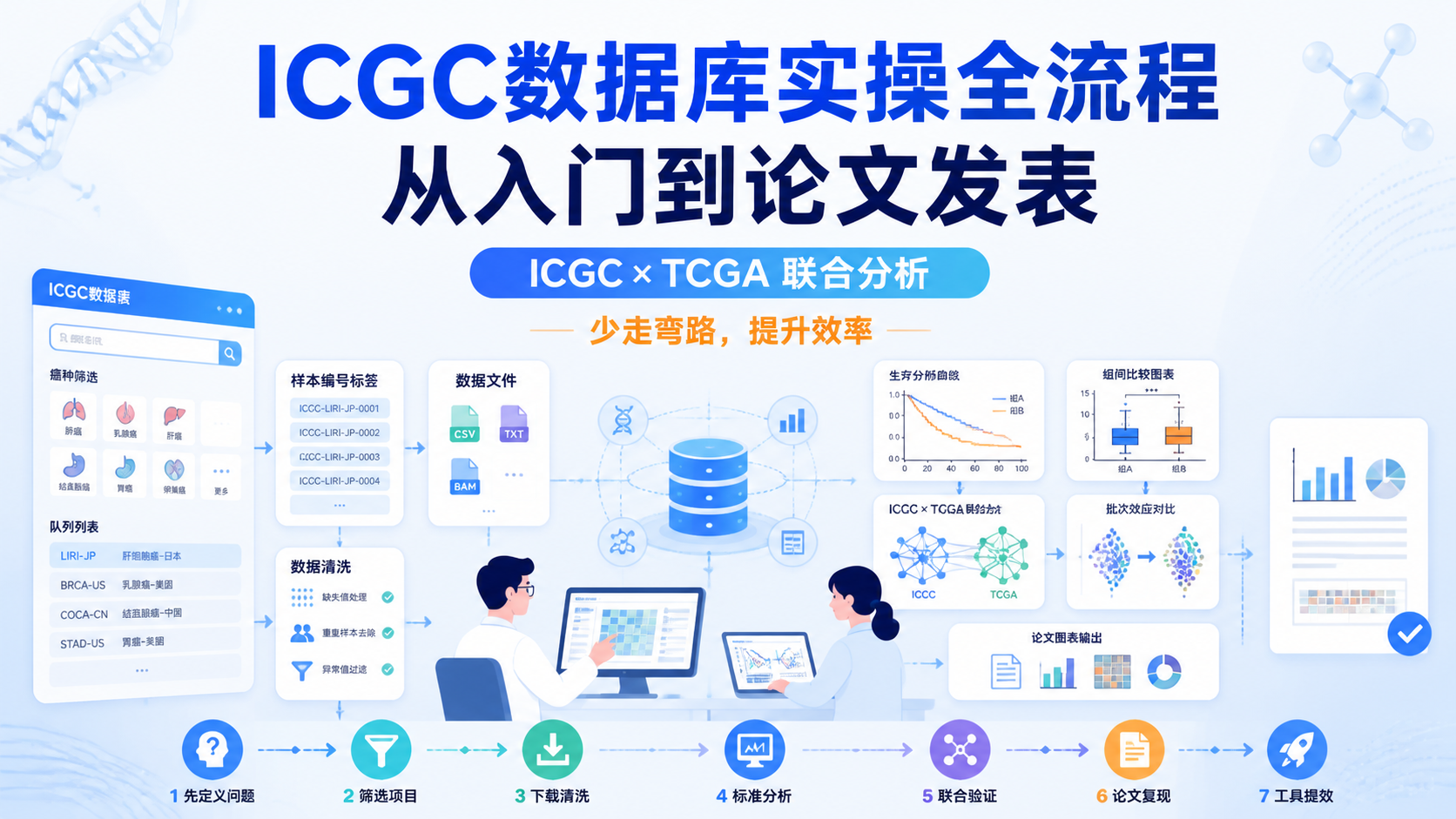
引言Introduction
ICGC数据整合常见难点,不是“拿不到数据”,而是样本、文件格式、注释版本和临床信息难以统一。对医学生、医生和科研人员来说,真正影响分析结果的,往往是整合前的标准化处理。如果起点不一致,后续差异分析、分型和生存分析都会被放大偏差。

1. 先明确ICGC数据整合的目标
1.1 先想清楚要回答什么问题
在开始 ICGC数据整合 前,先定义研究终点。是做基因差异分析,还是做预后建模,或是做多组学关联分析。目标不同,所需数据类型也不同。
常见数据包括:
- 基因表达数据
- 突变数据
- 拷贝数变异数据
- 临床表型数据
只有先定研究问题,后续的数据清洗、筛选和合并才有统一标准。
1.2 统一分析层级
ICGC数据来自不同项目,组织来源、测序平台和临床字段并不完全一致。整合时要先决定分析层级,是按样本、患者,还是按肿瘤类型。
如果同一患者有多个样本,需要先明确保留规则。否则,重复样本会直接影响统计独立性。对临床研究来说,这一步尤其重要。
2. 搭建ICGC数据整合的数据清单
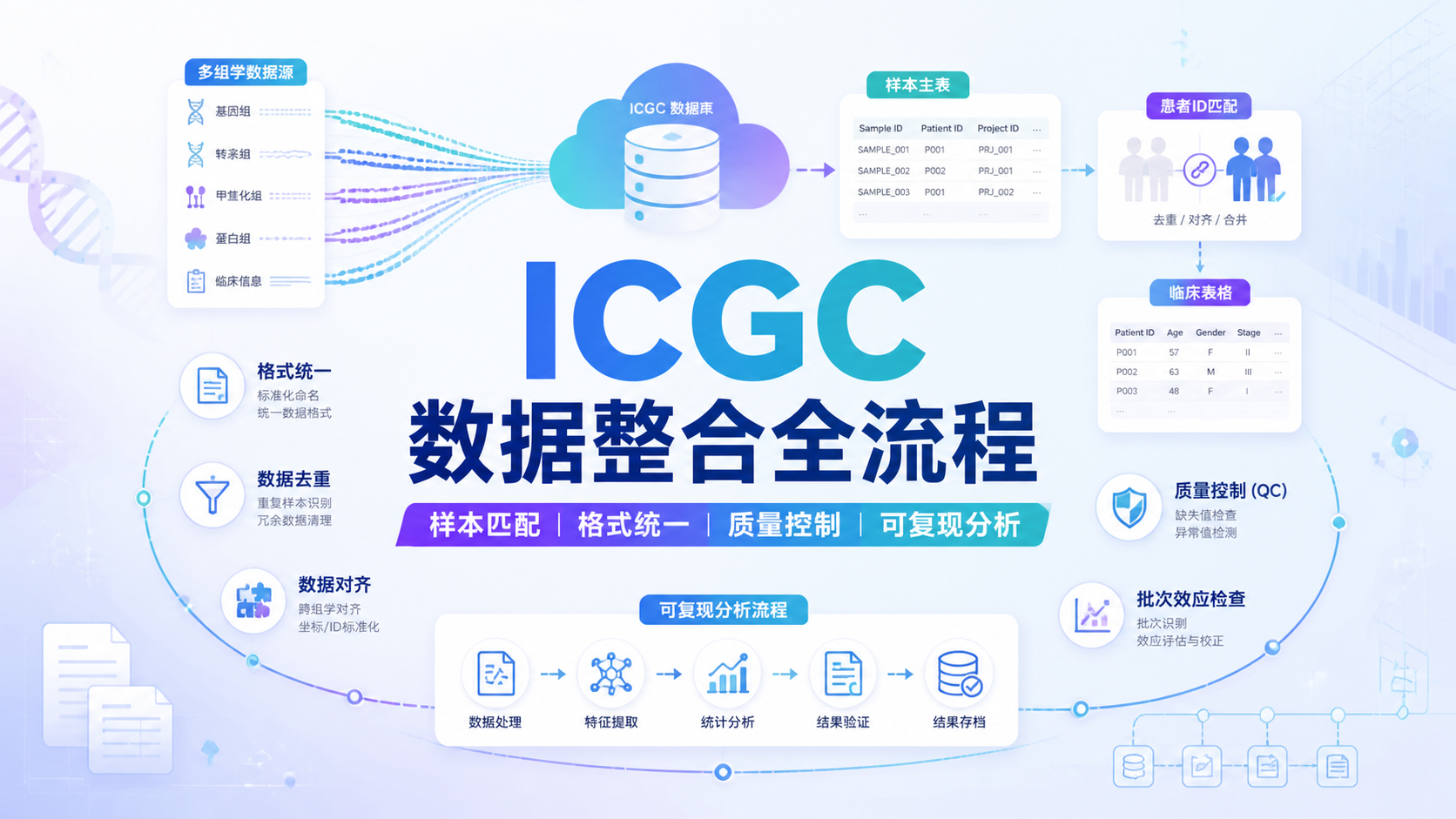
