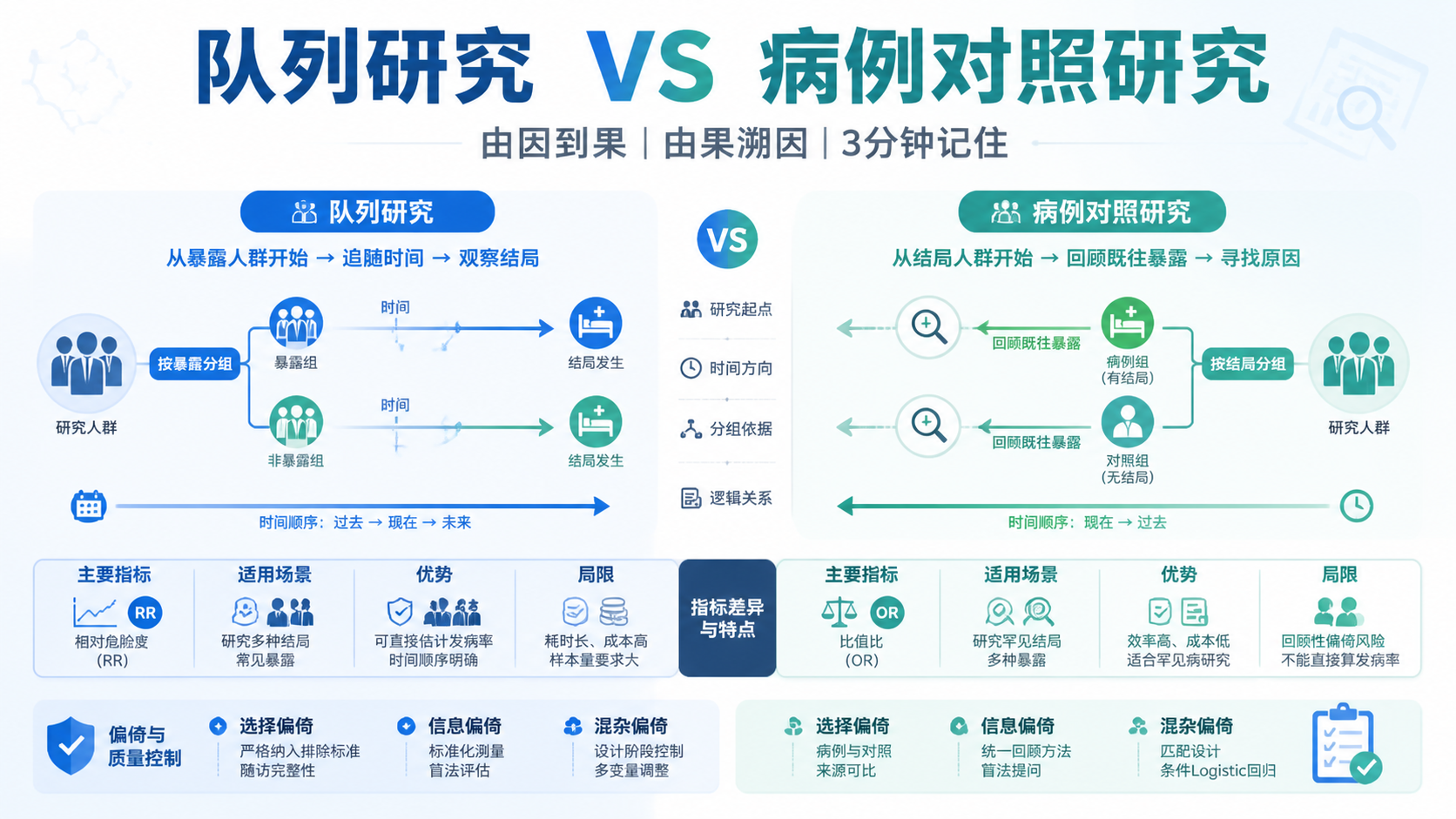
队列研究属于分析流行病学。核心不是“有没有病”,而是“不同暴露状态的人,后续结局发生是否不同 ”。常见做法是先按暴露分组,再向前或向后观察结局。
它和临床试验很像,但本质仍是观察性研究。统计上最重要的是时间顺序。暴露必须先于结局。 这也是队列研究比横断面研究更适合推断因果关系的原因。
1.2 常见统计目标有哪些
队列研究通常回答3类问题:
- 暴露组和非暴露组的结局发生率是否不同。
- 暴露水平升高,风险是否递增。
- 相关因素调整后,关联是否仍然存在。
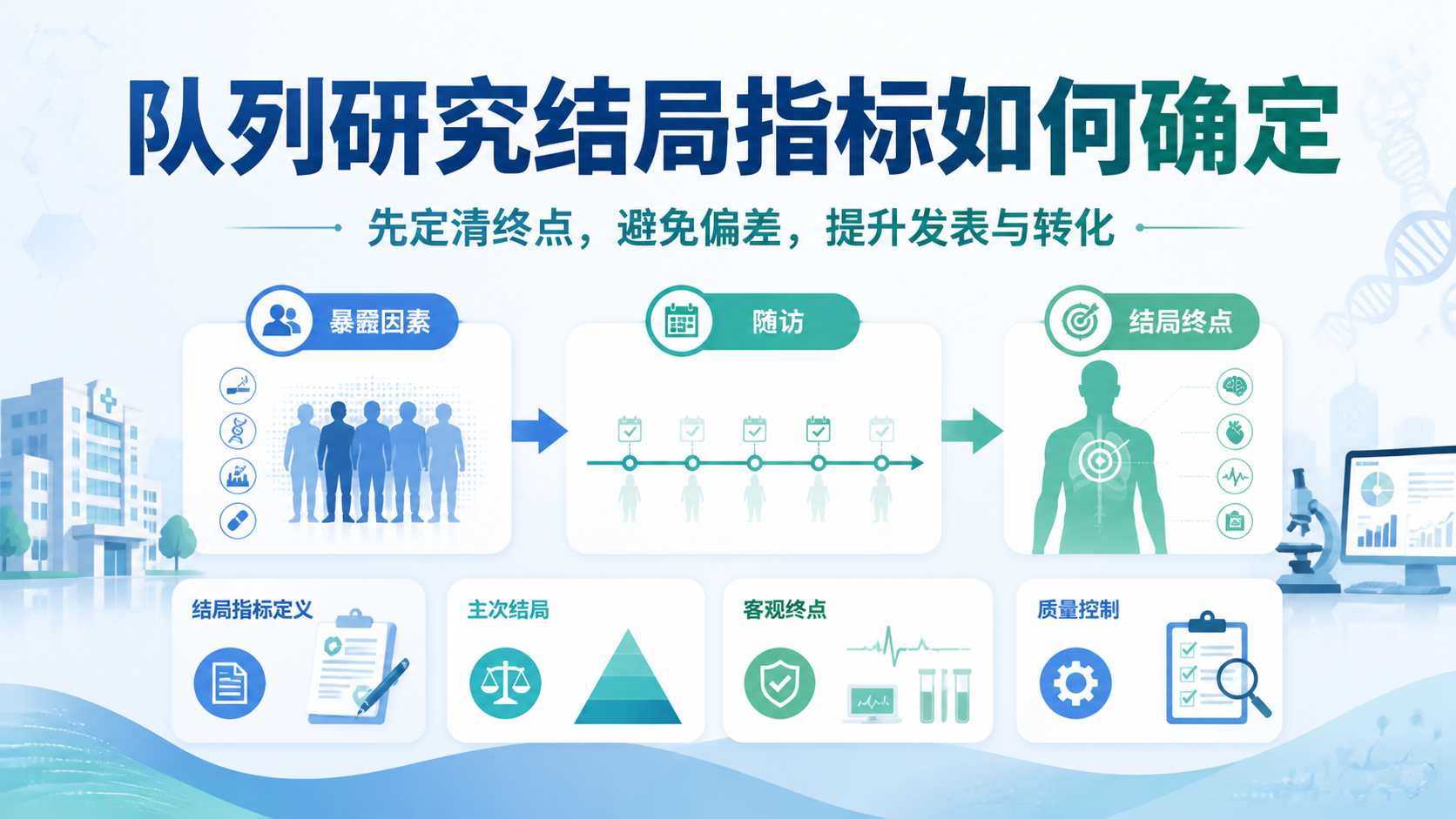
在实践中,最常见的结果指标包括发病、死亡、实验室指标变化和生命质量变化。先定义主要结局,再考虑次要结局,统计分析才不会跑偏。
2. 明确研究因素和结局变量
