引言Introduction
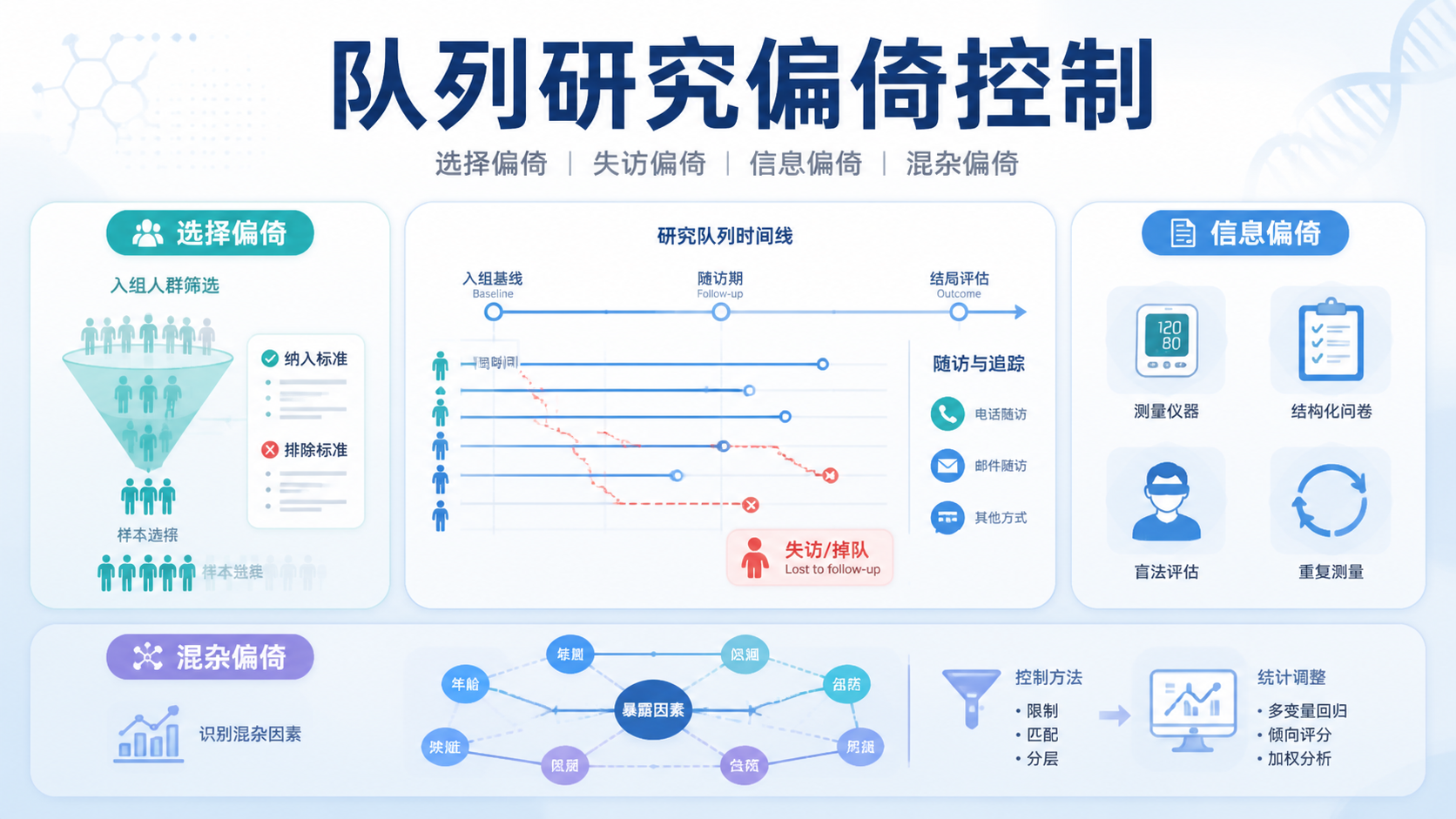
队列研究常用于回答“暴露是否会影响结局”。但实际操作中,队列研究偏倚控制 做不好,结论就可能偏离真实。对医学生、医生和科研人员来说,最常见的难点是选择偏倚、失访偏倚、信息偏倚和混杂偏倚。
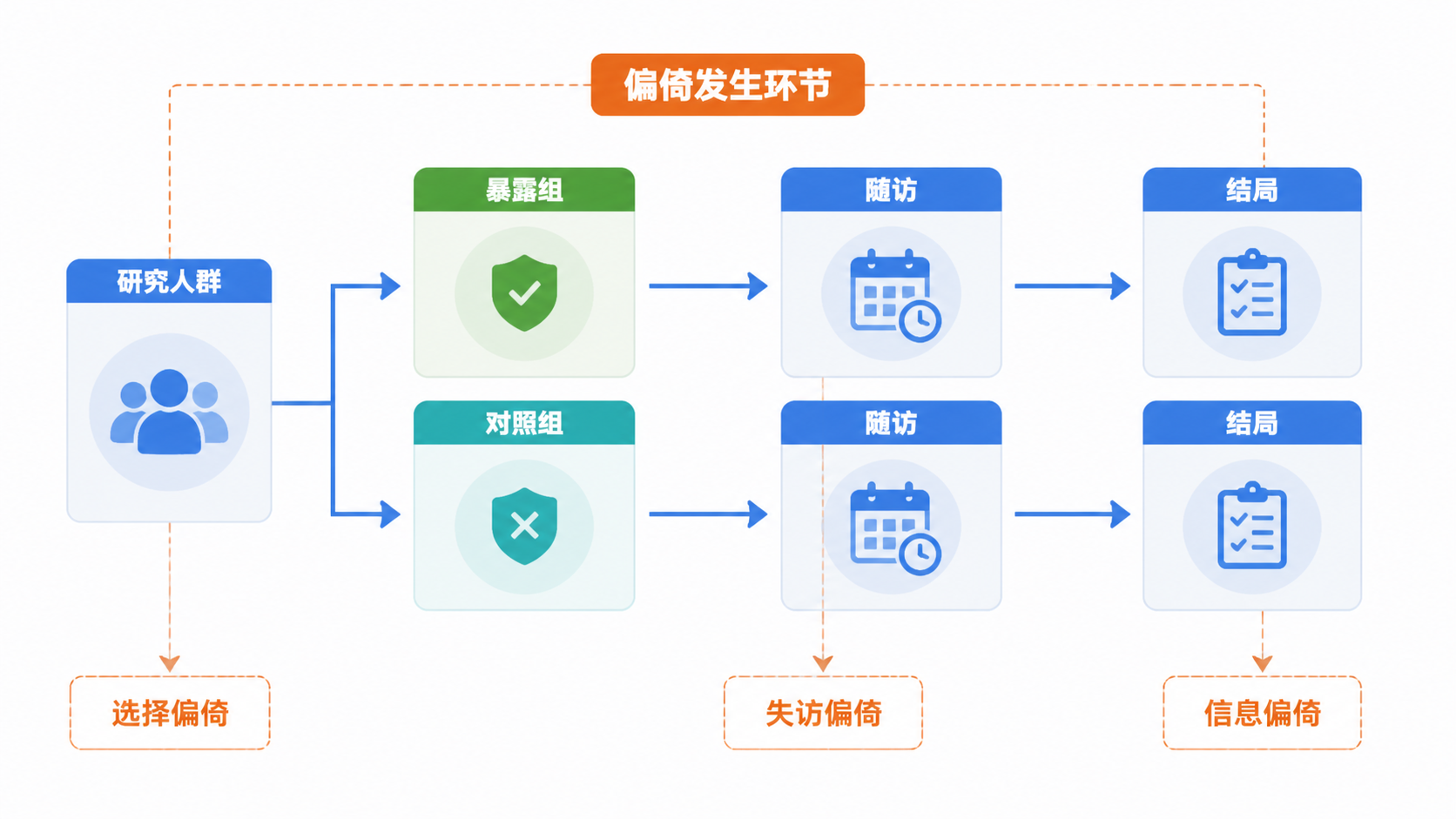
1. 先识别队列研究中的主要偏倚
1.1 选择偏倚最先发生在入组阶段
队列研究的偏倚,很多从“研究对象选错了”开始。如果暴露组不能代表暴露人群,对照组不能代表非暴露人群,结果就会失真。 这类问题常见于纳入标准过宽或执行不严格,也常见于志愿者偏差、档案缺失、拒绝参加等情形。
历史性队列研究还要特别注意资料完整性。档案丢失、记录不全,会让进入分析的人群与真实总体不一致。此时,即使后续统计方法正确,研究结果也可能已经被系统性扭曲。
1.2 失访偏倚会在长随访中放大
队列研究的特点是随访时间长,样本量大。随访越长,失访越难避免。 如果暴露组和对照组失访比例不同,或者失访者和未失访者的发病风险不同,就会产生失访偏倚。
知识库中明确指出,当失访率超过5%时,就应进一步分析偏倚影响;当失访率达到20%以上,研究真实性就值得怀疑。对队列研究偏倚控制来说,这是一个非常重要的警戒线。
2. 方法一:用正确设计减少选择偏倚
2.1 严格纳入和排除标准
控制选择偏倚,核心是让研究对象“可比且有代表性”。最直接的方法,是在设计阶段设定清晰、可执行的纳排标准。标准越模糊,执行越容易漂移。
常见做法包括:
- 先明确目标人群,再抽取研究对象。
- 严格区分暴露组和对照组。
- 排除明显不符合研究目的的对象。
- 对拒绝参加者进行基本特征比较。