2.1 建立样本主表
ICGC数据整合的核心,是先建立一张样本主表。主表至少要包含:
- ICGC项目编号
- 样本ID
- 患者ID
- 肿瘤类型
- 数据类型
- 平台信息
样本主表相当于“索引层”,后面所有矩阵和临床表都要围绕它对齐。
2.2 记录数据来源和版本
不同批次下载的数据可能存在字段差异。建议同步记录下载日期、版本号和注释数据库版本。这样在论文复现或数据审查时,能快速追溯来源。
对科研团队而言,这一步能显著降低协作成本,也能减少“同一份数据,不同人跑出不同结果”的问题。
3. 完成数据预处理和格式统一
3.1 统一文件格式
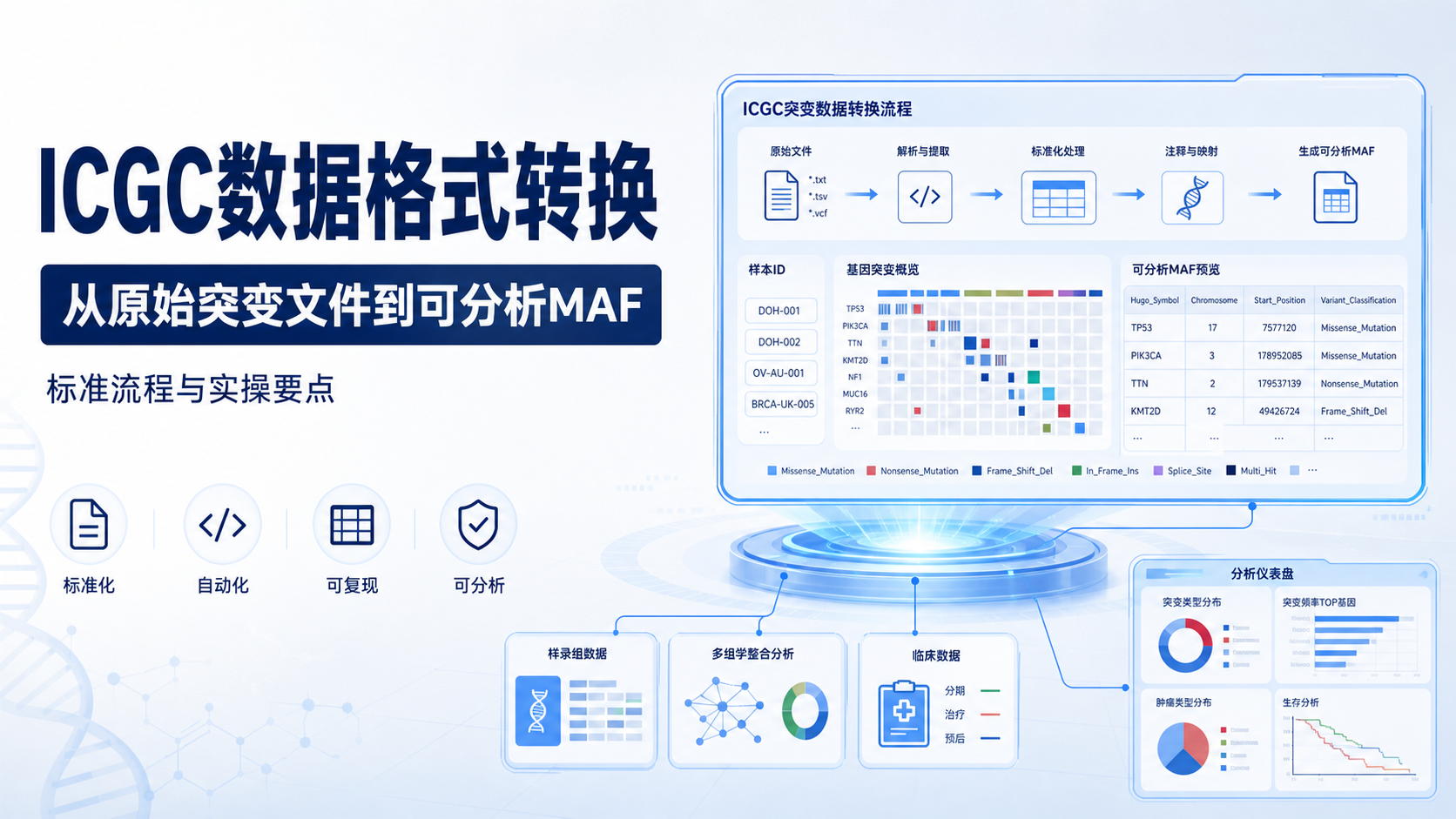
ICGC数据整合中,第一轮预处理通常包括格式统一。常见情况是表达矩阵、突变注释表和临床表来自不同格式,需要转成可计算结构。
建议优先统一为:
- 表格型数据
- 行列命名标准化
- 缺失值标识统一
文件格式不统一,后续无法准确合并,也容易在程序读取时产生错误。
3.2 标准化命名规则
样本名、基因名和临床变量名要统一。比如同一字段在不同文件中可能写成“age”“Age”“age_at_diagnosis”。如果不先规范,合并后会出现重复列或空列。