2.1 研究因素为什么要先定
队列研究费时、费力、费钱,且通常一次重点研究一个因素。所以上游设计里最关键的一步,是先确定暴露因素。
暴露可以是危险因素,也可以是保护因素。也可以按不同暴露水平分层,比如高、中、低暴露组。暴露定义越清晰,后续统计越稳定。
2.2 结局变量要可测、可追踪
结局变量是随访中出现的预期结果。它必须满足两个条件。第一,定义清楚。第二,能够被稳定记录。
例如:
- 疾病发生。
- 死亡。
- 血清指标变化。
- 影像学或分子标志变化。
如果结局定义含糊,统计模型再复杂也没有意义。统计分析的前提,是结局可重复、可核查。
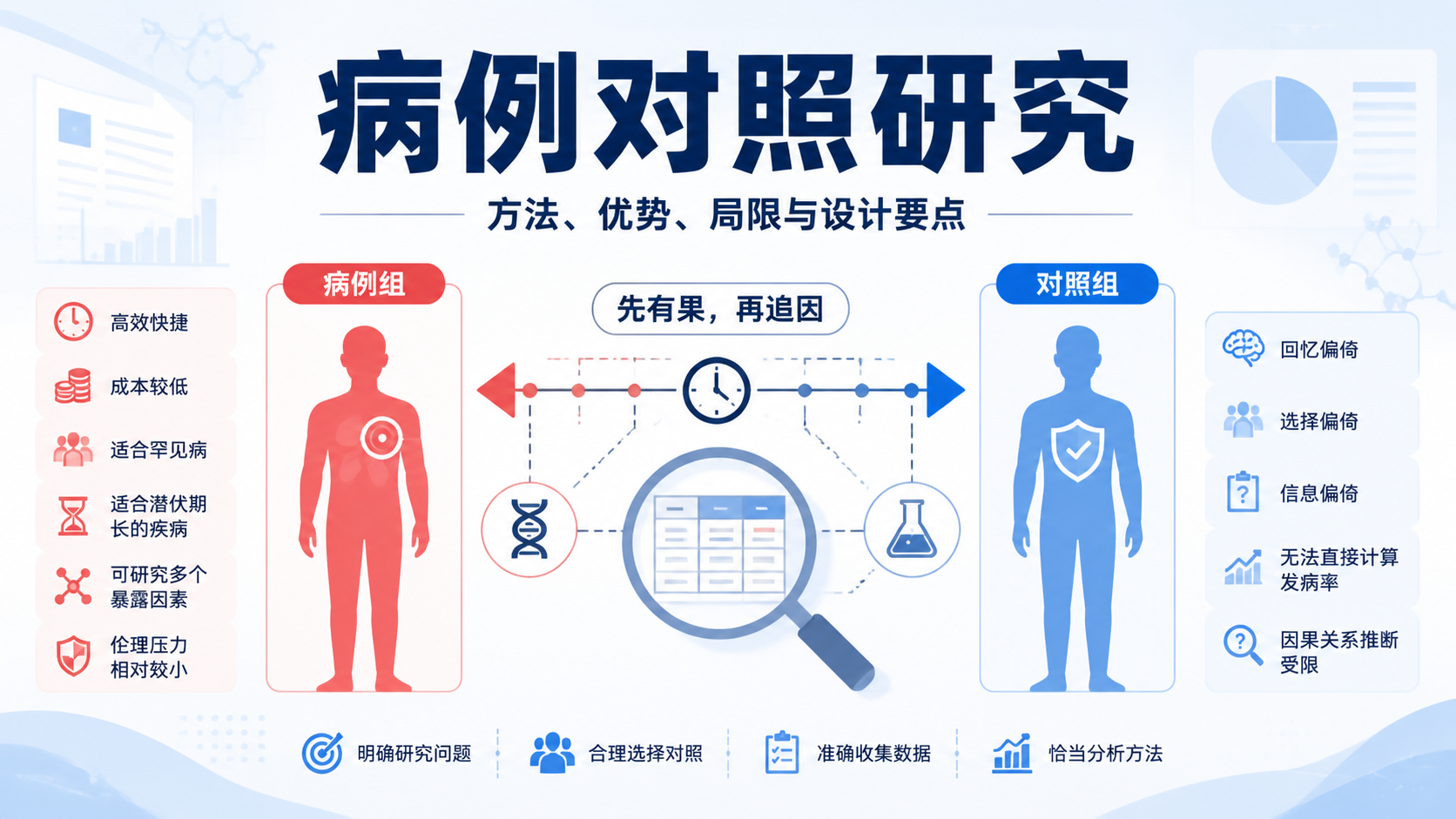
3. 设计分组与对照,保证可比性
3.1 暴露组和对照组怎么来
队列研究的基本结构,是按暴露状态分组。常见分法包括:
- 暴露组和非暴露组。
