引言Introduction
临床研究里,t 检验计算公式 是高频考点,也是论文统计分析的基础。很多医学生和科研人员会卡在“什么时候用、公式怎么写、结果怎么解释”。本文用3类场景拆开讲清楚,帮助你快速判断方法、理解公式、避免常见错误。

1. 先弄清楚 t 检验适合什么场景
1.1 t 检验解决的核心问题
t 检验用于比较均值差异 。前提是数据属于连续型资料,且总体分布近似正态。
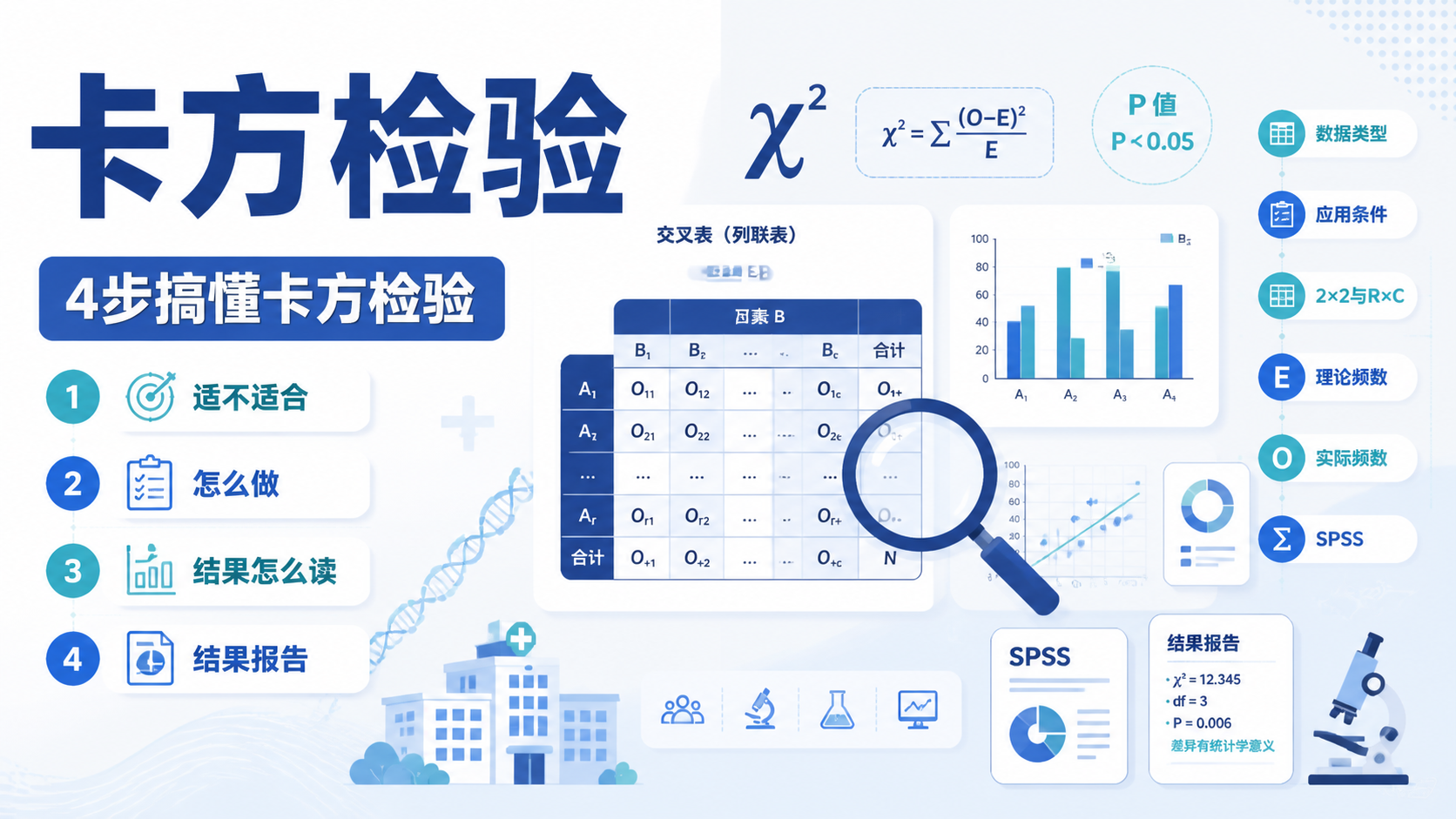
它不是用来比较率、构成比,也不是用来分析分类变量。若是分类资料,通常考虑卡方检验或 Fisher 确切概率法。
临床研究中,最常见的就是比较两组患者的某项指标是否有差异,比如年龄、血压、实验室指标、评分等。如果你的结局变量是“平均值”而不是“比例”,t 检验才是优先考虑的方法。
1.2 3类常见场景
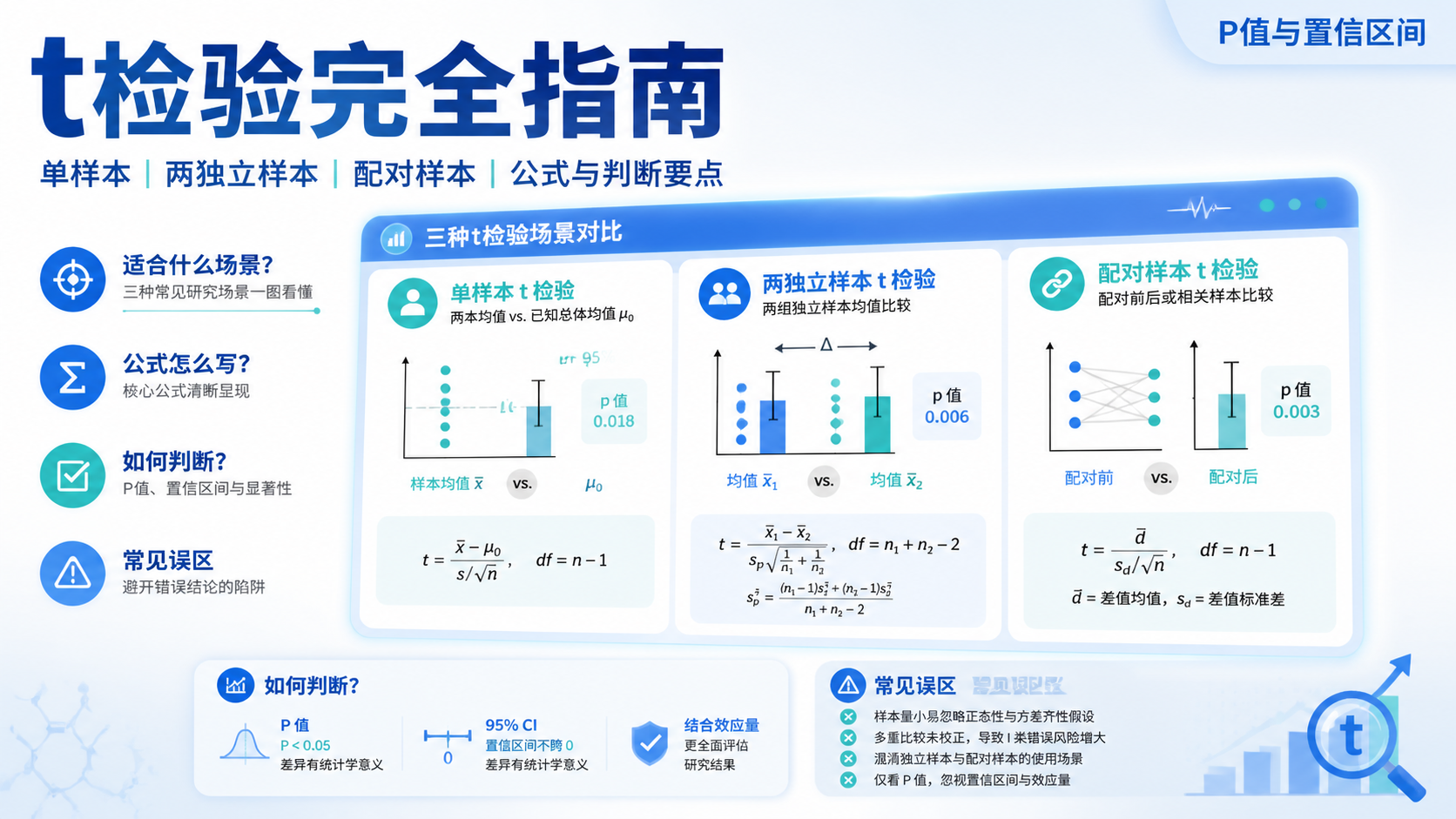
t 检验常见有3种:
- 单样本 t 检验 ,看样本均值是否等于某个已知值。
- 两独立样本 t 检验 ,看两组独立样本均值是否不同。
- 配对 t 检验 ,看同一对象干预前后是否有变化。
这3类场景对应的 t 检验计算公式不同。公式看似复杂,本质都是“均值差异”除以“差异的标准误”。
2. t 检验计算公式怎么写
2.1 单样本 t 检验公式
单样本 t 检验用于比较样本均值与总体均值是否一致。公式为:
t = (x̄ - μ) / (s / √n)
其中,x̄ 是样本均值,μ 是已知总体均值,s 是样本标准差,n 是样本量。
