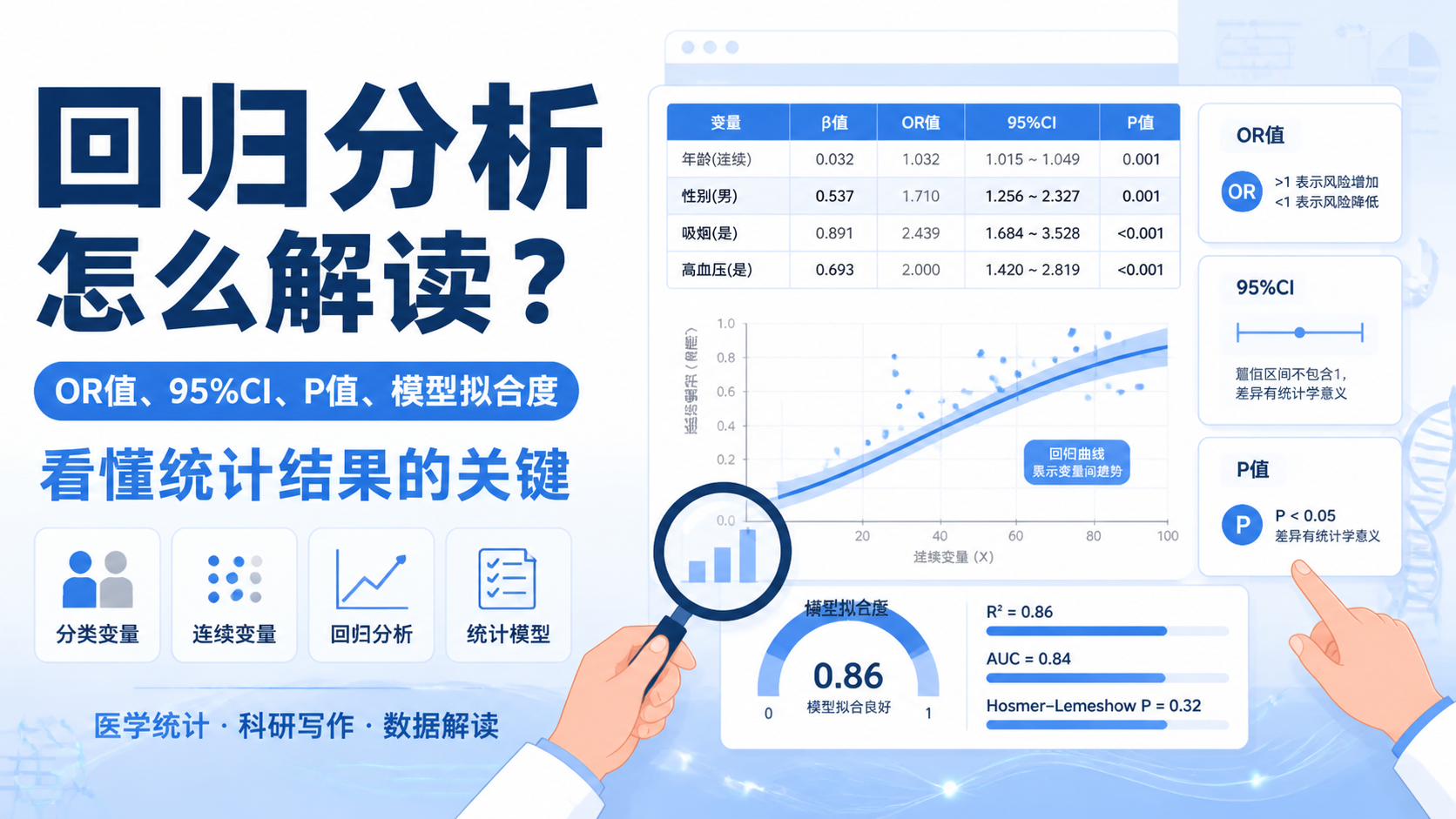
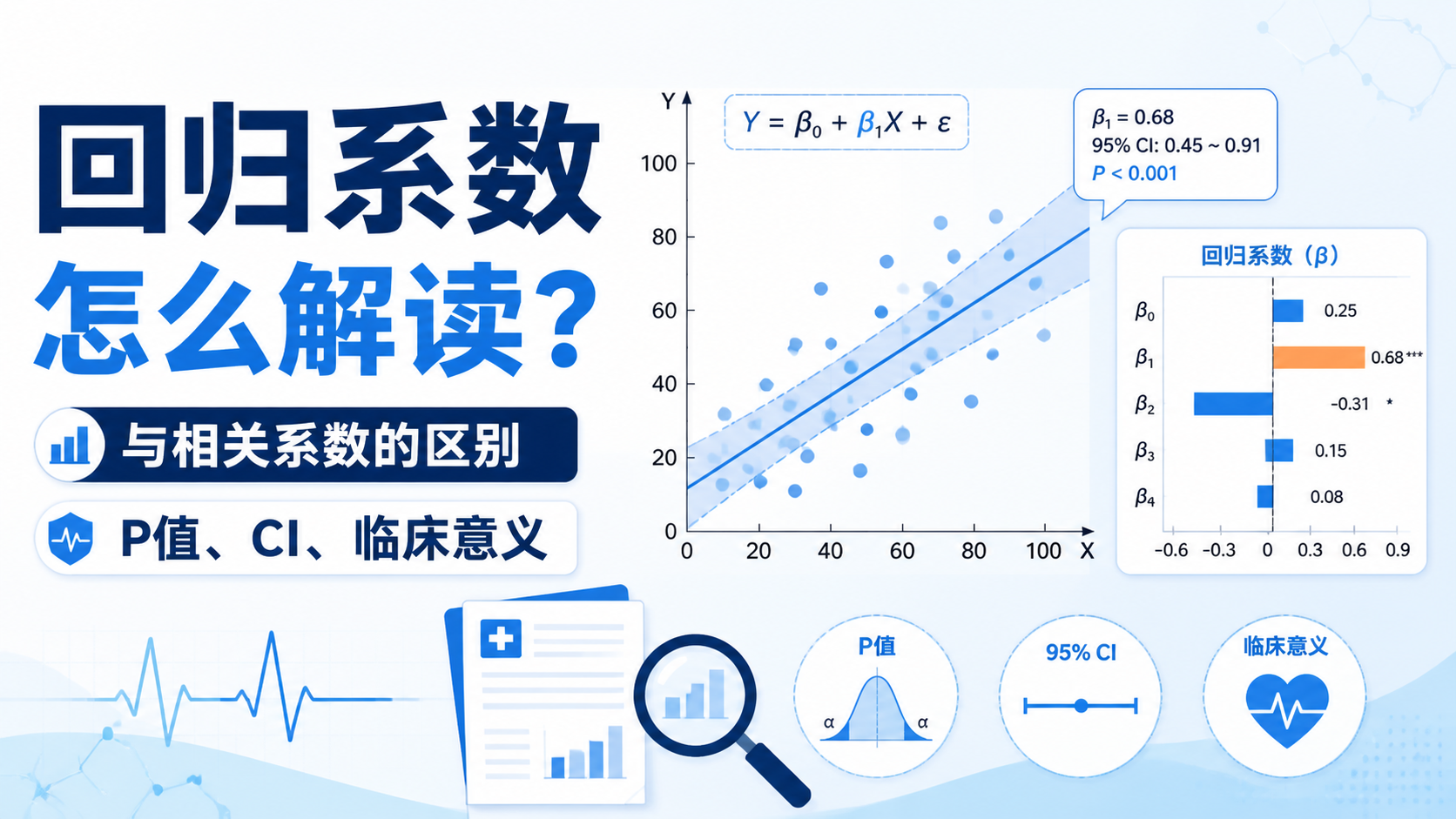
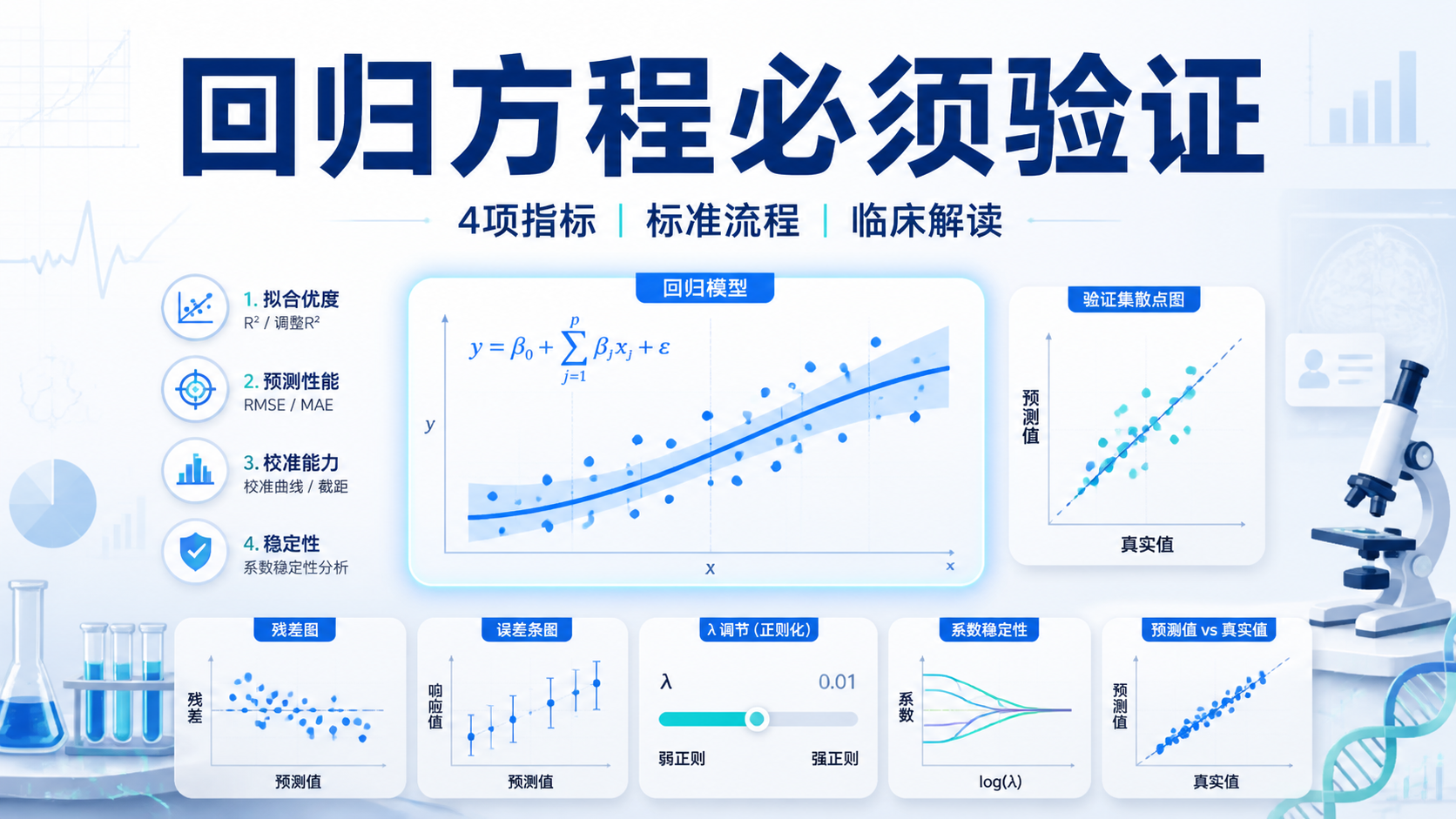
引言Introduction
回归分析常被用于解释变量关系、筛选危险因素和构建预测模型。但很多初学者在建模时,先急着跑结果,却忽略了回归分析适用条件 。一旦前提不满足,系数、P值和OR都可能失真,文章也容易被审稿人质疑。
1. 回归分析为什么必须先看适用条件
1.1 回归模型不是“万能公式”
回归分析的本质,是根据研究目的,用自变量去解释或预测因变量。它的结果是否可靠,取决于数据是否满足模型要求。
如果前提条件不成立,模型仍然可以跑出来,但解释可能是错的。
临床研究里最常见的问题有三类。
- 因变量类型选错。
- 自变量编码不合理。
- 数据分布和关系形式不满足模型假设。
这些问题会直接影响结果。比如连续变量强行按分类变量处理,或者把无序分类变量当成连续变量,都可能导致偏倚。
1.2 回归分析适用条件的核心是“变量匹配”
知识库中强调了一句很关键的话,变量选方法,设计判类型,目的定乾坤 。
这句话的意思很明确。先看研究目的,再看变量类型,最后决定方法。
例如。
- 结局变量是连续型,常考虑线性回归。
- 结局变量是二分类,常考虑Logistic回归。
- 结局变量带时间因素,常考虑Cox回归。
所以,讨论回归分析适用条件 ,本质上就是讨论变量是否和模型匹配,数据是否支持这个模型。
2. 第一个核心前提:因变量类型必须与回归模型一致
2.1 不同结局变量,对应不同回归方法
这是最基础,也最容易被忽略的一条。
回归模型不是先选软件,再看能不能用。是先看因变量,再选模型。