- 高暴露组和低暴露组。
- 不同剂量组。
这些组之间要尽量可比。统计上最怕的不是“有差异”,而是“差异来源不清 ”。如果年龄、吸烟、饮酒等混杂因素分布不均,结论就可能偏倚。
3.2 内对照和外对照的区别
内对照来自同一总体。比如同一医院、同一队列中的非暴露者。外对照来自另一个总体。两者都能用,但内对照通常可比性更好。
如果研究问题允许,优先选择内对照。 因为同源人群更容易控制选择偏倚,也更利于后续统计调整。
4. 计算样本量,别只看“人越多越好”
4.1 为什么样本量是统计基础
很多人误以为队列研究就是尽量扩大样本。实际上不是。样本量过小,检验效能不足;样本量过大,也会浪费资源。
样本量估计必须依赖几个前提:
- 主要暴露因素。
- 主要结局事件。
- 预期发病率或发生率。
- 允许的显著性水平和把握度。
没有明确主要暴露和主要结局,就无法合理估算样本量。
4.2 失访率必须提前算进去
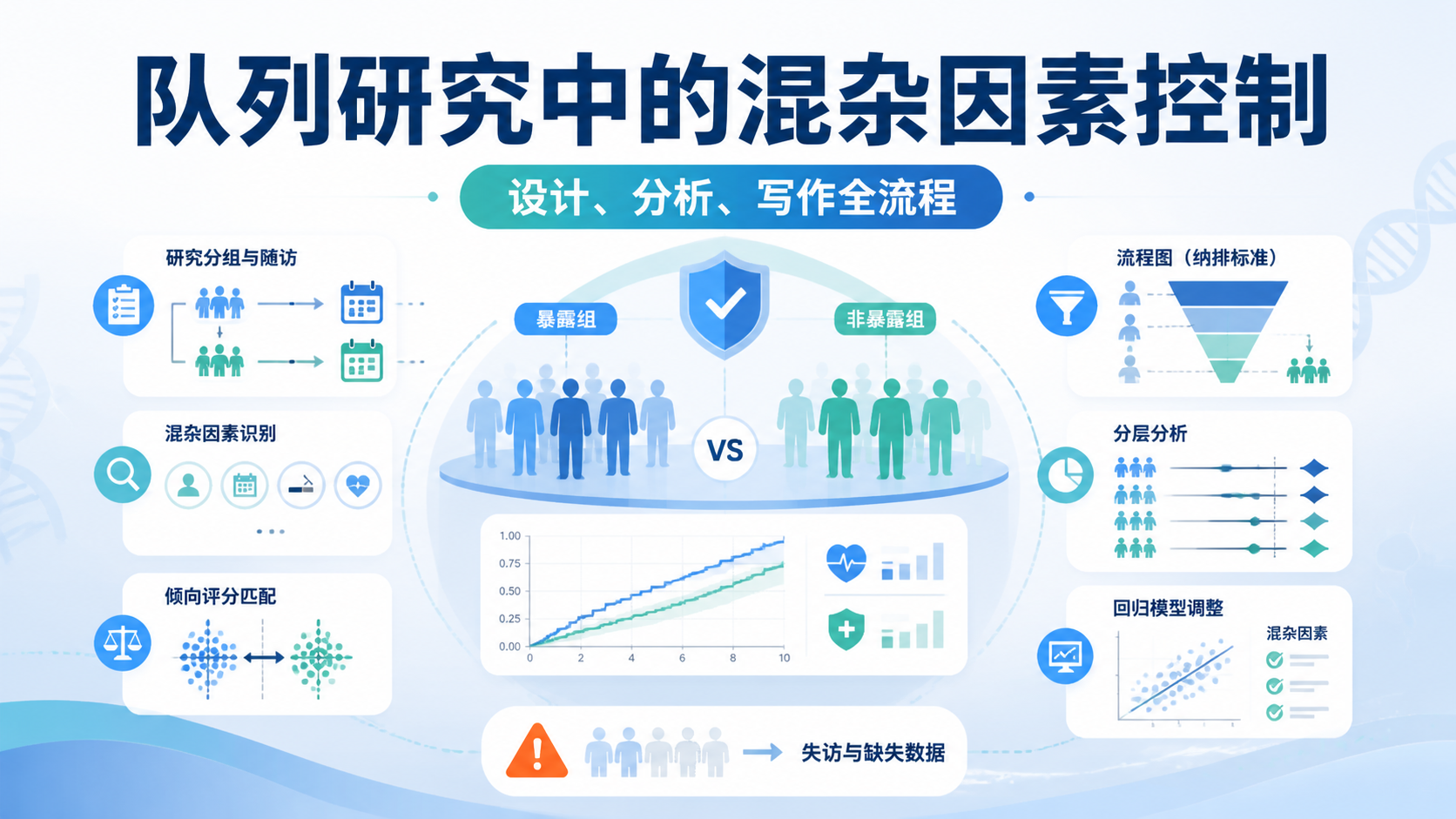
队列研究非常重视失访。知识库中明确提到,实际设计时常按约10%的失访率预留样本。也就是说,计算出的样本量还要上调,才能保证最终有效样本足够 。
这一点很关键。因为失访会降低统计效能,还可能带来偏倚。特别是长期随访研究,失访控制比建模更重要。
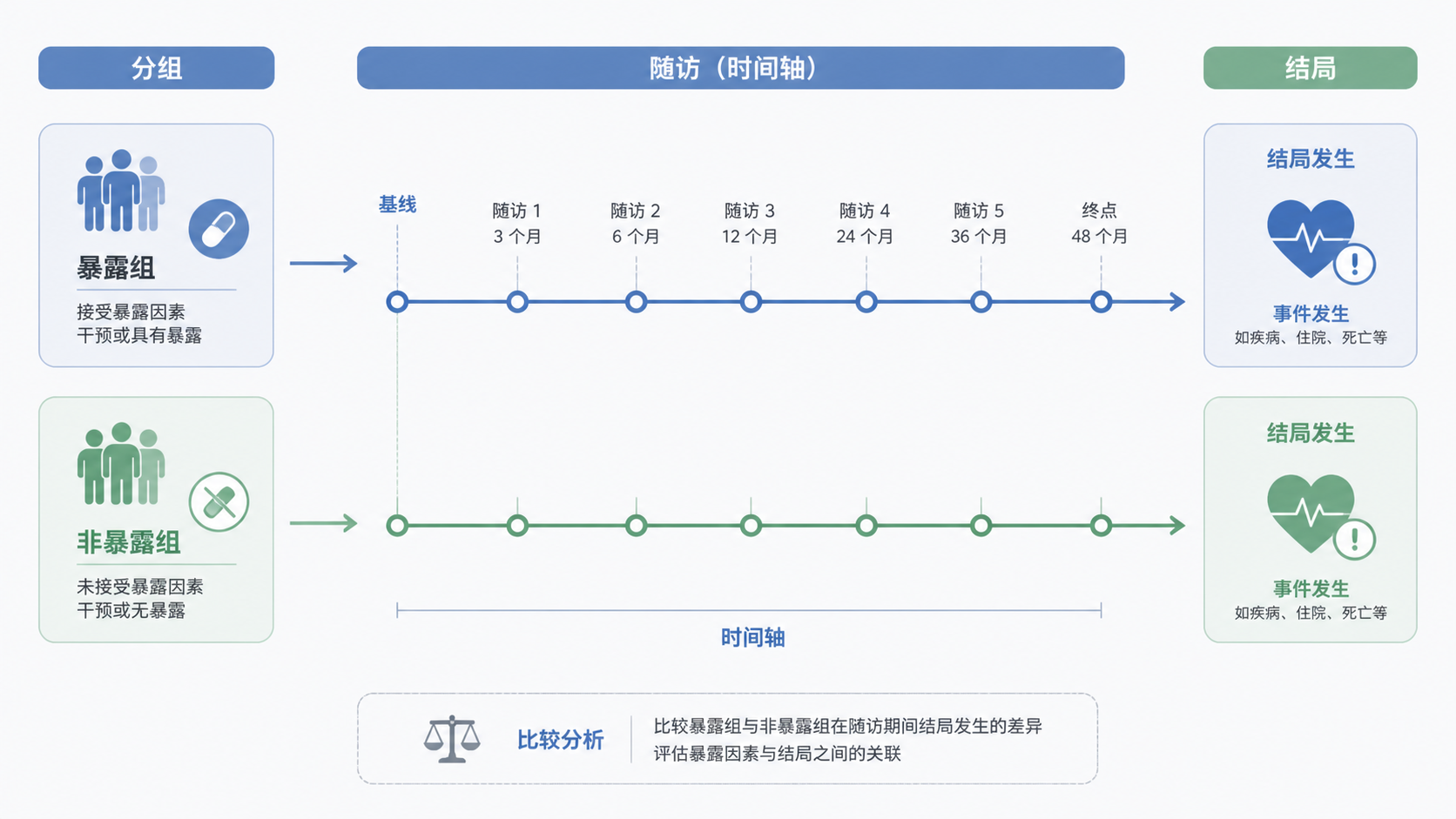
5. 关注随访设计,保证数据完整
5.1 随访决定统计质量
队列研究的统计结果,取决于随访是否完整。随访可以通过电话、门诊复查、问卷、医保数据库等方式完成。不同方式对应不同的成本和信息质量。
统计上要关注3件事:
- 随访起点是否统一。
- 随访终点是否明确。
- 结局记录是否一致。
如果起点和终点不统一,风险时间就不能正确计算。
5.2 风险人年为什么重要