如果拒绝参加者与纳入者在年龄、性别、疾病史等关键变量上差异明显,偏倚风险就更高。研究开始前把这些风险识别出来,比事后补救更有效。
2.2 提高应答率和依从性
队列研究偏倚控制不能只停留在设计图上,还要落到执行。提高应答率和依从性,是降低选择偏倚和失访偏倚的基础。
可操作的策略包括:
- 选择相对稳定的人群。
- 设置合理随访频率。
- 提供便利的复诊和随访方式。
- 建立联系方式更新机制。
- 对随访人员进行统一培训。
稳定、连续、可追踪的人群,往往比“样本量很大但很难随访”的人群更适合队列研究。
3. 方法二:把失访偏倚控制在可接受范围内
3.1 先减少失访,再谈统计补救
失访偏倚本质上也属于选择偏倚。知识库强调,控制失访偏倚的最好方法,始终是尽量减少失访。 这比事后做统计修正更关键。
实际中可以这样做:
- 选择稳定居住、流动性较低的人群。
- 随访时间设置合理,避免过长。
- 提供电话、短信、网络等多渠道随访。
- 对可能退出研究的人提前干预。
- 保持研究联系频率,提升参与感。
这些措施虽然基础,但非常有效。因为队列研究一旦出现大量失访,后续分析再精细,也难完全恢复原始信息。
3.2 用基线信息判断失访影响
如果失访已经发生,可以通过两类信息判断其影响。
第一,查询失访者是否死亡及死亡原因。若失访者与未失访者的死亡模式相近,可推测偏倚较小。
第二,比较失访者与未失访者的基线特征。两者越相似,发生不同结局的可能性越低。
但要注意,这些方法只是推测,不是测量。 它们不能替代真正的追踪管理。若失访率超过20%,即便采用统计方法,也应谨慎解释结论。
4. 方法三:提升测量质量,避免信息偏倚
4.1 统一标准,减少错分
信息偏倚来自暴露、结局或其他变量的测量误差,也叫错分偏倚。常见原因包括仪器不精确、测量方法不稳定、记录错误、诊断标准不清、调查员培训不足等。