常见对应关系如下。
- 连续变量,适合线性回归。
- 二分类变量,适合Logistic回归。
- 多分类或等级变量,需要选择合适的扩展模型。
- 带随访时间的结局,常用Cox回归。
如果因变量类型错配,模型输出就失去解释基础。比如把“是否发病”这种二分类结局当作连续变量处理,线性回归的解释就不成立。
2.2 结局变量的编码要先标准化
知识库提到,复杂文本数据和非结构化数据,在正式分析前要先转成结构化数据。
例如。不良事件描述要整理成“发生=1,未发生=0”。日期可以转成天数,和研究无关的日期则可删除。
这一步非常重要。因为回归分析依赖软件识别变量类型。
变量编码不规范,模型再复杂也没有意义。
对于医学生和科研人员来说,建模前至少要确认三件事。
- 结局变量是否已经明确。
- 结局变量是否已按模型要求编码。
- 变量是否被错误地当成连续变量处理。
3. 第二个核心前提:自变量关系不能严重失真
3.1 自变量要避免错误编码
对于分类变量,尤其是无序多分类变量,不能直接按1、2、3这样当连续变量处理。
知识库中明确提到,种族这类无序分类变量应设置哑变量,否则软件会错误地认为它有大小顺序。
这是回归分析适用条件中的关键点。
因为一旦编码错误,回归系数代表的就不是你以为的临床含义。
举例来说。
- 性别可以设为二分类变量。
- 吸烟状态可设为二分类变量。
- 血型、职业、种族等无序多分类变量,要做哑变量处理。
- 疗效、病情严重程度等有序分类变量,要按资料属性谨慎处理。
3.2 连续变量和分类变量的处理方式要一致
线性回归中,自变量可以是连续变量,也可以是分类变量。
但不同变量的解释方式不同。
连续变量的回归系数表示“每增加1个单位,结局改变多少”。
分类变量的回归系数表示“与参照组相比,风险或均值差异多少”。