在动态队列中,不同个体随访时间可能不同。此时不能只看人数,要看风险人年。风险人年是统计分析的重要基础,因为它能综合考虑“人”和“时间”。
这也是为什么很多队列研究会用人年发生率来比较不同组。它比单纯的累计发病数更适合不等随访时间的数据。
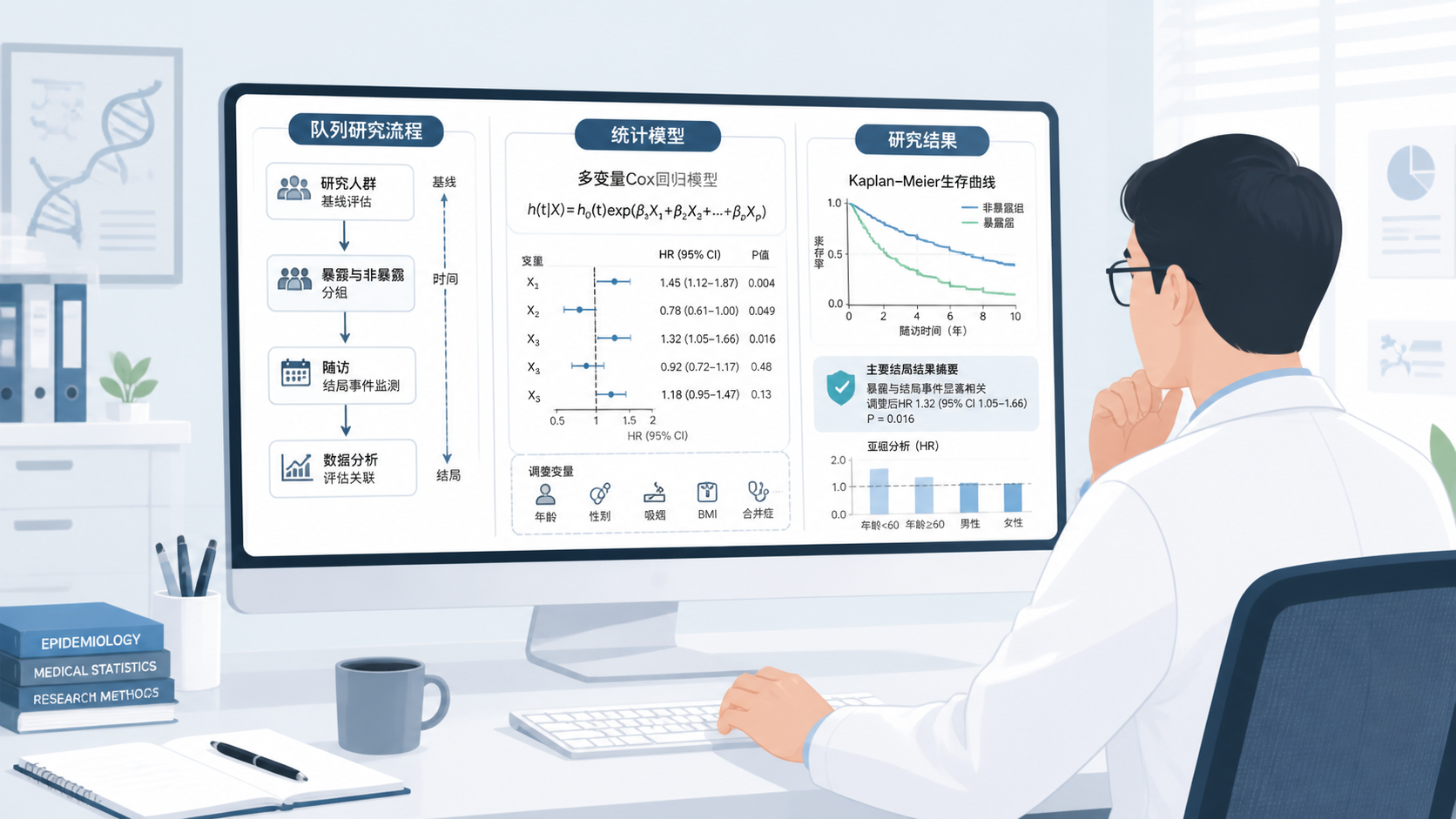
6. 选对统计指标和模型
6.1 最常用的统计指标
队列研究中,最常见的统计指标包括:
- 发生率。
- 风险比,RR。
- 率比或发生密度比。
- 风险比,HR。
- 95%可信区间。
其中,HR常用于随访数据和Cox比例风险模型 。如果是固定时间内的风险比较,RR也很常见。具体用哪一个,要看研究设计和数据结构。
6.2 多变量调整是标配
队列研究很少只做粗分析。因为混杂因素太常见。多变量模型的作用,是在统计上尽量控制年龄、性别、吸烟、饮酒、地区、既往史等因素。
