引言Introduction
测序项目常见问题,不是“没有数据”,而是测序数据规范不统一 。文件命名乱、格式混用、质控标准不一,会直接拖慢分析进度,甚至影响结论可信度。
1. 为什么测序数据规范是项目成败的第一步
1.1 从原始数据到可分析数据,差一步都不行
高通量测序的结果,通常先经过原始数据、质控数据,再进入比对和下游分析。测序数据规范的核心,就是让每一步输入都可追溯、可复现、可交付。
常见文件包括 FASTA、FASTQ、SAM 和 BAM。
其中,FASTQ最常用于存储测序原始数据。它保留序列和质量值。
SAM用于存储比对信息。BAM是SAM的二进制压缩格式,体积更小,检索更快。
1.2 不规范会带来哪些直接损失
如果文件格式、样本信息、版本记录不完整,后果通常很直接。
- 无法快速区分 raw data 和 clean data
- 比对参数难以复核
- 下游差异分析无法复现
- 多批次数据整合时容易出错
对医学生、医生和科研人员来说,测序数据规范不是管理细节,而是结果可信度的基础。
2. 先理解测序数据的标准对象
2.1 原始序列文件的基本类型
在实际项目中,常见输入并不完全相同。
但规范管理的起点,通常是识别文件类型。
- FASTA :用于存储核酸或蛋白序列,常见于参考序列和查询序列
- FASTQ :用于存储测序仪输出的原始序列和质量信息
- SAM :记录 reads 与参考序列的比对结果
- BAM :SAM 的压缩格式,适合长期存储和快速读取
如果项目一开始就没有统一文件类型,后续分析再精细也很难稳定。
2.2 从测序类型反推数据管理重点
不同测序任务,对数据规范的关注点不同。
- 转录组测序,更关注样本分组、文库类型、reads质量
- 全基因组重测序,更关注比对一致性、SNP、InDel、CNV
- small RNA 测序,更关注长度分布和小RNA类别
- circRNA 测序,更关注去除rRNA和线性RNA后的富集效果
也就是说,测序数据规范不是单一模板,而是要和研究目的匹配。
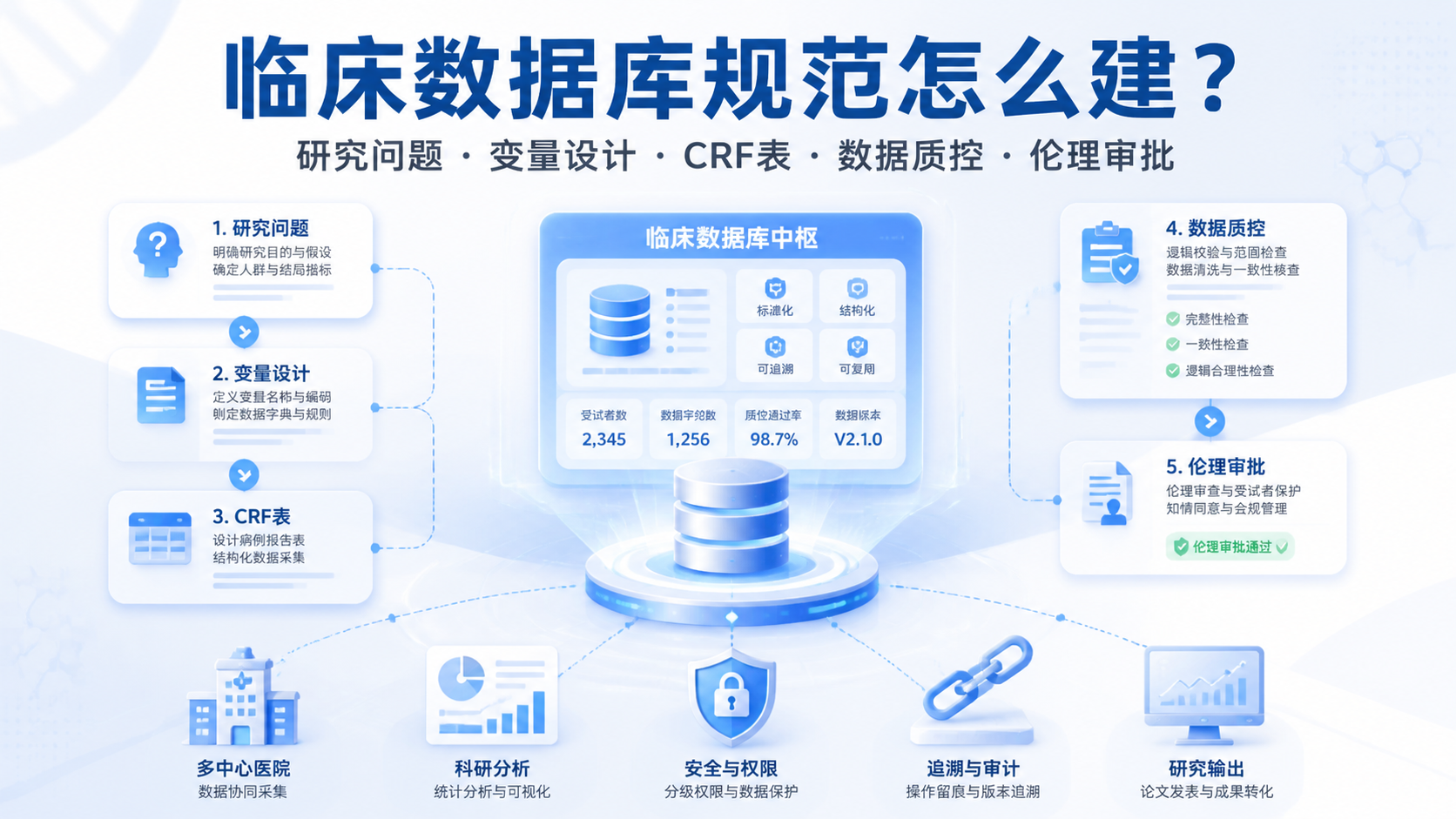
3. 建立测序数据规范的7步流程
3.1 第一步,统一样本编号
样本编号是所有数据的锚点。
建议在采样前就确定规则,并保持全流程一致。
至少要包含以下信息:
- 项目编号
- 组别信息
- 样本序号
- 批次信息
例如,同一研究中,肿瘤组和对照组必须能一眼区分。
样本编号一旦混乱,后续统计和追踪都会失效。
3.2 第二步,明确文件命名规则
文件名要能同时反映样本和数据状态。
推荐在命名中体现以下内容:
- 样本ID
- 测序类型
- 数据状态,如 raw 或 clean
- 日期或批次号
这样做的好处很明显。
即使文件量很大,也能快速定位文件来源和用途。
规范命名是最便宜的时间节省方式。
3.3 第三步,固定原始数据与分析数据的边界
原始数据和分析数据必须分开管理。
原始数据是测序仪下机得到的 raw data。
清洗后的数据是 clean data。
这两类数据不能混存,也不能互相覆盖。
建议至少保留:
- 原始下机文件
- 质控报告
- 清洗后文件
- 比对结果
- 统计分析结果
一旦原始数据被覆盖,项目就失去了最关键的证据链。
3.4 第四步,建立质控标准
质控是测序数据规范中最关键的一环。
它决定哪些数据能进入下游分析。
常见控制点包括:
- 序列质量
- 接头污染
- 低质量 reads