这个公式的逻辑很直接。分子是“观察到的差值”,分母是“这个差值在样本波动下是否足够大”。 如果差值远大于随机误差,t 值就大,提示差异更可能有统计学意义。
2.2 两独立样本 t 检验公式
两独立样本 t 检验用于比较两组独立样本均值。常见写法是:
t = (x̄1 - x̄2) / SE(x̄1 - x̄2)
若两组方差齐性,可写成合并方差形式:
t = (x̄1 - x̄2) / [Sp × √(1/n1 + 1/n2)]
其中,Sp 为合并标准差。
若不满足方差齐性,通常采用 Welch t 检验,分母使用两组各自方差计算出的标准误。实际论文中,是否使用“等方差假定”要看方差齐性检验结果。
2.3 配对 t 检验公式
配对 t 检验用于同一对象前后比较,或一一配对设计。先计算每一对差值 d,再检验差值均值是否为 0。
公式为:
t = d̄ / (sd / √n)
其中,d̄ 是差值均值,sd 是差值标准差,n 是配对数。
配对 t 检验的关键不是两次测量的均值,而是“配对差值”的分布。 这是很多初学者最容易混淆的地方。
3. 3类场景分别怎么判断
3.1 单样本 t 检验的判断要点
单样本 t 检验常见于方法学验证、质量控制,或某指标是否达到参考标准。
你需要确认3点:
- 变量是连续型数据。
- 样本近似正态。
- 参考值已知。
若样本量较小,更要关注正态性。若偏态明显,单样本 t 检验不合适。
3.2 两独立样本 t 检验的判断要点
两独立样本 t 检验最常用于临床组间比较,比如治疗组和对照组。
判断时注意:
- 两组样本相互独立。