常见做法是分层建模。例如:
- 先看未调整模型。
- 再调整人口学变量。
- 再进一步加入生活方式和病史变量。
如果加入关键混杂因素后关联明显减弱,说明原始关联可能受到混杂影响。 这在解读结果时必须客观。
7. 做好结果解释与敏感性分析
7.1 结果不能只看P值
队列研究统计基础不只是“出一个显著性结果”。更重要的是判断结果稳不稳。读者应同时看:
- 效应量大小。
- 95%可信区间。
- 是否存在剂量反应关系。
- 调整前后是否一致。
P值只能说明差异是否可能由随机误差造成,不能单独证明因果。
7.2 敏感性分析是提高可信度的关键
队列研究常通过敏感性分析验证稳健性。例如:
- 排除基线已有疾病者。
- 更换暴露分组方式。
- 更换统计模型。
- 对不同亚组分层分析。
如果不同分析方式下结论一致,证据会更稳。这是队列研究从“有结果”走向“可信结果”的关键一步。
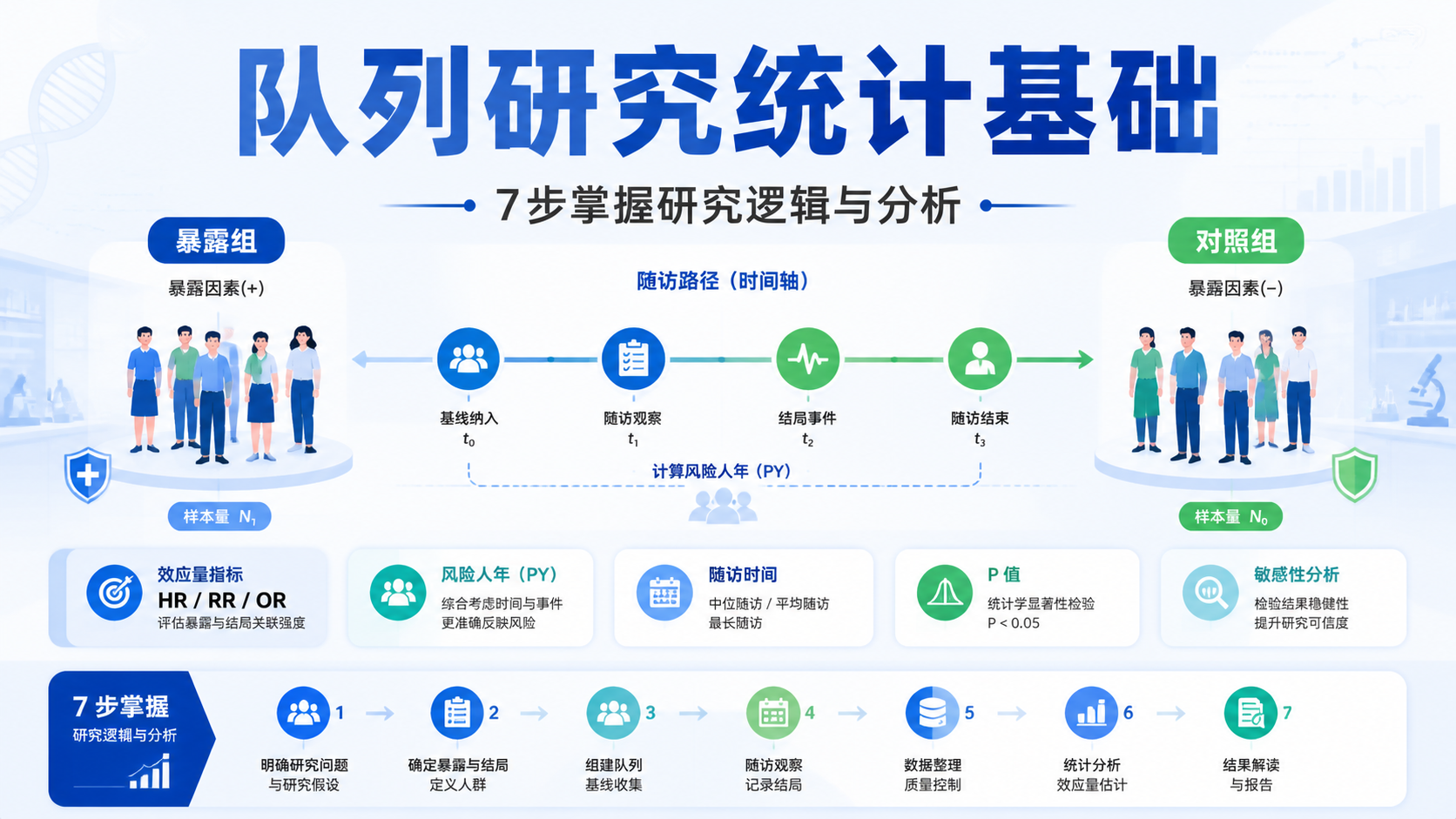
8. 用7步快速掌握队列研究统计基础
8.1 一张实用的入门清单
可以按下面7步理解和执行:
- 明确暴露因素。
- 明确主要结局。
- 设计分组和对照。
- 估算样本量并预留失访。
- 规划随访和风险时间。
- 选择合适统计指标和模型。
- 做多变量调整和敏感性分析。
这7步看似基础,但几乎决定了一项队列研究能否成立。统计做对了,结论才有解释价值。
8.2 解螺旋如何帮你少走弯路
在真实科研中,最常见的痛点不是不会跑模型,而是前期设计不完整,导致后面统计无法补救。解螺旋品牌的价值,就在于帮助你把队列研究的暴露、结局、随访、样本量和分析路径一次理顺。
如果你正在写课题、准备开题或整理论文数据,用解螺旋的研究设计与统计支持工具,可以更快定位变量、规范流程、减少返工。 这对医学生、医生和科研人员都非常实用。
总结Conclusion
队列研究统计基础,核心就是围绕暴露、结局、随访和混杂控制建立完整链条。只要把分组、样本量、风险时间、模型选择和敏感性分析这7步打通,队列研究就不再难入门。
真正高质量的队列研究,不是“会算”,而是“前后逻辑一致、统计路径清晰、结果能够被验证”。 如果你希望把课题做得更规范、更高效,可以进一步使用解螺旋品牌的科研支持服务,帮助你把队列研究从设计到统计一步做扎实。
- 引言Introduction
- 1. 先搞清楚队列研究的统计逻辑
- 2. 明确研究因素和结局变量
- 3. 设计分组与对照,保证可比性
- 4. 计算样本量,别只看“人越多越好”
- 5. 关注随访设计,保证数据完整
- 6. 选对统计指标和模型
- 7. 做好结果解释与敏感性分析
- 8. 用7步快速掌握队列研究统计基础
- 总结Conclusion