这意味着,建模前要统一处理逻辑。
同一个变量,不能在不同模型里随意换编码,却不解释这种变化。
临床研究里,最常见的错误是把本应分组的变量,直接按原始数值进入模型。比如某些评分是否适合线性使用,需要看研究设计和统计假设,而不是图省事直接放入。
4. 第三个核心前提:数据本身要满足模型的基本统计假设
4.1 线性回归关注正态性和方差齐性
知识库明确指出,t检验和方差分析等经典模型,要求数据满足正态分布和方差齐性。
回归分析也一样,尤其是线性回归,需要关注残差是否近似正态分布,以及不同自变量水平下残差方差是否大致相等。
这里要注意,很多时候检验的重点不是原始变量,而是残差。
如果不满足这些条件,可以考虑:
- 数据转换,如对数转换。
- 改用非参数方法。
- 重新选择更合适的模型。
这一步不能省。因为模型假设一旦被破坏,P值和置信区间的可信度就会下降。
4.2 样本量要足够,变量数量要受控
知识库中对多因素回归强调了样本量要求。
一般常用经验是,一个自变量大约需要20个样本支持 。在Cox回归中,也常提到EPV=20,即每个变量需要20个结局事件。
这不是绝对公式,但它提醒我们。
样本量不足时,回归模型容易不稳定。
样本太少会带来这些问题。
- 系数波动大。
- 置信区间过宽。
- 变量筛选结果不稳定。
- 过拟合风险升高。
所以,回归分析适用条件不仅看变量类型,也看样本是否支撑得起模型复杂度。
4.3 共线性和变量筛选也要提前考虑
知识库提到,多因素回归常见Enter法、向前法、向后法等筛选方式。
但不管哪种方法,都要建立在数据质量和样本量基础上。
如果自变量之间高度相关,就可能出现共线性。
这会导致:
- 标准误增大。
- 单个变量P值失真。
- 模型解释变弱。
因此,回归建模前应先做变量筛查。
