引言Introduction
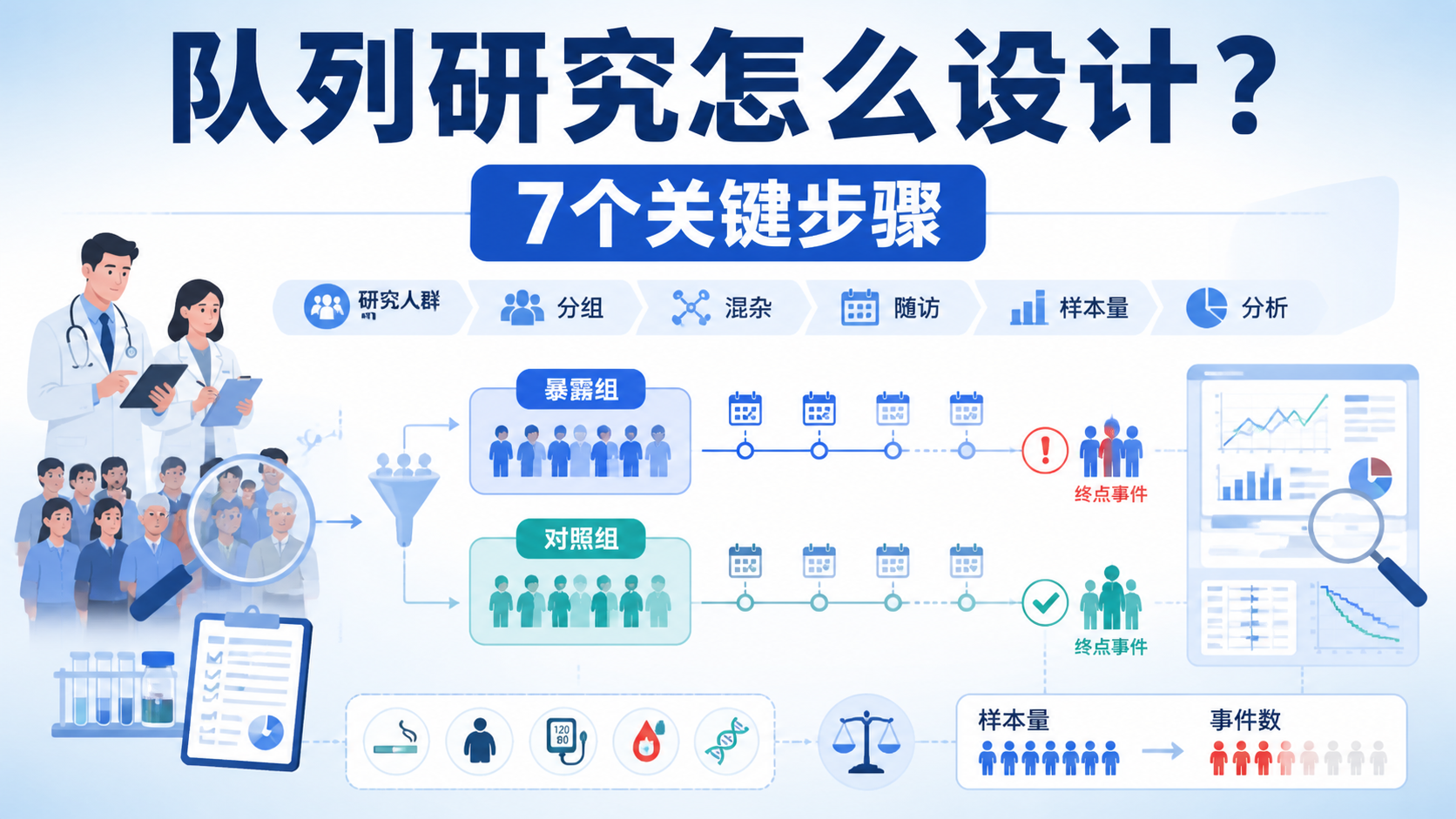
队列研究设计看似复杂,核心却很清晰。很多医学生和科研人员在选题时,常卡在暴露、结局、随访和偏倚控制上,导致研究方案反复修改。掌握队列研究设计的7个步骤,才能把因果推断做扎实。
1. 明确研究问题与暴露结局
1.1 先把因果链条写清楚
队列研究设计的第一步,不是找数据,而是定义问题。要明确暴露因素是什么,结局是什么。两者必须符合临床逻辑。比如饮茶量与癌症风险,饮茶量是暴露,癌症发生是结局。
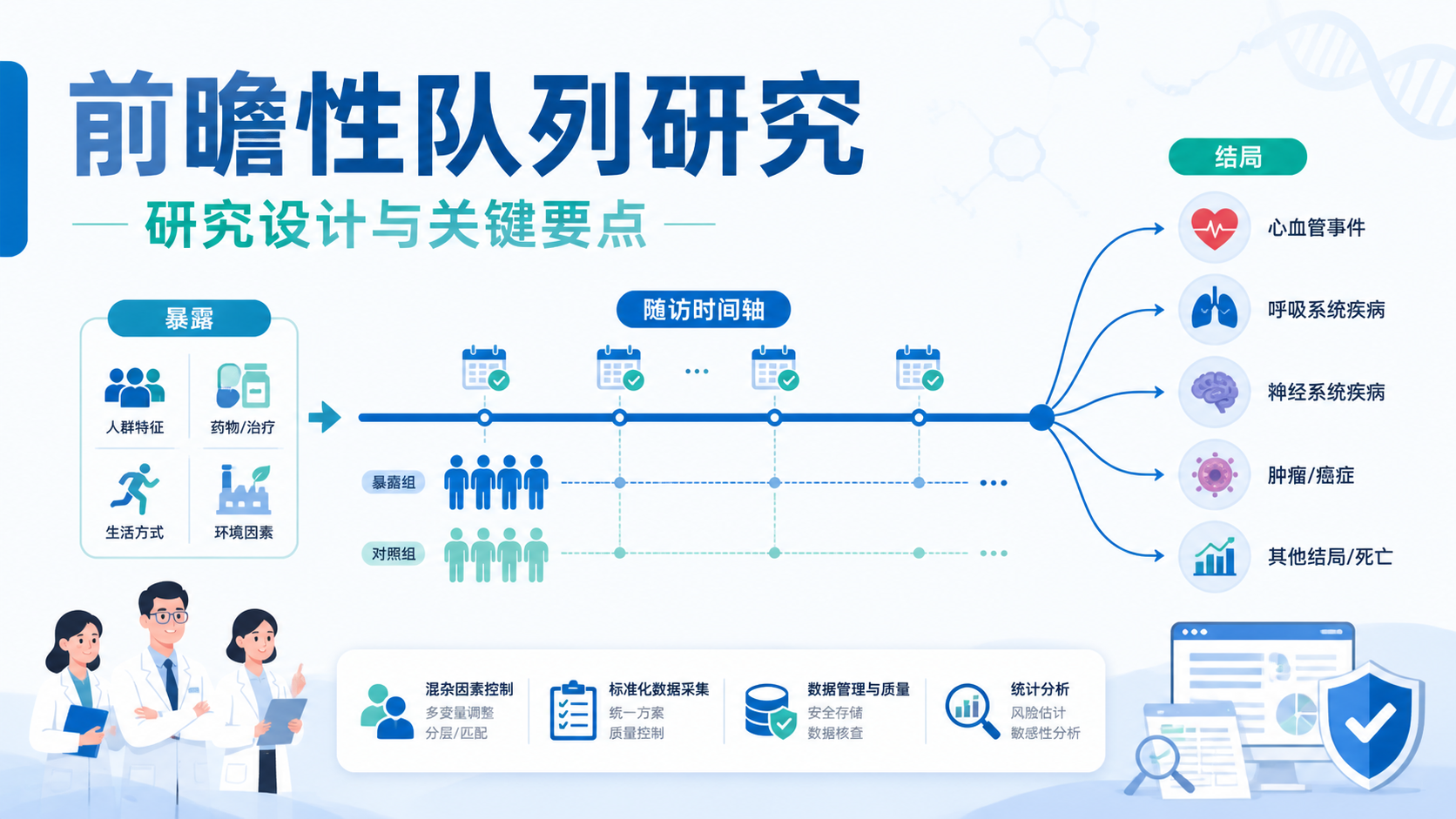
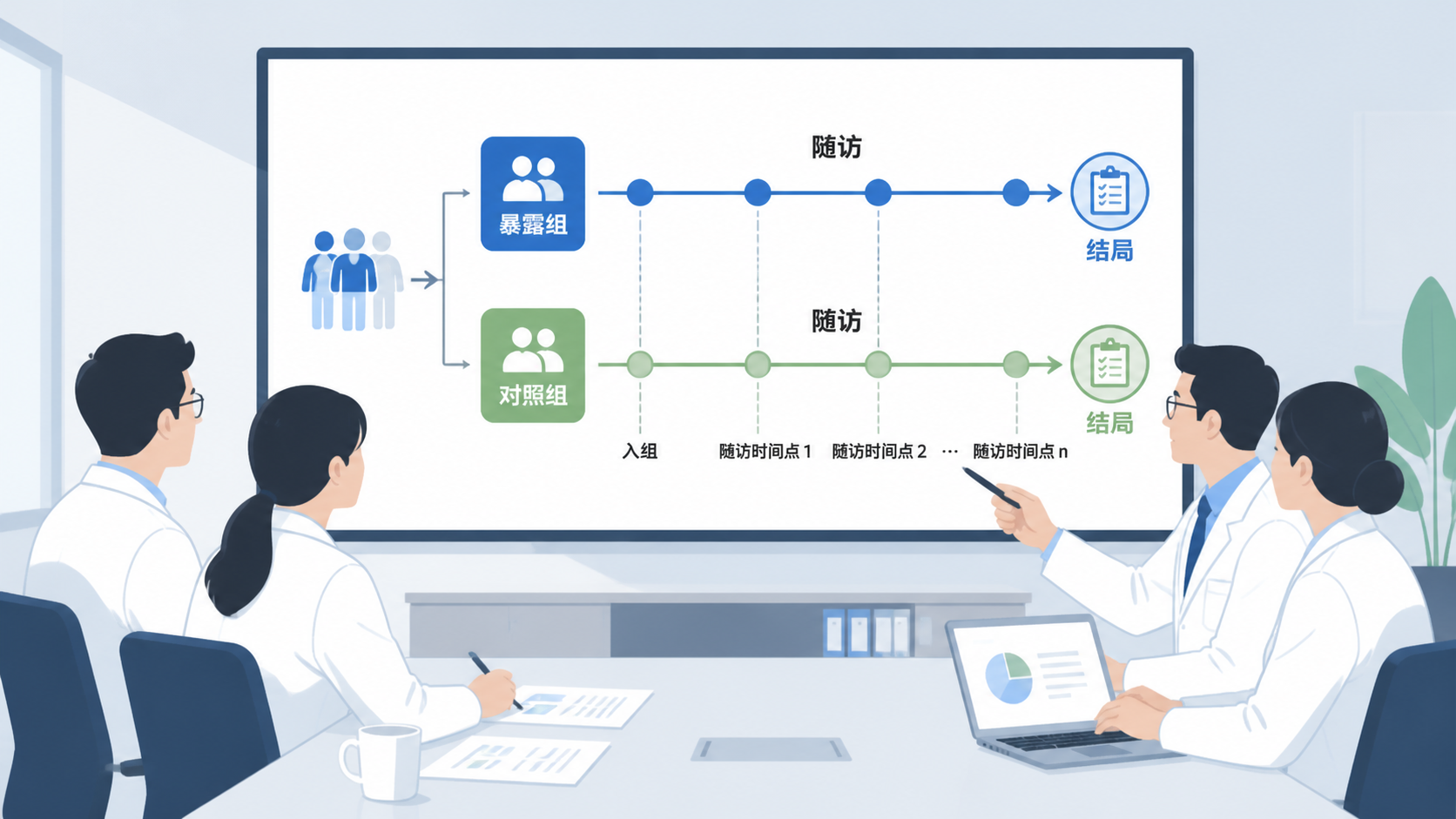
队列研究设计的价值,在于直接观察暴露后结局是否发生。 这种设计属于分析流行病学,通常按暴露状态分组,再随访结局。
1.2 结局变量要可观察、可登记
结局变量可以是疾病、死亡,或某些实验室指标和健康状态变化。关键是要可定义、可追踪、可记录。若结局过于主观,后续分析会很难稳定。
实际操作中,最好先确定主要结局,再考虑次要结局。这样能避免研究范围过宽,也更利于样本量估算和统计分析。
2. 选择研究人群与研究现场
2.1 研究现场要有代表性和可行性
队列研究设计对现场要求很高。研究现场必须有足够数量的目标人群,还要具备较好的随访条件。交通便利、管理支持到位、群众配合度高,都会影响研究质量。
如果现场样本不足,或者失访风险过高,队列研究设计很容易失败。 这是很多初学者最容易忽略的一点。