- 过短 reads
- 无法可靠比对的序列
不同项目的阈值可不同,但标准必须预先写明。
没有预设标准的质控,等于把判断交给经验而不是流程。
3.5 第五步,记录文库和测序信息
仅有文件还不够。
还要记录文库构建和上机条件。
至少包括:
- 样本来源
- 文库类型
- 片段长度范围
- 单端或双端测序
- 测序平台
- 读长
- 测序深度
比如,测序深度等于总数据量与基因组大小的比值。
这些元数据决定了结果能否解释,也决定了后续能否复现。
3.6 第六步,规范格式转换和版本管理
测序数据在分析中常会经历格式转换。
例如,FASTQ 进入比对后,转为 SAM,再压缩为 BAM。
每一次转换都要记录版本。
包括软件版本、参数、参考基因组版本和注释版本。
如果这些信息缺失,结果很难重复得到。
版本管理不是额外工作,而是科研合规的一部分。
3.7 第七步,保留可追溯的分析链
从原始数据到最终图表,中间每一步都应可追踪。
建议保留:
- 数据来源
- 处理步骤
- 关键参数
- 输出文件路径
- 结果解释说明
对于临床相关研究或多中心合作项目,这一点尤其重要。
可追溯性越强,数据越能经得起复核。
4. 高质量测序数据规范,重点看这3类场景
4.1 组学研究场景
转录组、lncRNA、miRNA、circRNA 和蛋白芯片项目,通常样本多、文件多、批次多。
这类项目最容易出现命名不一致和分组错误。
建议重点检查:
- 分组是否与实验设计一致
- 是否存在重复样本混入
- 是否有跨批次偏差
- 是否保留原始质控记录
4.2 临床样本场景
临床样本更强调来源和链路。
尤其涉及患者信息时,匿名化和编号规则要先定好。
建议做到:
- 采样、提取、建库、上机全程编号统一
- 数据访问权限分级管理
- 结果文件单独归档
- 所有修改留痕
4.3 外包检测场景
很多测序项目会交由公司完成。
但这不代表内部可以放松规范。
通常公司会提供基础分析。
个性化分析、复核和二次解读,还是需要研究者自己管理。
如果前期没有把测序数据规范定清楚,外包交付也很难直接用于发表或申报。
5. 为什么很多团队会在分析阶段返工
5.1 问题不在技术,而在前置管理
很多返工并不是因为测序平台不稳定。
而是因为前期缺少统一标准。
常见返工原因包括:
- 样本ID不一致
- 文件后缀混乱
- 参考版本不统一
- 比对参数未记录
- 结果表缺少说明
这些问题看似琐碎,实际会直接影响统计和结论。
5.2 用规范化流程减少重复劳动
测序数据规范做得好,最大的价值是减少沟通成本和重复计算。
尤其在多人协作中,统一模板比个人习惯更重要。
一个成熟流程至少应包含:
- 样本登记表
- 文件命名表
- 质控阈值表
- 分析记录表
- 结果归档表
总结Conclusion
测序项目想要高效、可信、可复现,关键不只在平台和算法,更在测序数据规范 。从样本编号、文件命名,到质控、版本管理、结果归档,7步流程的目标只有一个,建立稳定的数据链条。对于需要更高效率完成测序项目管理和结果交付的研究团队,可以结合解螺旋品牌的专业支持,快速把数据规范、分析流程和交付标准统一起来。 
- 引言Introduction
- 1. 为什么测序数据规范是项目成败的第一步
- 2. 先理解测序数据的标准对象
- 3. 建立测序数据规范的7步流程
- 4. 高质量测序数据规范,重点看这3类场景
- 5. 为什么很多团队会在分析阶段返工
- 总结Conclusion