引言Introduction
测序项目越来越大,测序数据存储 却常被低估。原始数据、质控数据、比对结果、分析文件一多,命名混乱、丢文件、版本冲突就会直接影响复现和发表。做好测序数据存储,不只是“放好文件”,而是保证数据可追溯、可复核、可交付。
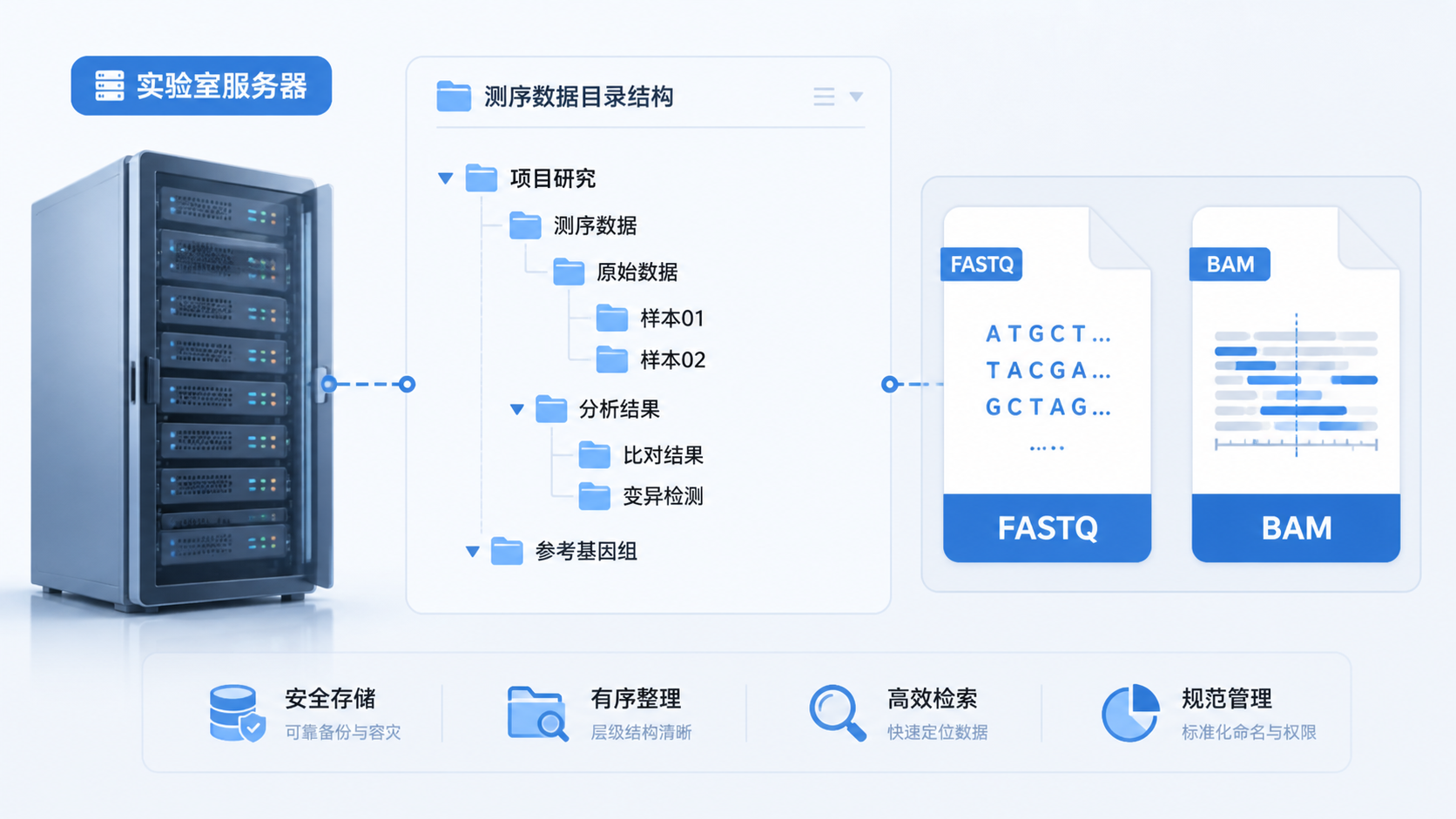
1. 先建立清晰的数据分层
1.1 按数据类型分层管理
测序数据通常不是单一文件,而是一条完整链路。建议至少分为四层:原始数据、质控数据、比对数据、结果数据。原始数据常见为 FASTQ,后续可转为 SAM 或 BAM,再进入差异分析、注释和作图阶段。
分层的核心价值,是避免“一个文件夹装全部结果”。 这样做能减少误删,也方便追踪每一步分析来源。对医学生、医生和科研人员来说,分层管理还能更快定位问题,是样本错配、质控失败,还是比对异常。
1.2 目录结构要固定
建议按项目、批次、样本、分析阶段四级组织。比如:
- 项目名
- 批次号
- 样本编号
- 数据类型
固定结构比临时整理更重要。 因为测序数据的体量会持续增长。若前期没有统一规则,后期补救成本极高。尤其在多组学研究中,基因组、转录组、甲基化、蛋白芯片等数据并行,目录结构越统一,管理越省力。
2. 统一命名规则,避免样本混淆
2.1 文件名必须包含关键信息
测序数据存储中,文件命名是最容易被忽视的一步。一个合格文件名,至少应包含项目、样本、测序类型、日期或批次。比如同一项目下的转录组和全基因组重测序,命名逻辑就不能相同。
命名的目标不是好看,而是让人一眼识别来源。 这对多人协作尤其重要。临床样本、动物样本、细胞样本混在一起时,命名不规范很容易引起下游分析错误。
2.2 禁止使用模糊缩写
尽量避免“final”“new”“test”“v2”这类含义不清的后缀。也不要频繁覆盖旧文件。保留版本号更稳妥,例如分析脚本、参考基因组、质控报告都应保留版本痕迹。
测序数据存储最怕“最后一个文件到底是不是最终版”。 只要版本不清,结果就很难复现。对于发表、答辩和审稿,版本追踪比文件数量更重要。