保留真正有临床意义、统计上合理的变量,再进入模型。
这比盲目把所有变量一股脑塞进去更可靠。
5. 临床研究中如何快速判断自己能不能做回归
5.1 先问三个问题
想判断回归分析适用条件 是否满足,可以先问自己三个问题。
- 我的因变量是什么类型。
- 我的自变量是否编码正确。
- 我的数据和样本量是否支持这个模型。
如果这三问中有一项答不清楚,就不要急着建模。
5.2 一个实用检查清单
建模前建议按下面顺序检查。
- 结局变量是否明确。
- 连续、二分类、多分类、时间变量是否分清。
- 无序分类变量是否已设哑变量。
- 是否存在明显缺失、失访、异常值。
- 是否满足基本分布要求。
- 样本量是否足够。
- 变量之间是否存在明显共线性。
这套流程很适合临床科研入门阶段。
它能减少很多低级错误,也能让结果更容易通过同行评审。
总结Conclusion
回归分析适用条件,核心就是三点。
第一,因变量类型必须和模型一致。第二,自变量编码必须合理。第三,数据分布、样本量和变量关系要支持模型。
对医学生、医生和科研人员来说,建模不是“把数据丢进软件”。真正重要的是先判断条件,再选择方法。只有这样,回归结果才有解释价值,才能更好地支持论文写作和临床证据构建。
如果你希望更高效地完成变量整理、统计建模和论文写作,可以进一步借助解螺旋 的科研支持工具与方法体系,把复杂的统计前处理做得更规范、更省时。

- 引言Introduction
- 1. 回归分析为什么必须先看适用条件
- 2. 第一个核心前提:因变量类型必须与回归模型一致
- 3. 第二个核心前提:自变量关系不能严重失真
- 4. 第三个核心前提:数据本身要满足模型的基本统计假设
- 5. 临床研究中如何快速判断自己能不能做回归
- 总结Conclusion