引言Introduction
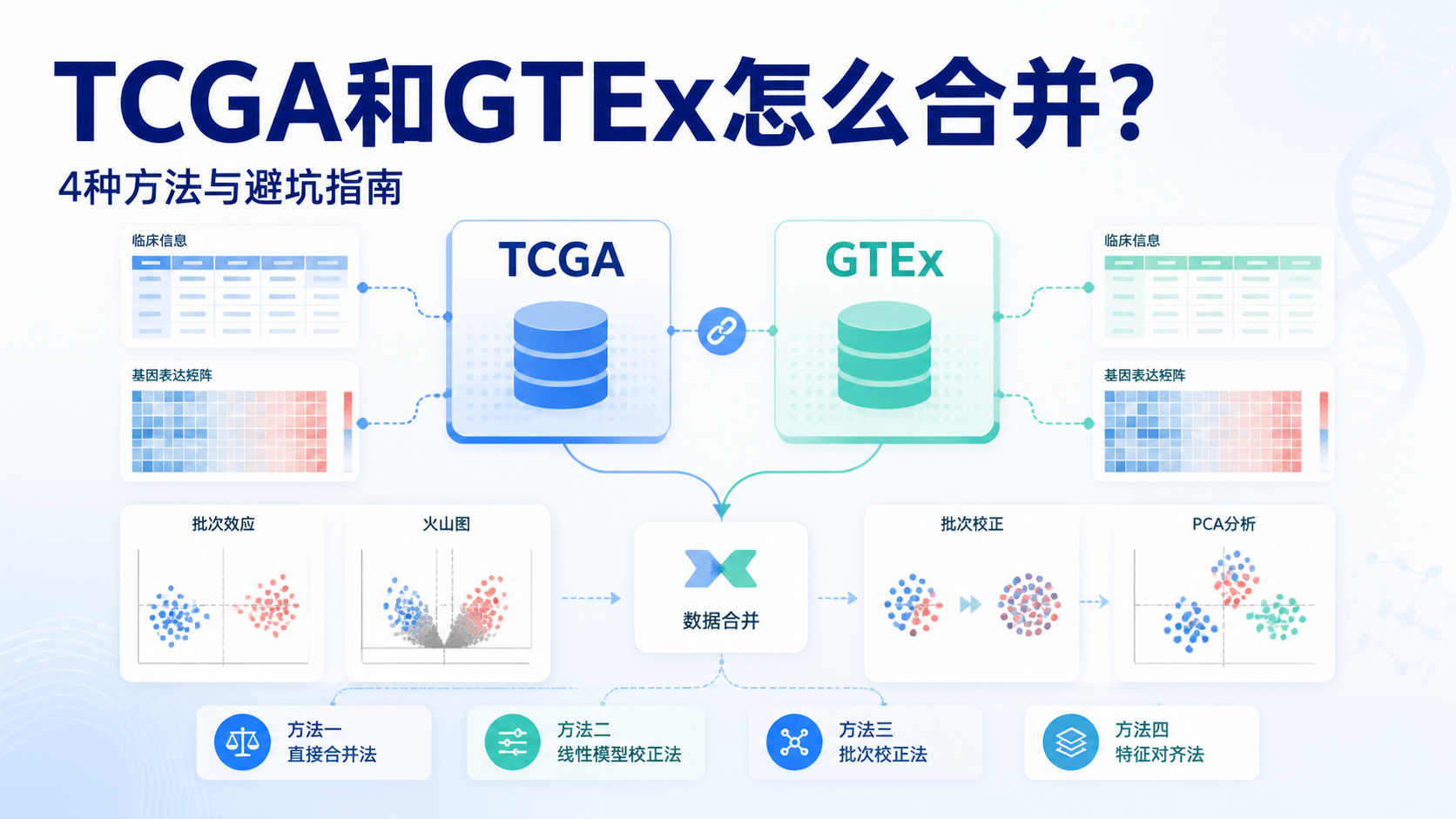
TCGA数据合并是很多生信分析的第一道门槛。样本来源不同,表达量格式不同,批次效应也不同。若合并不规范,后续差异分析和PCA很容易失真。下面结合GTEx、recount2和TCGA常见流程,梳理4种合并思路,帮助你少走弯路。
1. 为什么TCGA数据合并不能直接“拼表”
1.1 样本来源不同,不能默认可比
TCGA的肿瘤样本、癌旁样本、正常样本,生物学来源本就不同。GTEx的正常组织来自健康个体。这意味着即使组织名称相同,样本背景也不完全一致。
在肝脏数据中,癌旁组织和正常肝组织在PC图上会更接近,但它们并不是严格意义上的同类样本。若直接把它们当成完全可比对象,差异分析会引入偏差。
1.2 批次效应会先于生物学差异出现
在实际数据里,PCA常常先分出“数据来源”,再分出“疾病状态”。这说明批次效应可能比真实信号更强。
所以,TCGA数据合并的核心,不只是把矩阵拼在一起,而是先保证数据结构一致,再尽量减少技术偏差。
1.3 先看PCA,再决定处理策略
PCA图只能作为参考,不能作为最终裁决。知识库中提到,K=1时数据更接近,K=2时更集中,但样本仍能分成几个区块。
这说明:PCA可提示是否需要校正,但不能替代正式的合并与差异分析流程。
2. 方法一:UCSC来源的TCGA与GTEx合并
2.1 先统一基因ID,再做列方向合并
UCSC下载的数据通常已经经过整理。常见做法是先提取基因ID和基因名,再把表达矩阵按基因对齐。
知识库中使用 next join 思路,将基因ID与基因信息放在前面,再按ID合并。前提是两个矩阵的行名和顺序一致。
2.2 数值处理要注意“逆转换”
这类数据常经过处理,不一定保留原始计数。知识库中提到,可对数值列批量处理,把处理后的值逆回整数形式。
例如对数值列使用 across 批量操作,只处理数值列,保留字符串列不变。
这一点很关键,因为后续若要做某些差异流程,输入格式必须一致。
2.3 优点和局限
这种方式的优点是操作较直观,适合快速整合。
局限也很明确:
- 数据类型可能不是原始计数。
- 不同组织来源的样本仍可能存在批次差异。
- 若临床信息与表达矩阵同步不严谨,后面还要补很多清洗工作。
适合有一定R基础、希望快速完成TCGA数据合并的人。
3. 方法二:recount2项目下载后再合并
3.1 recount2的优势是结构更标准
recount2提供按组织类型分类的数据,GTEx和TCGA都能按同一框架下载。知识库中以肝脏样本为例,分别下载GTEx正常肝组织和TCGA肝癌数据,再进行合并。
这种方式的好处是:数据对象统一,便于后续差异分析。
3.2 推荐先检查基因行是否完全一致
在合并前,先确认两个对象的行信息一致。知识库中明确指出,GTEx与TCGA的行信息一致后,才可以直接合并。
这一步不能省。因为如果基因集合不一致,合并后会出现大量缺失值,影响下游分析。
3.3 recount2合并后的样本量更大
知识库中提到,GTEx正常肝脏样本有136个,TCGA肝癌样本有424个。合并后样本规模更充足,适合做差异表达分析。
但也要注意:样本数量增加,不等于偏差自动消失。 PCA中仍可能看到明显分层,因此后续校正仍然必要。
4. 方法三:TCGA与GTEx合并后做批次校正