- 结局是连续型变量。
- 总体近似正态。
- 方差齐性可进一步决定用哪种 t 公式。
如果你的研究目的是比较两组均值差,而不是比较中位数或率,首先考虑两独立样本 t 检验。
3.3 配对 t 检验的判断要点
配对设计常见于同一患者治疗前后比较。
判断时注意:
- 同一对象前后测量。
- 配对资料一一对应。
- 关注差值是否近似正态。
配对 t 检验比两独立样本 t 检验更“省样本”,因为它消除了部分个体间差异。在重复测量或前后对照研究中,配对 t 检验通常比独立样本 t 检验更合适。
4. 实际分析时,别只记公式
4.1 先判断数据类型
很多人一上来就背公式,但真正决定方法的是数据类型。
简单记忆如下:
- 连续型资料,看 t 检验或秩和检验。
- 分类资料,看卡方检验或 Fisher。
- 配对数据,优先考虑配对设计方法。
t 检验计算公式只是工具,前提判断错了,公式再熟也没用。
4.2 再看分布和方差
t 检验默认数据接近正态。样本量很小时,这个前提更重要。
若数据明显偏态,或者存在严重离群值,建议谨慎使用 t 检验,必要时改用非参数方法。
两独立样本 t 检验还要考虑方差是否齐性。软件通常会自动报告相关检验结果,研究者要学会看输出,不要只盯着 P 值。
4.3 最后看 P 值和置信区间
t 检验的核心输出通常包括 t 值、自由度和 P 值。
但在论文写作中,均值差、95%置信区间和效应量信息同样重要。 只有 P 值,往往不足以完整表达临床意义。
如果差异很小,即使统计学显著,也不一定有临床价值。反之亦然。科研写作中,统计学意义和临床意义必须分开讨论。