这一环节建议建立命名字典。对团队协作和长周期项目尤其有用。
4. 做好样本匹配与去重
4.1 按患者ID和样本ID双重核对
ICGC数据整合最容易出错的地方,是样本错配。建议同时核对患者ID和样本ID,确认每一条临床信息都对应正确样本。
尤其是多区域测序或重复测序数据,更要检查是否存在同一患者多个样本。错配一次,分析结果可能整体失真。
4.2 处理重复和缺失
重复样本通常需要按预先设定规则保留一份。常见规则包括保留质量更高者,或保留与研究终点最匹配的样本。
对缺失值要分类处理:
- 关键变量缺失,通常剔除
- 非关键变量缺失,可考虑补充或单独标记
- 大量缺失数据,建议重新评估纳入标准
5. 进行组学数据与临床数据对齐
5.1 把表达、突变和临床表合并到同一框架
完成 ICGC数据整合 后,最关键的是把不同层级信息放进同一分析框架。常见做法是以样本主表为中心,把表达矩阵、突变结果和临床结局逐步合并。
合并时建议逐步验证:
- 合并前样本数
- 合并后样本数
- 缺失样本比例
- 关键字段完整率
每合并一次,都要做一次一致性检查。
5.2 注意临床字段的可比性
ICGC不同项目的临床字段不完全一致。比如生存时间、分期、治疗信息和随访终点,可能存在编码差异。合并前应先确认变量定义是否一致。
如果变量定义不同,不建议直接并表。应先做字段映射,再统一为分析所需格式。这样才能保证后续统计结果可解释。
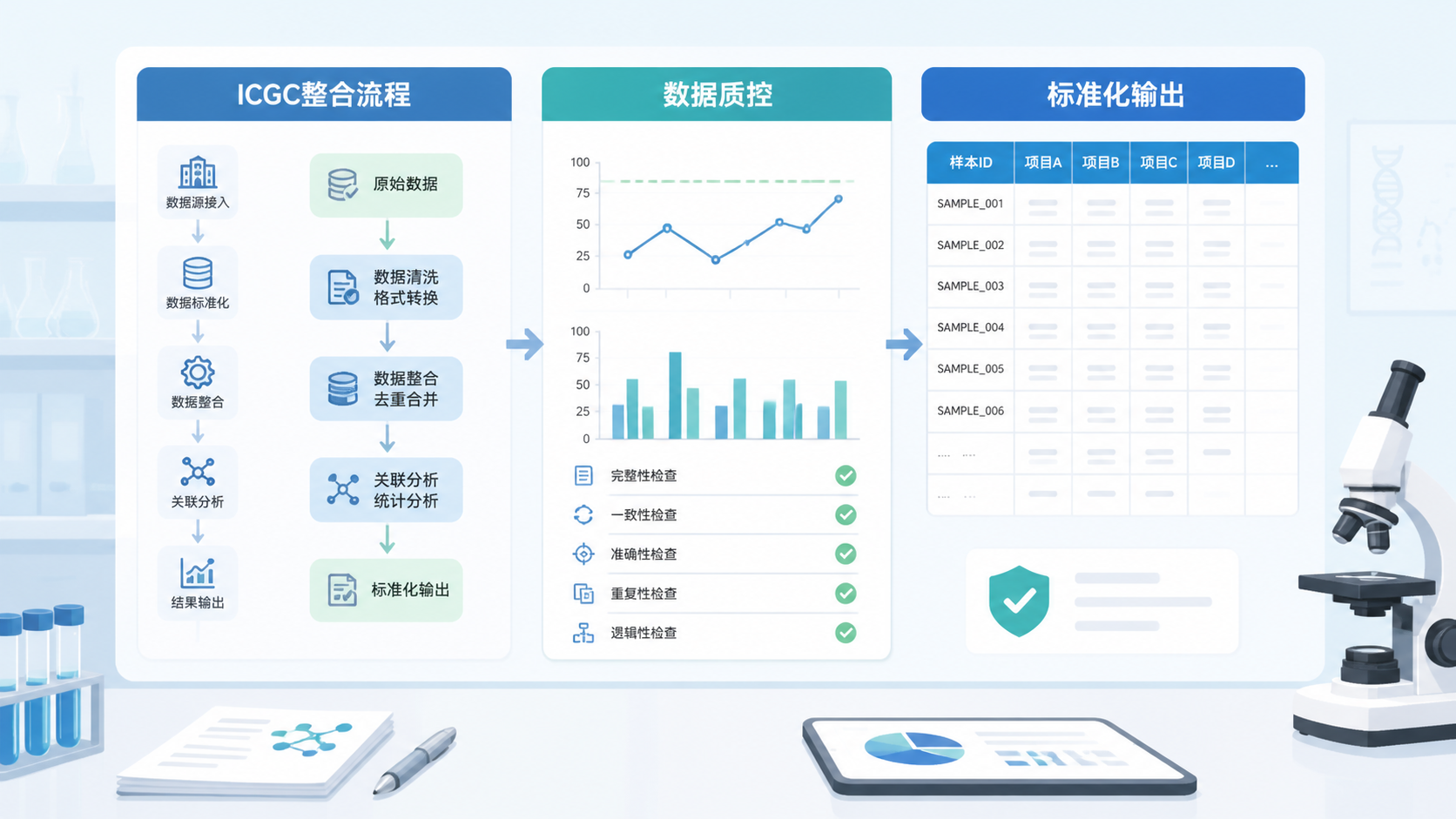
6. 做质量控制和批次效应检查
6.1 先看数据分布,再看异常值
ICGC数据整合完成后,必须做质量控制。可以先检查表达值分布、样本总量、异常值和离群点。对于多组学数据,还要确认各组学之间是否存在明显偏移。
常见QC步骤包括:
- 缺失率检查
- 重复样本检查
- 异常值检查
- 分布一致性检查
6.2 识别批次效应
不同测序平台、不同中心、不同处理流程,都会引入批次效应。对表达谱分析来说,批次效应可能比生物差异更强。
如果发现不同批次聚类明显分开,就要考虑进行校正。否则,后续差异基因、通路富集和分型分析都可能偏离真实生物学信号。
7. 建立可复现的分析流程
7.1 固化代码和参数
真正高质量的 ICGC数据整合,不只是“整合完成”,还要能重复。建议把下载、清洗、合并、QC和建模步骤写成固定脚本,并记录参数。
最好保留以下内容:
- 原始数据路径
- 过滤阈值
- 合并规则
- 版本信息
- 输出结果说明
可复现,才是科研数据整合的底线。
7.2 输出标准化结果表
最终应输出适合下游分析的标准表格,例如:
- 样本信息总表
- 表达矩阵
- 突变注释表
- 临床分析表
这些结果最好命名统一,字段固定,便于后续团队成员直接调用。这样能减少重复劳动,也能提升论文和课题推进效率。
结论Conclusion
ICGC数据整合的本质,不是简单拼接多个文件,而是围绕研究问题完成样本统一、格式统一、字段统一和质量控制。只要把7个步骤做好,后续差异分析、预后分析和多组学研究的可靠性都会明显提升。
如果你希望把ICGC数据整合流程做得更稳、更快、更标准,可以借助解螺旋的科研数据服务与分析支持,把复杂数据处理交给更专业的流程化工具,减少返工,提升产出效率。
- 引言Introduction
- 1. 先明确ICGC数据整合的目标
- 2. 搭建ICGC数据整合的数据清单
- 3. 完成数据预处理和格式统一
- 4. 做好样本匹配与去重
- 5. 进行组学数据与临床数据对齐
- 6. 做质量控制和批次效应检查
- 7. 建立可复现的分析流程
- 结论Conclusion