4.1 k值选择影响合并结果
知识库中比较了k=0、1、2、3等设置。结论很清晰:k=1更稳妥。
原因是k=1进行了管家基因矫正,而不是完全不校正。对比结果显示,k=0和k=1的差异基因有约2/3一致,约1/3不一致。
这说明校正会影响最终结果,不能忽视。
4.2 差异基因重合度比单次结果更重要
在多个k值之间,如果某个基因反复出现在共同差异基因中,它更值得关注。
相反,如果某基因只在k=0中出现,而在k=1中消失,就要警惕它可能是假阳性。
4.3 这类方法适合什么场景
如果你的目标是把TCGA和GTEx联合起来找差异基因,这种方法很实用。
适用前提是:
- 已完成样本整理。
- 已统一表达量格式。
- 已接受批次校正会改变部分结果。
对于科研论文中的正式分析,k=1通常比不校正更可信。
5. 方法四:只用TCGA内部数据做差异分析
5.1 内部比较比跨库合并更稳
如果研究问题允许,只在TCGA内部比较肿瘤与癌旁,往往比跨TCGA和GTEx更稳。
因为样本来源、测序平台、处理流程更一致,批次效应更小。
5.2 TCGA临床信息也要同步整理
知识库中提到,TCGA临床信息最好优先使用官方整理好的tab格式,而不是反复解析XML。
原因很直接:tab格式已经按病人ID、分期、TNM、性别、生存等信息整理好,减少了代码复杂度,也更少出错。
如果临床分组有误,差异分析就会从源头偏掉。
5.3 何时优先选这个策略
当研究重点是:
- 肿瘤内部亚型比较
- 生存分析
- 分期相关分析
- 只需要TCGA样本
那就不一定非要和GTEx合并。
能不合并时,尽量减少跨项目整合。 这是降低风险的实用原则。
6. 四种方法怎么选,哪种最稳
6.1 如果追求稳妥,优先级是这样的
综合知识库中的经验,建议这样排序:
- TCGA内部分析最稳。
- recount2统一框架下合并,次稳。
- UCSC整理数据合并,可快速实施。
- 不校正直接合并,风险最高。
6.2 如果必须做TCGA与GTEx联合分析
建议按以下顺序执行:
- 先确认基因ID一致。
- 再统一表达量格式。
- 然后做PCA初筛。
- 最后用合适的校正策略,优先考虑k=1。
- 差异基因结果要看重合度,不只看单次输出。
6.3 最常见的三个坑
第一,误把癌旁当正常。
癌旁不是健康个体组织,生物学背景不同。
第二,忽略批次效应。
PCA能分开,往往说明要先处理偏差。
第三,只看一个k值。
不同k值结果有差异,最好做交叉验证式判断。
总结Conclusion
TCGA数据合并的关键,不是“把矩阵拼起来”,而是先统一数据结构,再尽量控制批次效应。若追求稳妥,优先做TCGA内部分析 。若必须联合GTEx,recount2和k=1校正思路更值得优先考虑 。
在实际科研中,规范的数据整理往往决定下游结果是否可信。若你希望用更成熟的流程减少合并误差、提升分析效率,可以关注解螺旋 的生信方法与实战内容,帮助你更快完成TCGA数据合并与差异分析。
- 引言Introduction
- 1. 为什么TCGA数据合并不能直接“拼表”
- 2. 方法一:UCSC来源的TCGA与GTEx合并
- 3. 方法二:recount2项目下载后再合并
- 4. 方法三:TCGA与GTEx合并后做批次校正
- 5. 方法四:只用TCGA内部数据做差异分析
- 6. 四种方法怎么选,哪种最稳
- 总结Conclusion