2.2 纳入对象应满足随访前提
研究对象通常需要满足几个基本条件。
- 进入队列时未出现结局。
- 随访期间有可能发生结局。
- 暴露或发病水平不能过低。
- 研究人群应具备可操作性。
这些条件看似基础,但直接决定了研究能否回答科学问题。若对象本身不可能发生结局,队列研究设计就失去了意义。
3. 划分暴露组与对照组
3.1 分组标准必须稳定
队列研究设计的关键是按暴露状态分组。常见分法包括暴露组与非暴露组,高剂量组与低剂量组。分组标准要清楚,最好可量化,避免模糊定义。
例如某因素存在剂量反应关系时,可以进一步细分暴露水平。这样更有利于观察趋势,也能提高结果解释力。
3.2 对照组的作用不只是比较
对照组不是摆设。它决定了研究能否进行相对风险比较。队列研究常用于计算发病率、相对危险度和风险比。没有合理对照,因果关联就很难成立。
对照组的选择,应尽量保证与暴露组在基线特征上可比。 这样可以减少混杂影响,也能提高证据强度。
4. 识别混杂因素并提前收集
4.1 混杂因素要在设计阶段考虑
队列研究设计不是只看一个暴露和一个结局。还要提前识别可能影响结局的其他因素,如年龄、性别、吸烟、饮酒、既往史、家族史等。上游知识库中的研究也收集了这些协变量,并用于模型调整。
如果不在基线阶段收集混杂因素,后期再补救会非常被动。很多偏倚一旦漏掉,就很难完全修正。
4.2 协变量收集应尽量完整
资料收集越规范,后续分析越稳健。尤其在真实世界研究中,基线资料往往直接决定模型质量。高质量的队列研究设计,离不开完整的协变量信息。