5. 论文和考试中最常见的误区
5.1 把率当成均值
这是最常见错误之一。
比如“治愈率”“阳性率”“吸烟比例”都不是 t 检验对象。它们是分类变量,应使用卡方检验或 Fisher 确切概率法。
5.2 把独立样本误写成配对样本
如果两组不是同一对象前后比较,就不能用配对 t 检验。
反过来,同一批患者前后比较却用独立样本 t 检验,也是不对的。研究设计决定公式,而不是软件界面决定公式。
5.3 只看显著性,不看前提
即使 P<0.05,也不代表模型选择一定正确。
t 检验的前提包括数据类型、分布特征和样本结构。前提不成立时,结果的可信度会下降。
总结Conclusion
t 检验计算公式的核心,不是死记符号,而是先判断场景,再匹配公式。 单样本 t 检验看样本均值与已知值的差异,两独立样本 t 检验看两组均值差,配对 t 检验看差值均值是否为 0。对医学生、医生和科研人员来说,真正重要的是把“数据类型、研究设计、前提条件、统计结果”连起来理解。
如果你希望更高效地学习临床统计分析,减少选错方法、写错结果的风险,可以进一步使用解螺旋 的临床研究课程和方法学内容,系统梳理 t 检验、卡方检验和非参数检验的应用边界。
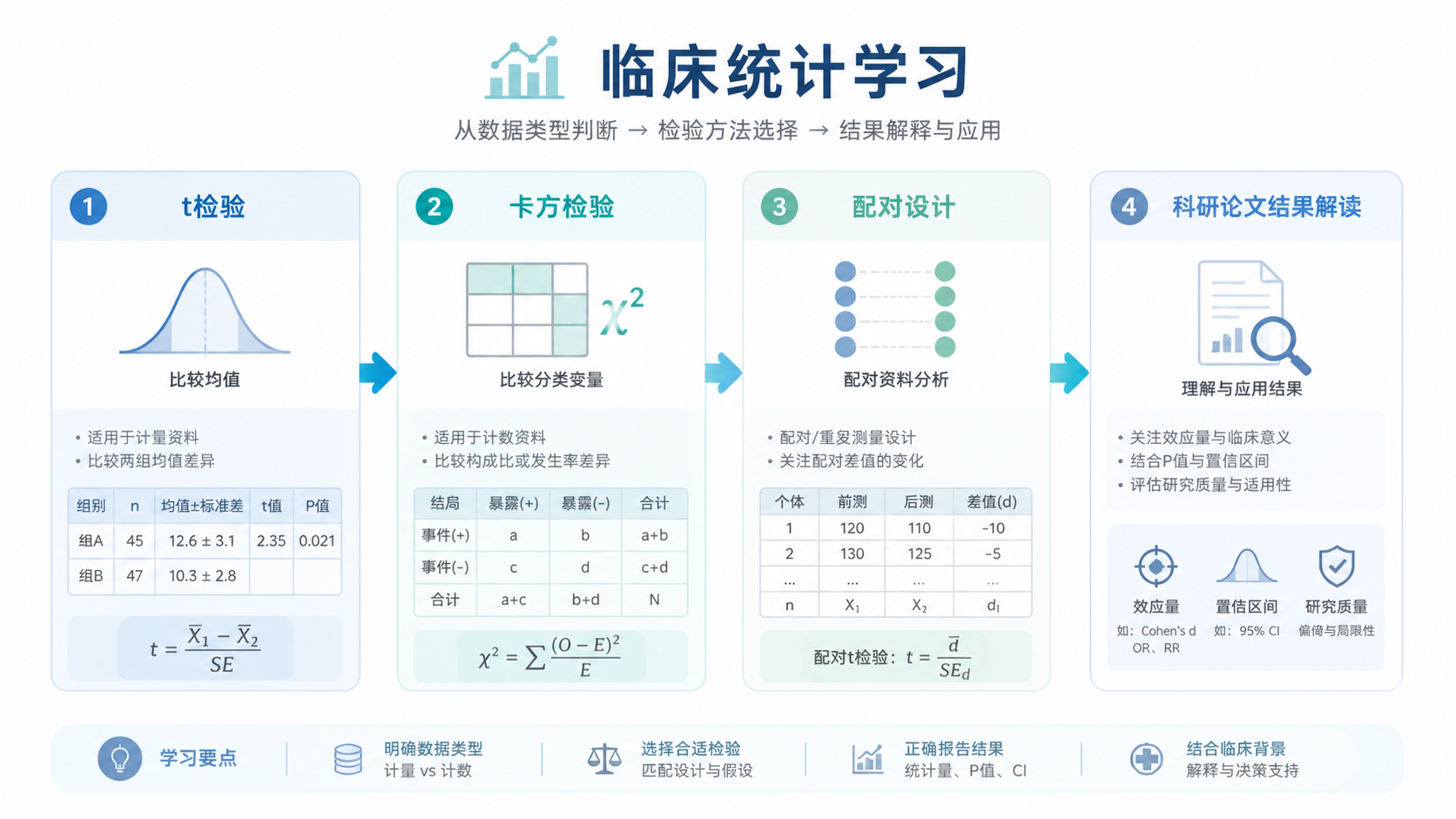
- 引言Introduction
- 1. 先弄清楚 t 检验适合什么场景
- 2. t 检验计算公式怎么写
- 3. 3类场景分别怎么判断
- 4. 实际分析时,别只记公式
- 5. 论文和考试中最常见的误区
- 总结Conclusion