3. 区分原始数据、处理数据和分析结果
3.1 原始数据必须只读保存
原始数据是测序仪下机后的第一份记录,通常是 Raw data。它是后续分析的基础,不能随意改名、覆盖或重复编辑。建议采用只读权限,至少保留一份独立备份。
原始数据一旦被改动,后续所有结果都可能失去证据链。 这在临床研究、转化医学和发表审稿中尤其敏感。若只保留处理后的文件,往往无法回溯到最初质量。
3.2 处理数据要保留中间版本
质控后的 Clean data、比对后的 SAM/BAM 文件、过滤后的表达矩阵,都应保留关键中间结果。这样在参数调整时,可以直接回到某一阶段,而不是重新跑全流程。
保留中间文件,不是浪费空间,而是节省分析时间。 对于大规模测序项目,重新计算的代价通常远高于存储成本。尤其是样本数多、分析链条长时,中间版本非常重要。
4. 控制格式与容量,提升存储效率
4.1 优先保留通用格式
高通量测序常见文件包括 FASTA、FASTQ、SAM、BAM。FASTA 更偏序列展示,FASTQ 承载原始测序数据,SAM 是比对信息文本格式,BAM 则是 SAM 的二进制压缩形式,体积更小、检索更快。
在测序数据存储中,格式选择直接影响空间占用和调用效率。 例如比对结果若长期保存,通常 BAM 比 SAM 更适合归档。原始数据则应按项目要求保留 FASTQ,便于复查和重分析。
4.2 大文件要建立容量预估
测序深度、样本数量、读长和分析流程都会影响存储压力。比如全基因组重测序、转录组测序、small RNA 测序,数据量差异很大。项目启动前就应估算容量,避免中途存储不足。
可按以下顺序评估:
- 样本数。
- 单样本数据量。
- 是否保存原始图像或原始测序文件。
- 是否长期保留 BAM、矩阵、图表和脚本。
容量预估越早,项目越稳定。 这也是测序数据存储的基础管理动作。
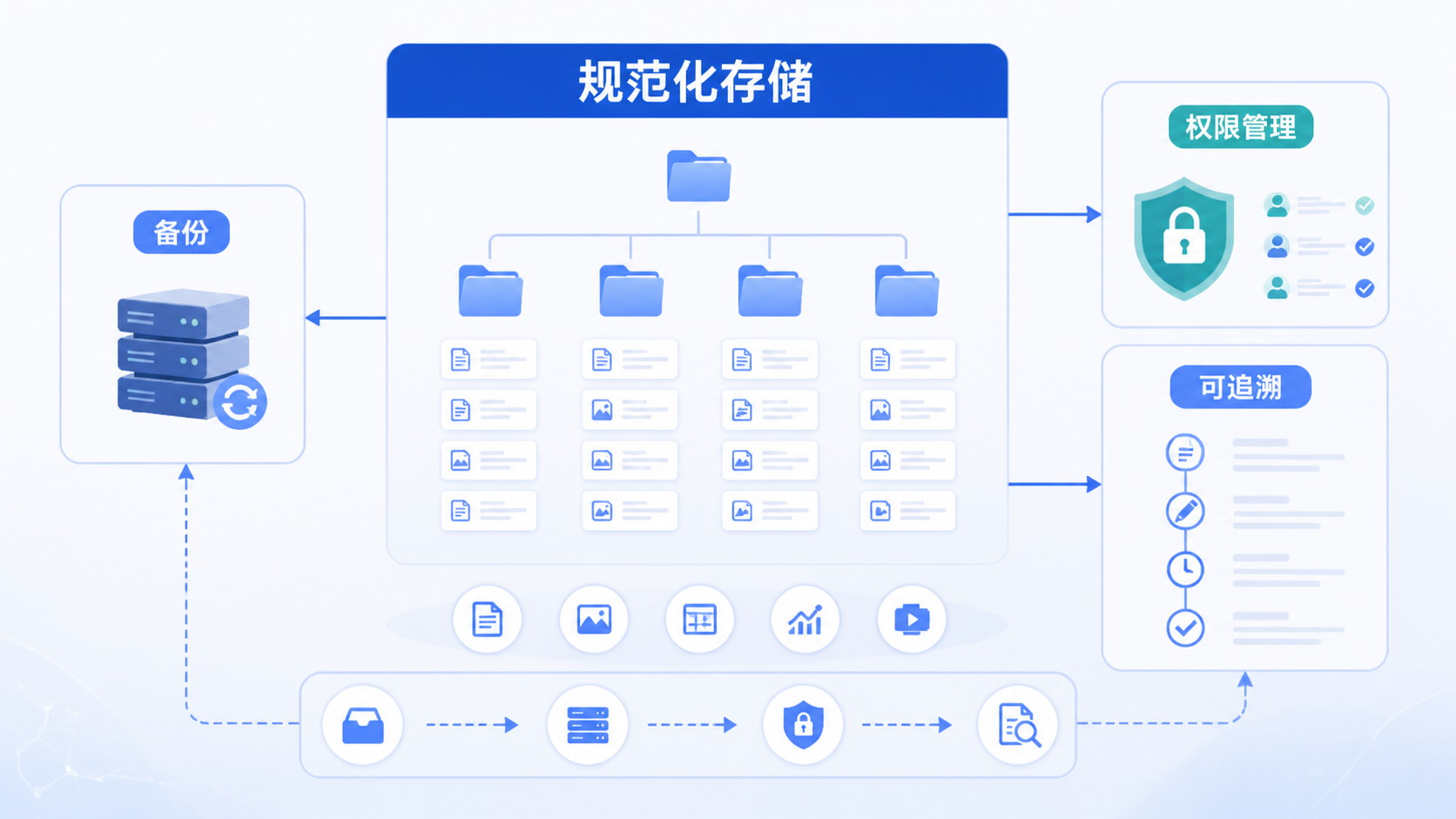
5. 做好备份、权限和审计
5.1 至少保留双重备份
测序数据不可只放在单一硬盘或单台电脑上。建议采用本地存储加服务器备份,或服务器加离线备份的组合。关键项目可增加异地备份。