在统计分析时,这些变量常进入多变量模型,用于校正暴露与结局之间的关系。这样得到的结果,才更接近真实效应。
5. 设定随访方案与终点
5.1 随访是队列研究的核心环节
队列研究设计通常是由因到果。研究对象分组后,需要随访一段时间,观察结局是否发生。随访方式可以是定期复查、病历登记或数据库链接。
随访时间越清晰,结局判定越准确。 终点应尽量客观,比如首次发病、死亡、明确诊断,或实验指标达到预设阈值。
5.2 失访控制必须前置
队列研究费时、费力、费钱,失访是常见风险。上游课程提到,实际设计时常按10%失访率预留样本量。这个经验值很实用,也说明样本量不能只按理论值计算。
随访方案要写清楚频率、终点、联系机制和数据来源。若随访链条不完整,结果偏倚会明显增加。
6. 估算样本量并保证统计效能
6.1 样本量决定研究能否跑通
队列研究设计一次通常只针对一个主要因素,因此样本量估算更重要。样本太小,可能看不到差异。样本太大,则会增加成本和实施难度。
在正式研究前,应根据主要结局、预期效应量、事件发生率和失访率进行估算。若研究还计划做分层分析,样本量要求会更高。
6.2 事件数比单纯样本数更重要
很多科研人员只盯着总样本量,但队列研究更看重结局事件数。没有足够事件数,模型不稳,HR或RR的置信区间也会变宽。
因此,队列研究设计不仅要“有人”,还要“有事件”。 这直接关系到证据强度和发表质量。
7. 选择合适的分析方法与报告结果
7.1 统计分析要与研究问题匹配
