引言Introduction
单碱基变异数据分析,核心难点不是“能不能做”,而是“如何做得准”。从标准化到降维,再到聚类和差异分析,每一步都可能影响最终结论。如果前期筛选和统计方法不稳,后面的生物学解释就会偏。
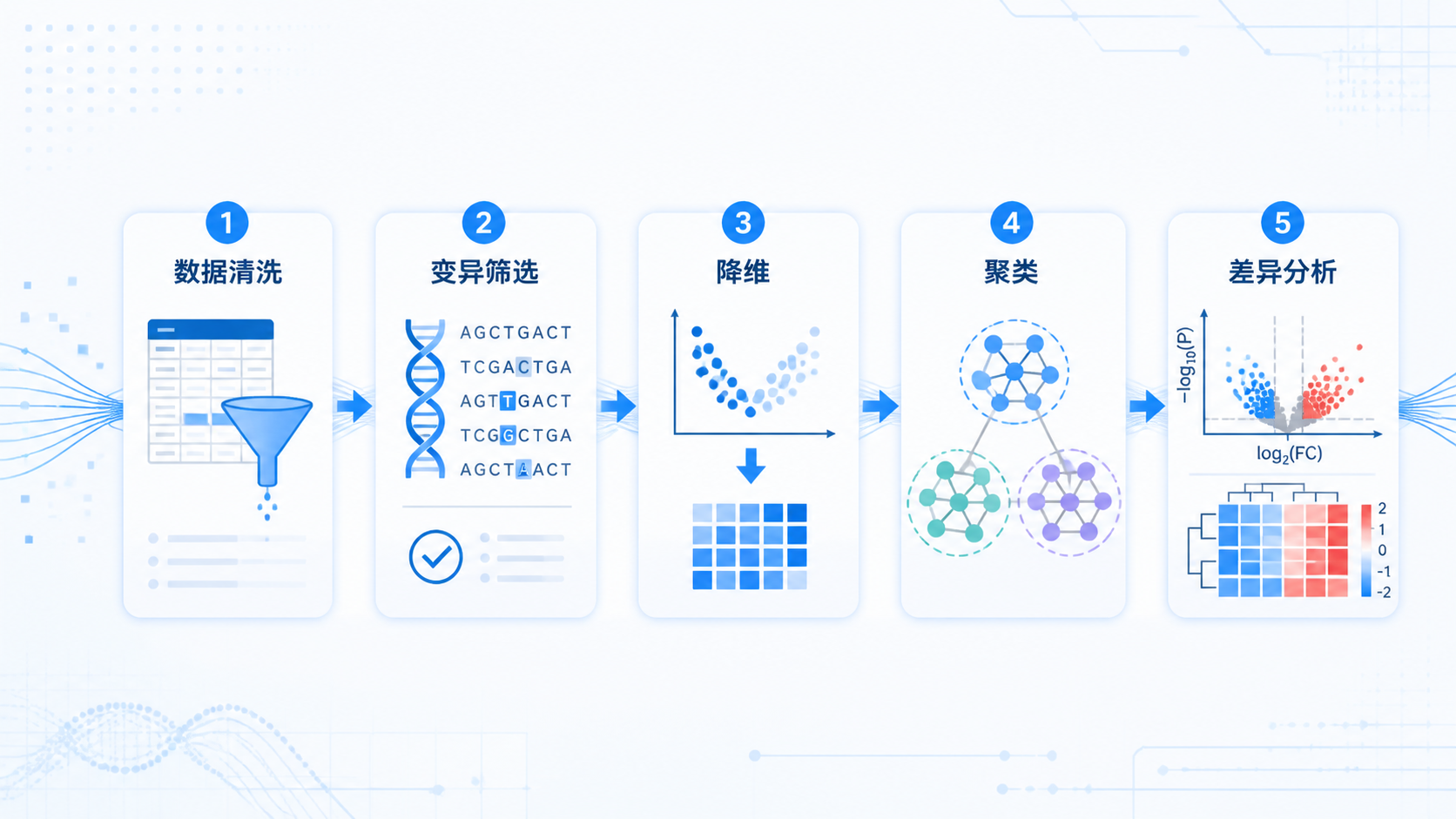
1. 先把单碱基变异数据的输入层做稳
1.1 标准化和环境清理是第一步
在进入正式分析前,先清空环境,再加载所需R包和已保存的标准化结果。这一步看似简单,却直接决定后续结果是否可重复。对于单碱基变异数据,任何残留对象或错误版本的包,都会放大分析误差。
标准化的价值在于统一不同样本的量纲,减少测序深度和技术噪音的干扰。只有输入层稳定,后续的变异筛选、降维和聚类才有可靠基础。
1.2 先看数据质量,再谈精细分析
单碱基变异数据并不是越多越好。真正重要的是数据是否足够稳定、是否存在明显偏差。建议先检查:
- 样本间分布是否一致。
- 是否存在异常高噪音基因。
- 变异信号是否集中在少数位点。
先做质量判断,再决定分析策略,这是提高准确率的关键。
2. 用变异性筛选缩小分析范围
2.1 评估基因变异性,锁定高信息量位点
知识库流程中,第一项核心操作是评估基因的变异性,计算基因在样本中的显著性,并可视化结果。常见做法是以平均log表达量为横坐标,以变异系数为纵坐标,观察整体趋势。
这类图的作用很明确。它能帮助研究者区分“稳定基因”和“高变异基因”。通常会进一步挑选变异程度较高的前2,000个基因,以降低计算量并提升信噪比。
对于单碱基变异数据,这一步尤其重要,因为后续降维和聚类都依赖高质量特征集。
2.2 为什么要控制特征数量
如果把所有位点都纳入分析,维度过高会带来两个问题:
- 计算成本显著上升。
- 噪音位点会稀释真实信号。
因此,筛选高变异特征不是“减少信息”,而是“保留更有用的信息”。单碱基变异数据分析的精度,往往取决于你保留下来的特征是否真正能区分样本。
