引言Introduction
队列研究暴露因素定义不清,常导致分组错误、偏倚增加、结论不稳。对医学生、医生和科研人员来说,真正难点不是“做队列研究”,而是先把暴露因素定义讲清楚、测准、分对。一旦暴露定义模糊,后续随访和统计都会失真。
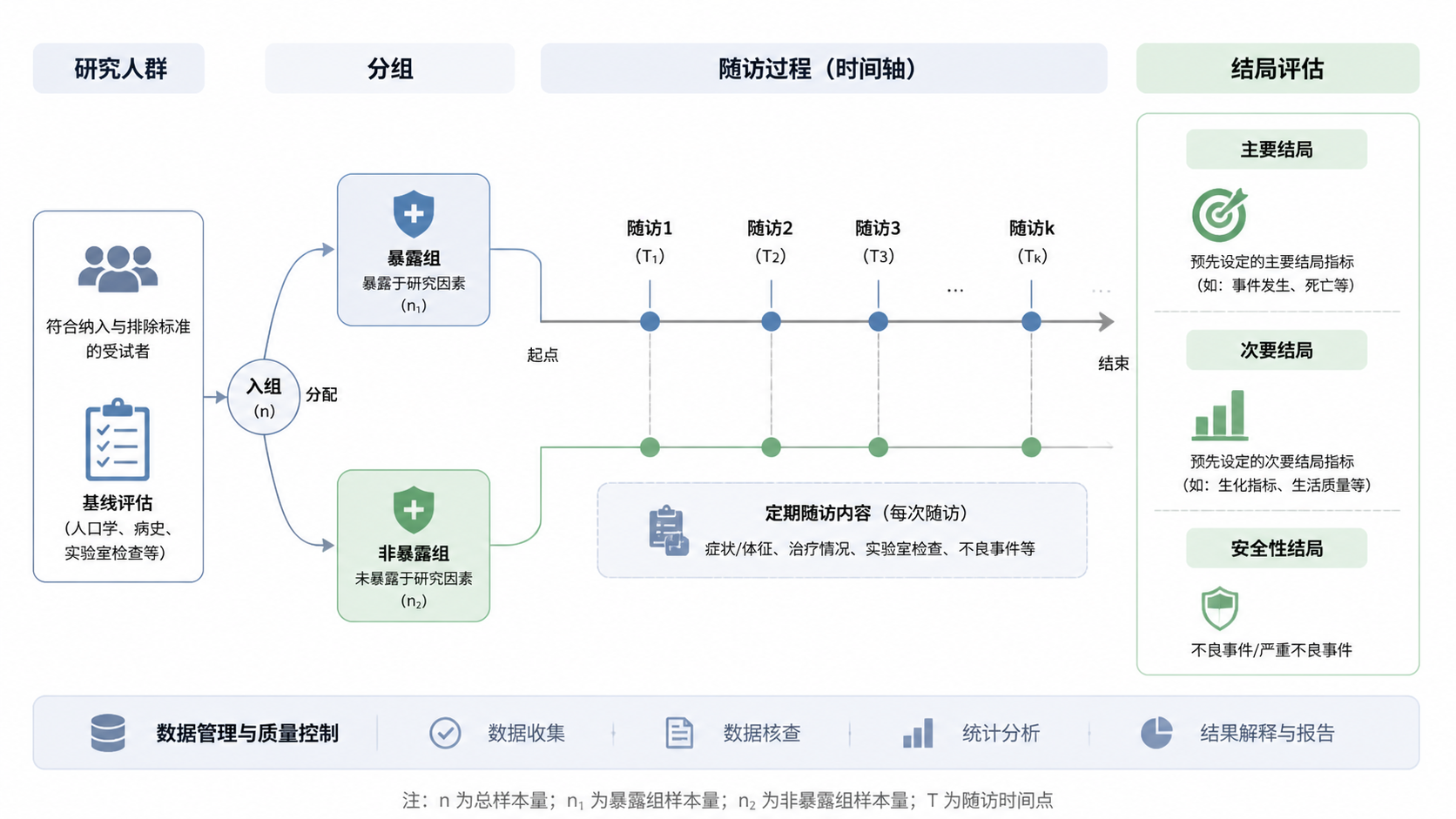
1. 先明确研究目的,再谈暴露因素
1.1 研究问题必须具体
队列研究暴露因素定义的第一步,不是急着列变量,而是先明确研究目的。你要回答的是:研究想验证哪一种暴露与哪一种结局之间的关系。
例如,研究“长期高血压是否增加卒中风险”,暴露因素就是高血压状态,结局是卒中发生。若目的不清,暴露就会被无限扩展,最后变成什么都想收集,什么都难分析。
1.2 目的决定暴露边界
暴露因素定义要和研究假设一致。若目标是病因推断,暴露应尽量指向时间上先于结局发生的因素。
定义越具体,后续分组越稳定。 这也是队列研究暴露因素定义的基础。
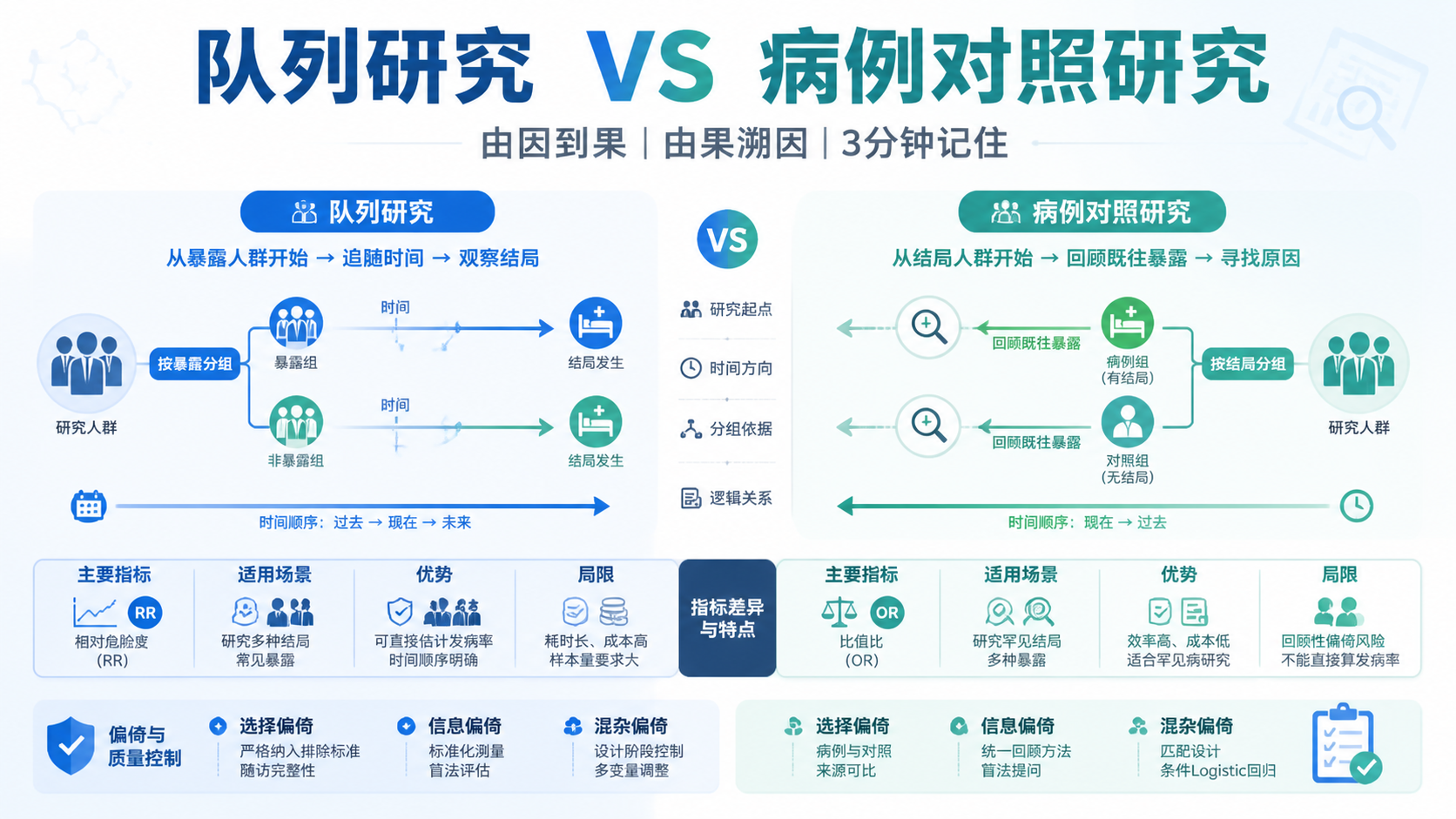
2. 选择适合的队列研究类型