队列研究常用发病率、相对危险度、风险比和Cox比例风险模型。若数据来源于动态随访队列,还需要计算人年。分析时应根据结局类型和随访结构,选择合适模型。
如果研究涉及多个协变量,建议先做基线特征比较,再做单因素和多因素分析。必要时,还可进行分层分析和敏感性分析,以检验结果稳健性。
7.2 结果解释要回到临床问题
好的队列研究设计,不只在于统计显著,更在于临床解释合理。结果应明确说明:暴露是否增加风险,风险增幅多大,是否存在剂量反应,调整混杂后是否仍成立。
上游案例中,研究者通过多变量模型和分层调整,观察饮茶与多种癌症风险的关系,并最终区分出哪些结局有关联,哪些没有统计学意义。这种分析路径,正是队列研究设计的典型实践。
总结Conclusion
队列研究设计的7步,可以概括为:明确问题,选好人群,划分分组,控制混杂,设定随访,估算样本量,完成分析。每一步都紧扣因果推断,也都影响最终证据质量。真正高质量的队列研究设计,靠的不是数据堆积,而是前期方案的严谨。
如果你正在做临床研究选题、伦理申报或论文设计,建议借助更成熟的工具和方法提高效率。解螺旋品牌提供的研究设计与数据分析支持,能帮助你更快理清暴露、结局、协变量与统计路径,减少返工,提升研究可发表性。
- 引言Introduction
- 1. 明确研究问题与暴露结局
- 2. 选择研究人群与研究现场
- 3. 划分暴露组与对照组
- 4. 识别混杂因素并提前收集
- 5. 设定随访方案与终点
- 6. 估算样本量并保证统计效能
- 7. 选择合适的分析方法与报告结果
- 总结Conclusion