3. 降维决定你能否看清结构
3.1 小数据集优先PCA
进入降维阶段后,小数据集可以使用PCA分析。PCA的优势是结果直观,便于快速判断样本是否按主要变异来源分开。它适合做初筛,也适合做整体结构判断。
在实际分析中,PCA通常作为第一步探索工具。它能帮助研究者确认:
- 样本是否聚成团。
- 是否存在离群点。
- 主变异轴是否合理。
3.2 大数据集可用IRLBA
当数据规模较大时,可使用IRLBA方法。这是一种基于奇异值分解(SVD)的降维方法,适合在大规模矩阵上提高计算效率。对于单碱基变异数据,IRLBA的价值在于兼顾速度和稳定性。
如果样本量较大、特征较多,直接跑传统PCA可能效率偏低。IRLBA能在保持主要结构信息的前提下,减少计算负担。
3.3 t-SNE更适合展示局部结构
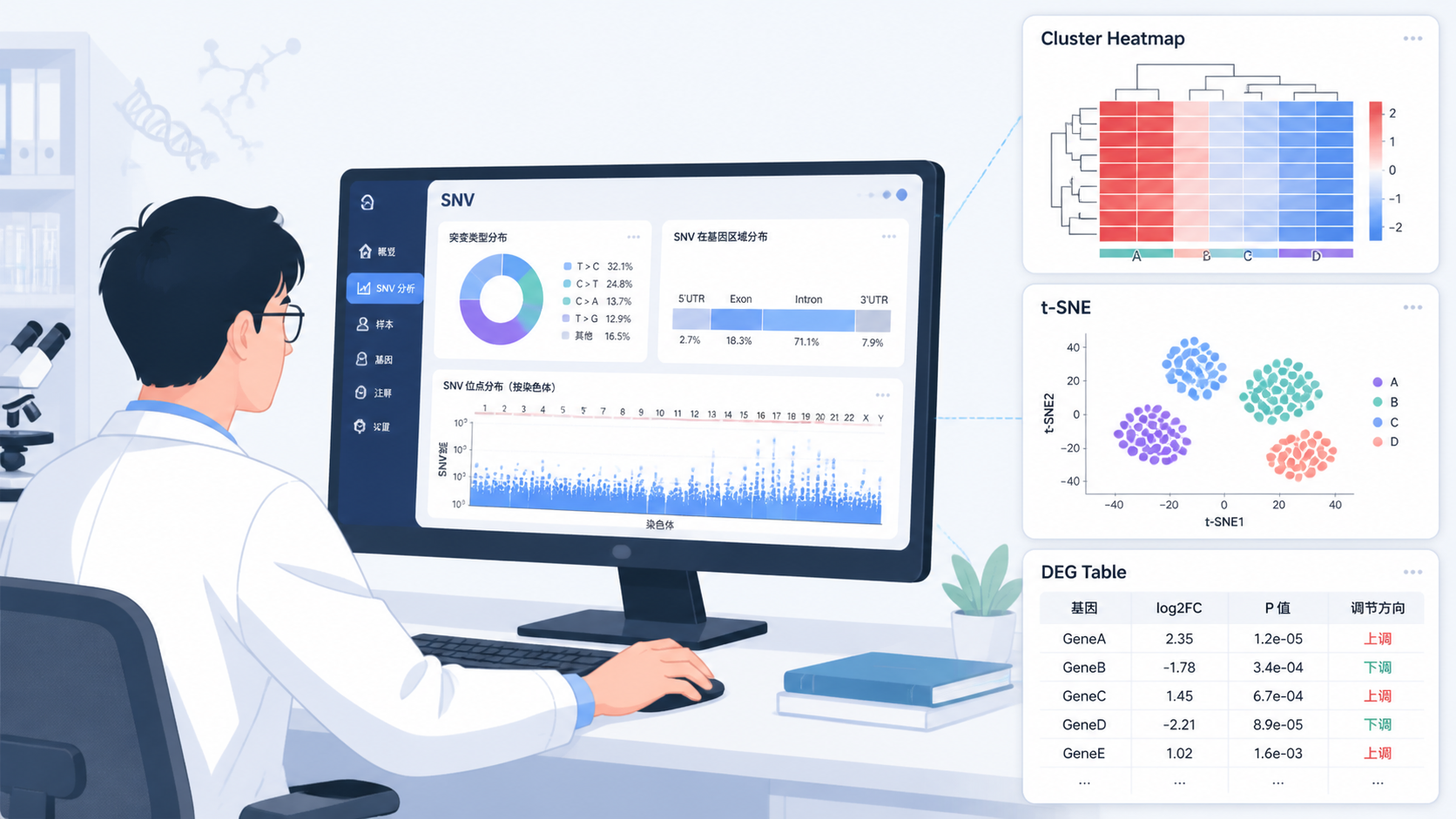
除了线性降维,还可以运行t-SNE进行非线性降维。知识库中明确提到,使用变异程度最大的2,000个基因进行分析后,可以比较PCA、IRLBA和t-SNE三种结果,选择效果最佳的图。
t-SNE的优势在于更容易呈现局部邻域关系,适合观察细胞或样本是否在二维空间中自然分开。如果你的目标是展示单碱基变异数据的分群效果,t-SNE通常更有表现力。
4. 聚类要兼顾稳定性和可解释性
4.1 先层次聚类,再动态剪切
知识库流程中,聚类采用的是层次聚类,再使用动态剪切术进行再次聚类,最终得到8类细胞。这个策略的好处是分层清晰,便于逐步确认结构。
对单碱基变异数据来说,先做层次聚类可以看出整体相似性。再用动态剪切进行细分,有助于从粗分群过渡到精细分群。这种两步法比直接硬分群更稳。
4.2 聚类结果必须回写并可视化
聚类结果要复制到样本对象中,再进行可视化展示。不同颜色对应不同标签,能够直观看到细胞分布情况。知识库中指出,t-SNE下不同类型细胞基本没有重叠,说明聚类效果较好。