备份的重点不是“有没有备份”,而是“能不能恢复”。 备份文件要定期抽查可读性,确认不是损坏文件。对于长期项目,最好设定固定恢复演练周期。
5.2 权限管理要分级
不同角色对测序数据的需求不同。实验人员、分析人员、项目负责人和外部合作方,权限应有区分。原始数据、临床信息、样本编码尤其需要更严格的访问控制。
权限管理直接关系到数据安全和合规性。 在涉及患者信息和临床队列时,这一点尤其重要。审计记录也应保留,方便追溯谁在何时修改过什么内容。
6. 让数据可追溯,才能真正可复现
6.1 保存分析参数和软件版本
同一批测序数据,用不同软件版本、参考基因组和参数,结果可能不同。因此,除了保存文件,还应保存:
- 软件名称和版本
- 参考数据库版本
- 关键参数
- 分析日期
- 操作人员
没有元数据的测序数据存储,只是“堆文件”。 真正有价值的是文件背后的分析条件。科研复现、论文补充材料、课题结题都需要这些信息。
6.2 建立标准交付清单
项目结束时,不应只交付一堆压缩包。更合理的做法是同步提供数据清单、样本对应表、流程说明和结果摘要。这样接手人员可以快速判断数据是否完整。
标准化交付能显著降低沟通成本。 对课题组内部协作、医院科室合作、企业联合项目都很实用。测序数据存储如果能和交付流程一起设计,后期管理会轻很多。
总结Conclusion
测序数据存储的关键,不是简单保存文件,而是建立一套可追溯、可备份、可复现的规范体系。核心就是六点:分层、命名、区分原始与处理数据、控制格式与容量、备份和权限、保留分析元数据。把规则前置,才能减少返工、避免丢失,也让研究结果更可信。
如果你需要更高效地管理测序项目,建议结合解螺旋品牌的专业资源与支持,进一步提升数据整理、归档和分析效率。
- 引言Introduction
- 1. 先建立清晰的数据分层
- 2. 统一命名规则,避免样本混淆
- 3. 区分原始数据、处理数据和分析结果
- 4. 控制格式与容量,提升存储效率
- 5. 做好备份、权限和审计
- 6. 让数据可追溯,才能真正可复现
- 总结Conclusion