2.1 前瞻性与回顾性队列的要求不同
前瞻性队列研究中,研究者先按暴露状态分组,再随访结局。上游知识库提示,这类研究要求:暴露明确、结局明确、样本足够、随访可完成。
回顾性队列研究则更依赖既有资料,因此暴露定义必须可从历史记录中稳定提取。
2.2 暴露必须“可识别、可记录”
队列研究暴露因素定义要满足两个条件:
- 能从病历、数据库或量表中识别。
- 能被不同研究者以相同规则重复判断。
如果暴露只能靠主观回忆,或记录缺失严重,分组可靠性就会下降。这不是统计问题,而是定义问题。
3. 明确研究对象与纳排标准
3.1 先定人群,再定暴露
队列研究暴露因素定义不能脱离研究对象。你需要先确定纳入谁,排除谁。上游知识库强调,研究对象应具有代表性和可比性,最好诊断明确,并尽量完整纳入。
例如,研究妊娠期子痫前期与新生儿结局时,研究对象应先限定为明确诊断的妊娠人群。人群不统一,暴露解释就会混乱。
3.2 识别会影响暴露判断的因素
纳排标准还要考虑是否存在:
- 无法获得完整暴露资料的病例。
- 可能导致严重失访的病例。
- 无法发生目标结局的病例。