这一步不是简单“画图”,而是在验证分析结果是否具有可解释性。若不同簇明显重叠,就需要回头检查特征筛选、降维参数或聚类策略。
5. 差异分析是精准解释的最后一步
5.1 多种统计检验交叉验证
在聚类之后,可以使用t检验、威尔逊秩和检验和二项分布来寻找差异基因,并将结果保存到文件中。这类多方法并行的策略,能减少单一统计假设带来的偏差。
知识库中还提到,每个聚类的差异基因分布情况会在文件中查看,包括:
- 基因top排名。
- P值。
- 校正后的P值。
- t检验排名。
- 威尔逊检验排名。
- 二项分布排名。
- log FC差异倍数。
- 各种统计指标。
这些结果共同构成了后续生物学解释的依据。对于单碱基变异数据,差异分析不是终点,而是把“聚类结果”转化为“机制线索”的桥梁。
5.2 结果保存和复核不能省
分析完成后,必须把结果保存到文件中。这样做有两个好处。第一,便于复现。第二,便于后续交叉验证。如果没有完整保存排名、P值和校正P值,后续很难追溯分析逻辑。
对科研人员来说,精准分析不是一次性完成,而是每一步都可追踪、可复查、可解释。
总结Conclusion
单碱基变异数据要想精准分析,关键在于三点。第一,输入层稳定,标准化和环境控制要先做好。第二,先筛高变异特征,再做降维和聚类,减少噪音干扰。第三,用多种统计检验做差异分析,并保留完整结果,保证可追溯性。真正高质量的单碱基变异数据分析,不是追求复杂,而是追求稳、准、可解释。
如果你希望把这些步骤更高效地落地到实际项目中,可以借助解螺旋 的专业内容与分析支持,帮助你更快完成从数据筛选到结果解读的全流程。
- 引言Introduction
- 1. 先把单碱基变异数据的输入层做稳
- 2. 用变异性筛选缩小分析范围
- 3. 降维决定你能否看清结构
- 4. 聚类要兼顾稳定性和可解释性
- 5. 差异分析是精准解释的最后一步
- 总结Conclusion