队列研究偏倚控制中,信息偏倚最怕“标准不统一”。
例如,同一研究里,不同中心对暴露定义不一致,或不同医生对结局判断不一致,都会让结果失真。
建议在研究启动前完成以下工作:
- 明确暴露和结局定义。
- 制定标准操作流程。
- 统一测量工具和判定标准。
- 定期校准仪器。
- 对调查员和评估者进行培训。
4.2 盲法和重复测量很重要
在条件允许时,尽量让结局评估者不知道研究对象的暴露状态。这样可以减少主观判断带来的偏差。对于实验室检测、临床评分、影像判读等场景,盲法尤其有价值。
此外,还可对随机样本进行重复测量或重复调查,比较两次结果的一致性,以评估偏倚大小。如果重复结果差异较大,就说明测量系统本身可能不稳定。 这类问题越早发现,损失越小。
5. 方法四:识别并控制混杂偏倚
5.1 混杂变量必须同时满足两个条件
混杂偏倚是队列研究里最容易被低估的问题之一。它指的是某个第三变量同时与暴露和结局有关,从而歪曲二者关系。常见混杂因素包括年龄、性别等。
一个变量要成为混杂因素,通常要满足两点:
- 它是结局的影响因素。
- 它与暴露因素有关联。
如果只满足其中一点,就不一定构成混杂。混杂偏倚控制的关键,不是“见到相关就处理”,而是先判断它是否真正符合混杂条件。
5.2 设计阶段优先控制,分析阶段再调整
知识库提示,混杂偏倚可以在设计阶段和分析阶段双线处理。
设计阶段常用方法有:
- 随机化。
- 限制。
- 匹配。
分析阶段常用方法有:
- 分层分析。
- 标准化。
- 多因素分析。
其中,随机化是控制混杂最强的方法之一,但更常见于RCT。队列研究中,限制和匹配更常用。比如在设计时限定年龄范围,或按性别、年龄进行匹配,都能提高两组可比性。