研究对象不清,暴露定义再精细也没有意义。 这是队列研究暴露因素定义中最容易被忽略的一步。
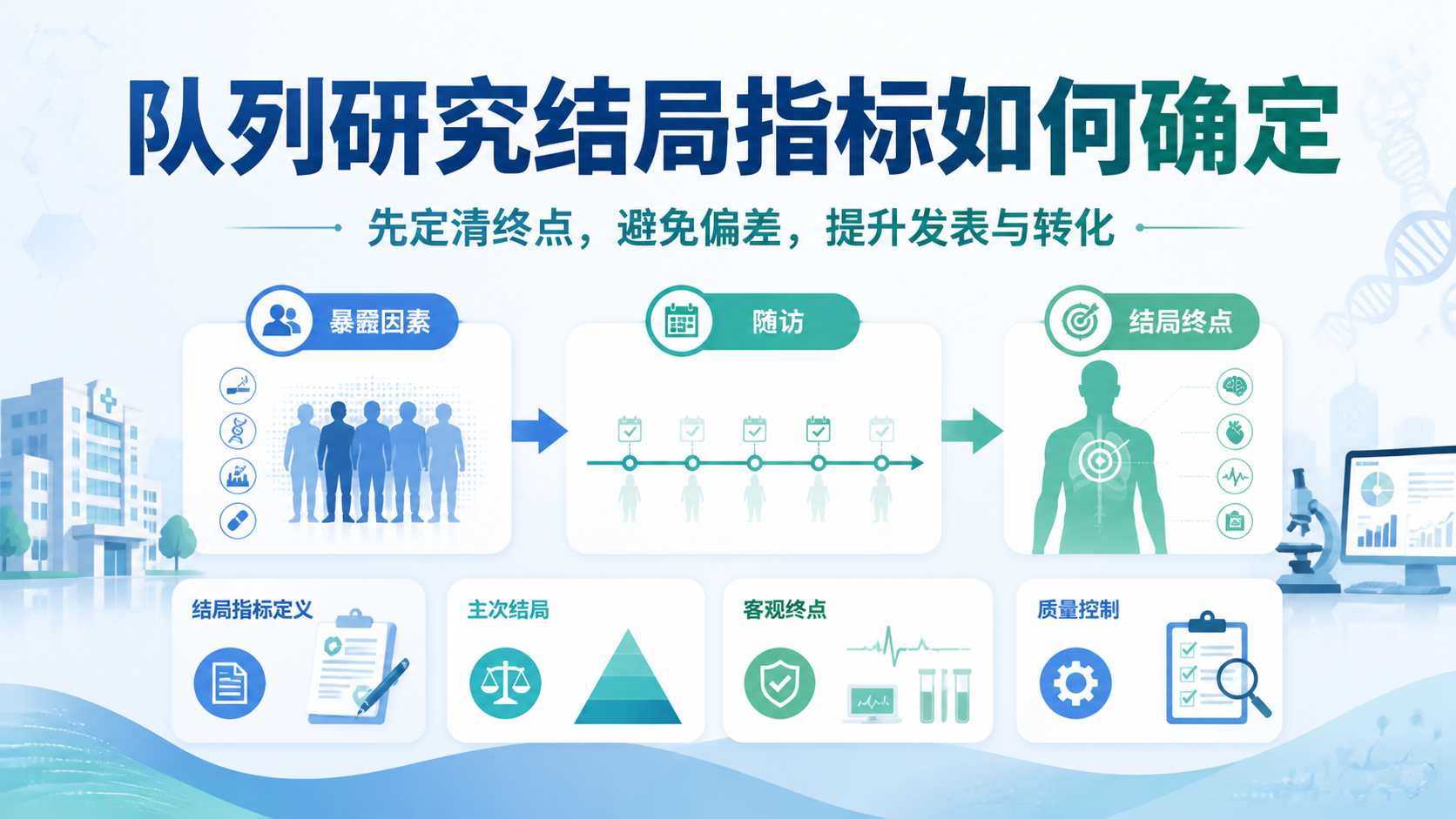
4. 给暴露下一个可操作的定义
4.1 定义要客观、特异、稳定
上游知识库提到,研究指标应尽量选择客观指标,特异性高、灵敏性好、精确度高、稳定可靠。这个原则同样适用于暴露因素定义。
例如,不要只写“吸烟”。更好的写法是:
- 当前吸烟。
- 既往吸烟。
- 吸烟量达到某个阈值。
- 持续时间超过某个年限。
暴露定义必须能落到操作层面。 否则不同中心、不同研究者会有不同解释。
4.2 设定时间窗和剂量阈值
队列研究暴露因素定义通常要写清楚:
- 暴露发生时间。
- 暴露持续时间。
- 暴露强度或剂量。
- 是否存在累计暴露。
这对剂量反应分析尤其重要。若不设阈值,就很难判断暴露与结局是否存在生物梯度。
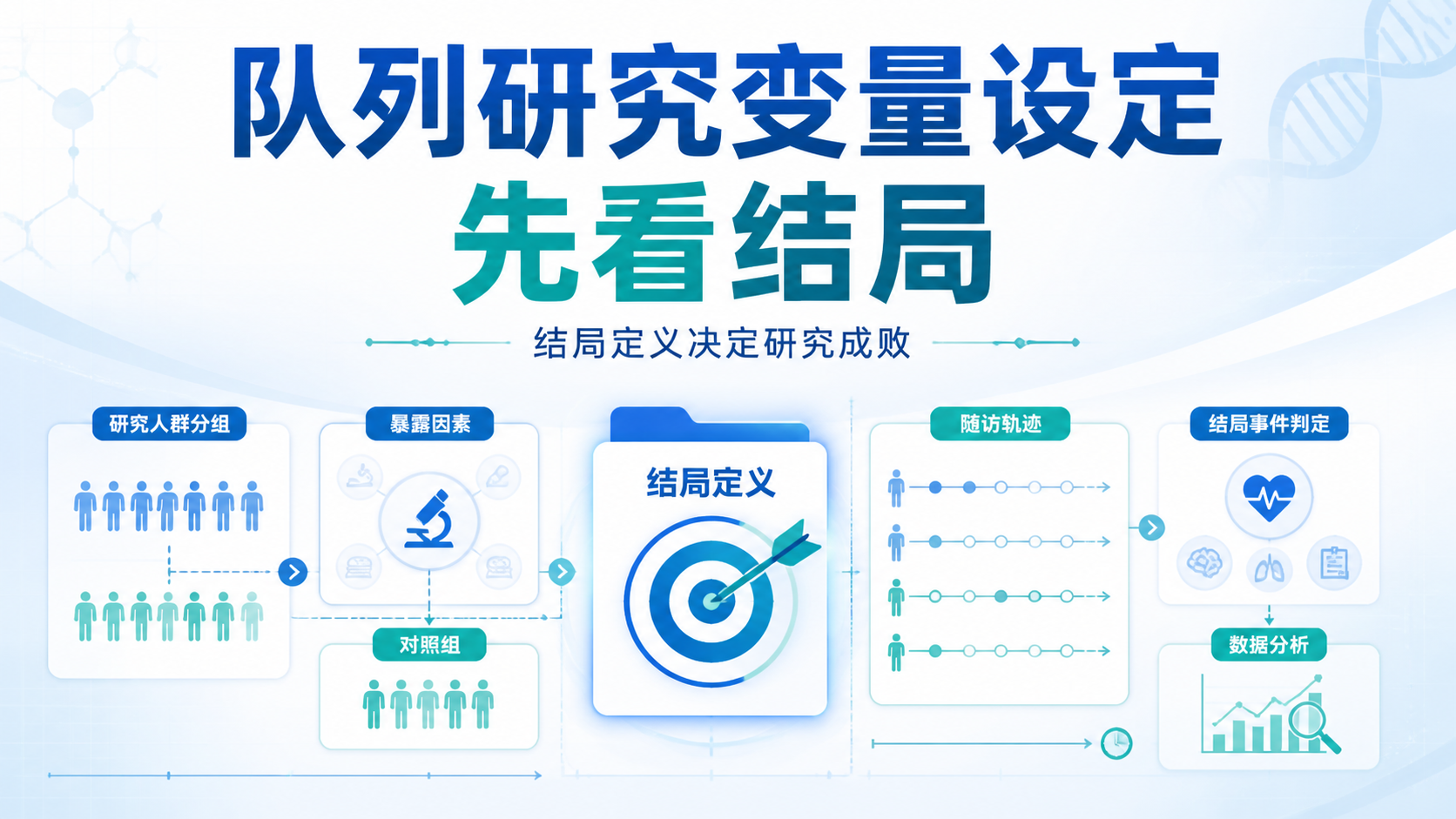
5. 规范暴露组与非暴露组的划分
5.1 分组规则必须预先写死
暴露组和对照组怎么分,必须在研究开始前就定义清楚。不能等结果出来再改分组。
这是避免选择偏倚的关键。
例如,药物暴露研究中,暴露组应是达到既定用药标准者,对照组应是未暴露或低暴露者。若中途改规则,结果容易失真。
5.2 注意分组平衡与可比性
上游知识库指出,研究对象需要具有可比性。队列研究暴露因素定义也要考虑混杂因素。
常见做法包括:
- 限制纳入范围。
- 分层分析。
- 倾向评分方法。
- 多因素回归校正。
暴露组与对照组的可比性,决定了结论的可信度。
6. 选择可靠的暴露测量方式
6.1 优先使用客观来源
回顾性研究中,暴露信息最好来自:
- 电子病历。
- 检验检查结果。
- 药房或处方记录。
- 标准化量表。
- 结构化数据库。
这些来源比单纯回忆更稳定。上游知识库强调,资料收集要尽可能完整、如实记录,这正是减少信息偏倚的核心。
6.2 统一测量标准
如果暴露来自多个中心或多个记录者,必须提前统一判定规则。
建议明确:
- 记录口径。
- 测量时间点。
- 缺失值处理方式。
- 重复测量时取值原则。
同一个暴露,必须用同一把尺子量。 这也是队列研究暴露因素定义能否复现的关键。
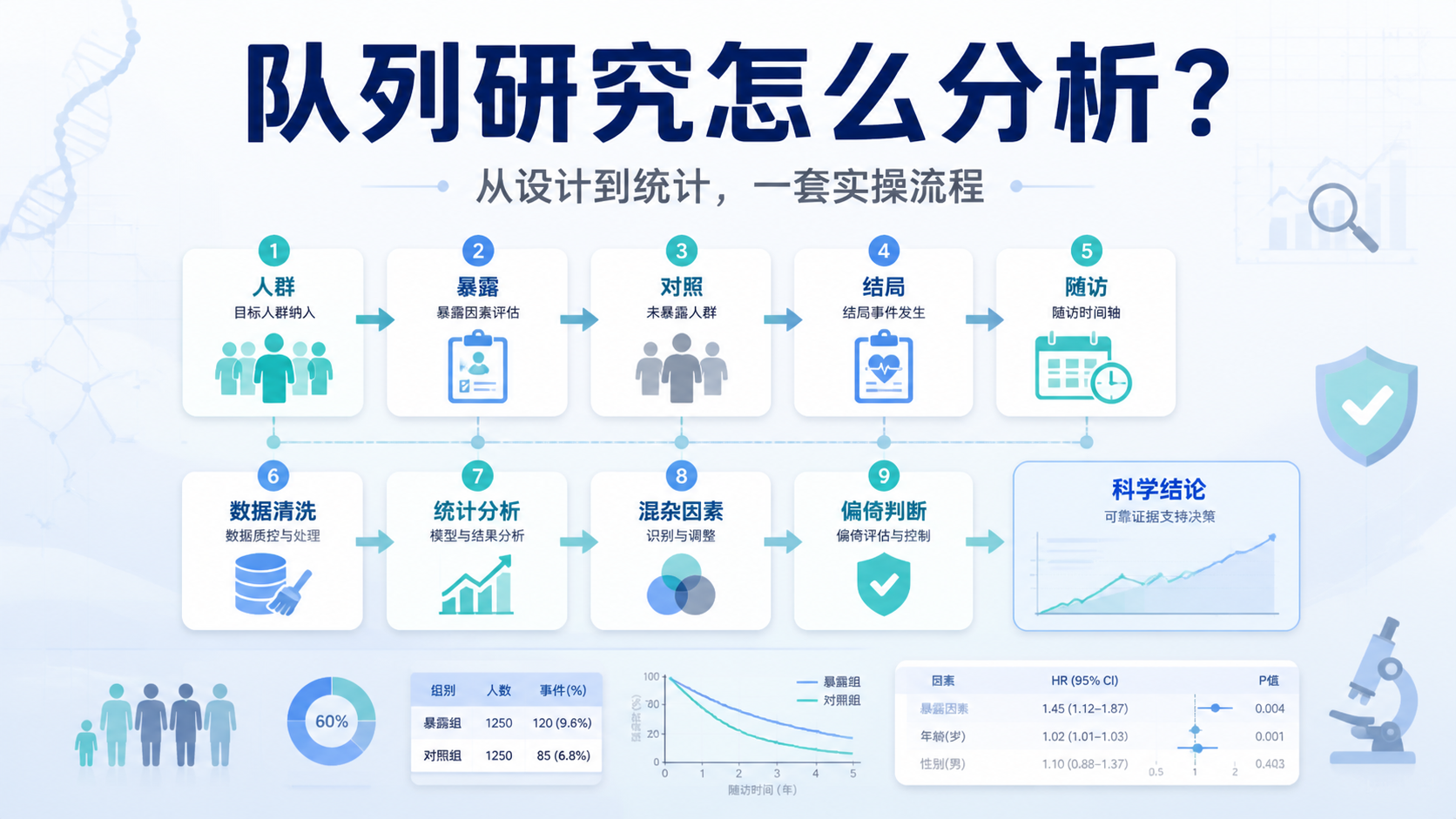
7. 做好偏倚控制和统计前置设计
7.1 先想偏倚,再做分析
上游知识库明确指出,回顾性研究必须妥善控制误差和偏差。对于暴露因素定义,最常见的风险包括:
- 选择偏倚。
- 信息偏倚。
- 混杂偏倚。
- 失访偏倚。
如果暴露定义过宽,会造成误分组。若过窄,则可能降低样本量和统计效能。
7.2 让统计方法服务于定义
在设计阶段就要考虑分析方法是否匹配暴露定义。
常见思路包括:
- 二分类暴露。
- 多分类暴露。
- 连续暴露。
- 时间依赖性暴露。
先定义,再分析。不要倒过来。 这句话几乎适用于所有队列研究暴露因素定义场景。
3 个最容易出错的地方
3.1 把“暴露”写成笼统概念
例如,只写“生活方式不良”或“存在危险因素”。这种定义无法直接用于分组。
3.2 忽略暴露发生顺序
队列研究强调时间顺序。暴露必须先于结局,否则无法支持因果推断。
3.3 只看有没有暴露,不看暴露强度
很多研究只做“有/无”二分,忽略剂量、时长、频率。这样虽然简单,但容易损失信息。
队列研究暴露因素定义越精确,研究越接近真实世界。
总结Conclusion
队列研究暴露因素定义的核心,不是写一个名字,而是把研究目的、人群、分组、测量、时间窗、偏倚控制和分析逻辑全部串起来。对医学生和科研人员来说,真正高质量的队列研究,往往赢在定义阶段,而不是结果阶段。
如果你正在准备回顾性或前瞻性队列研究,建议优先把暴露定义、纳排标准和数据提取规则一次性理顺。这样才能减少误分组,提高结论可信度。

如果你希望把队列研究暴露因素定义写得更规范、更适合投稿,可以借助解螺旋品牌的科研写作与研究设计支持 ,把选题、变量定义和统计框架一步到位地梳理清楚。
- 引言Introduction
- 1. 先明确研究目的,再谈暴露因素
- 2. 选择适合的队列研究类型
- 3. 明确研究对象与纳排标准
- 4. 给暴露下一个可操作的定义
- 5. 规范暴露组与非暴露组的划分
- 6. 选择可靠的暴露测量方式
- 7. 做好偏倚控制和统计前置设计
- 3 个最容易出错的地方
- 总结Conclusion