如果研究已经完成,分层分析和多因素模型是更现实的补救手段。但要记住,统计调整只能减轻混杂,不能替代前期设计。
6. 队列研究偏倚控制的实用执行框架
6.1 从立项到分析的4步检查
要把队列研究偏倚控制 做扎实,建议按流程逐步检查:
- 立项前,确认目标人群和暴露定义。
- 入组前,检查纳排标准和抽样策略。
- 随访中,持续监测失访率和测量一致性。
- 分析时,评估混杂并做分层或多因素调整。
这个框架的价值在于,它把偏倚控制从“单个技巧”变成“全流程管理”。
6.2 先看研究真实性,再看统计显著性
队列研究最怕的是“统计上显著,方法上不可靠”。如果选择偏倚严重、失访过多、测量不一致,再漂亮的P值也不可信。
E-E-A-T导向的研究写作,不只是报告结果,更要说明结果为什么可信。
因此,论文中应主动交代:
- 纳入和排除过程。
- 失访比例及处理方式。
- 主要变量的测量方法。
- 混杂因素的控制策略。
这类信息越完整,研究越容易被同行认可。
总结Conclusion
队列研究偏倚控制,核心就是四件事。防选择偏倚,控失访偏倚,降信息偏倚,识别并调整混杂偏倚。 其中,设计阶段的规范性最重要,执行阶段的连续性最关键,分析阶段的透明性最必要。

如果你正在撰写队列研究方案、论文方法学部分,或需要系统梳理偏倚控制逻辑,建议使用解螺旋 的临床研究与论文写作资源,帮助你更高效地完成研究设计、数据分析和结果表达,让队列研究偏倚控制真正落实到可发表的质量标准。
- 引言Introduction
- 1. 先识别队列研究中的主要偏倚
- 2. 方法一:用正确设计减少选择偏倚
- 3. 方法二:把失访偏倚控制在可接受范围内
- 4. 方法三:提升测量质量,避免信息偏倚
- 5. 方法四:识别并控制混杂偏倚
- 6. 队列研究偏倚控制的实用执行框架
- 总结Conclusion