引言Introduction
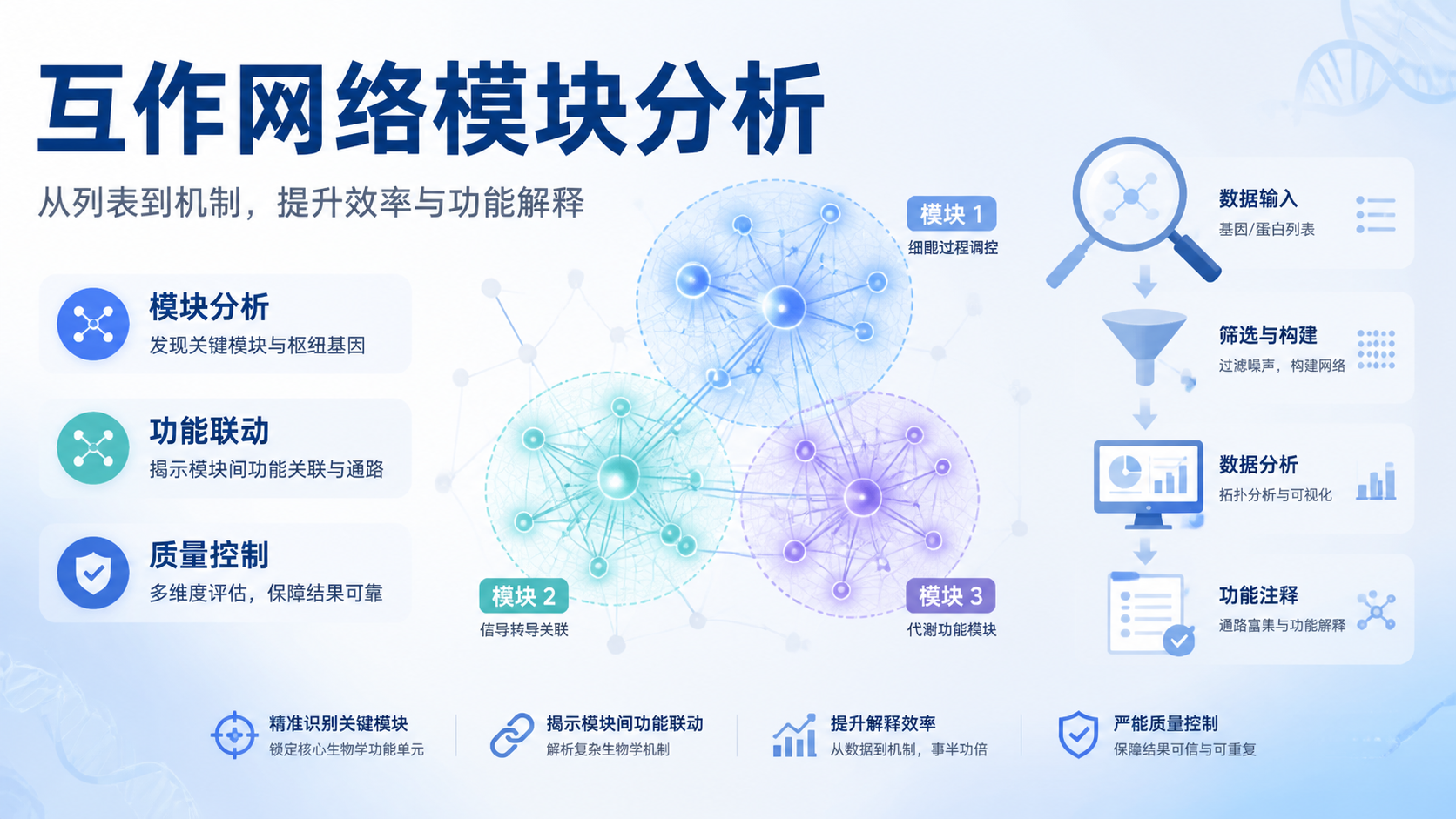
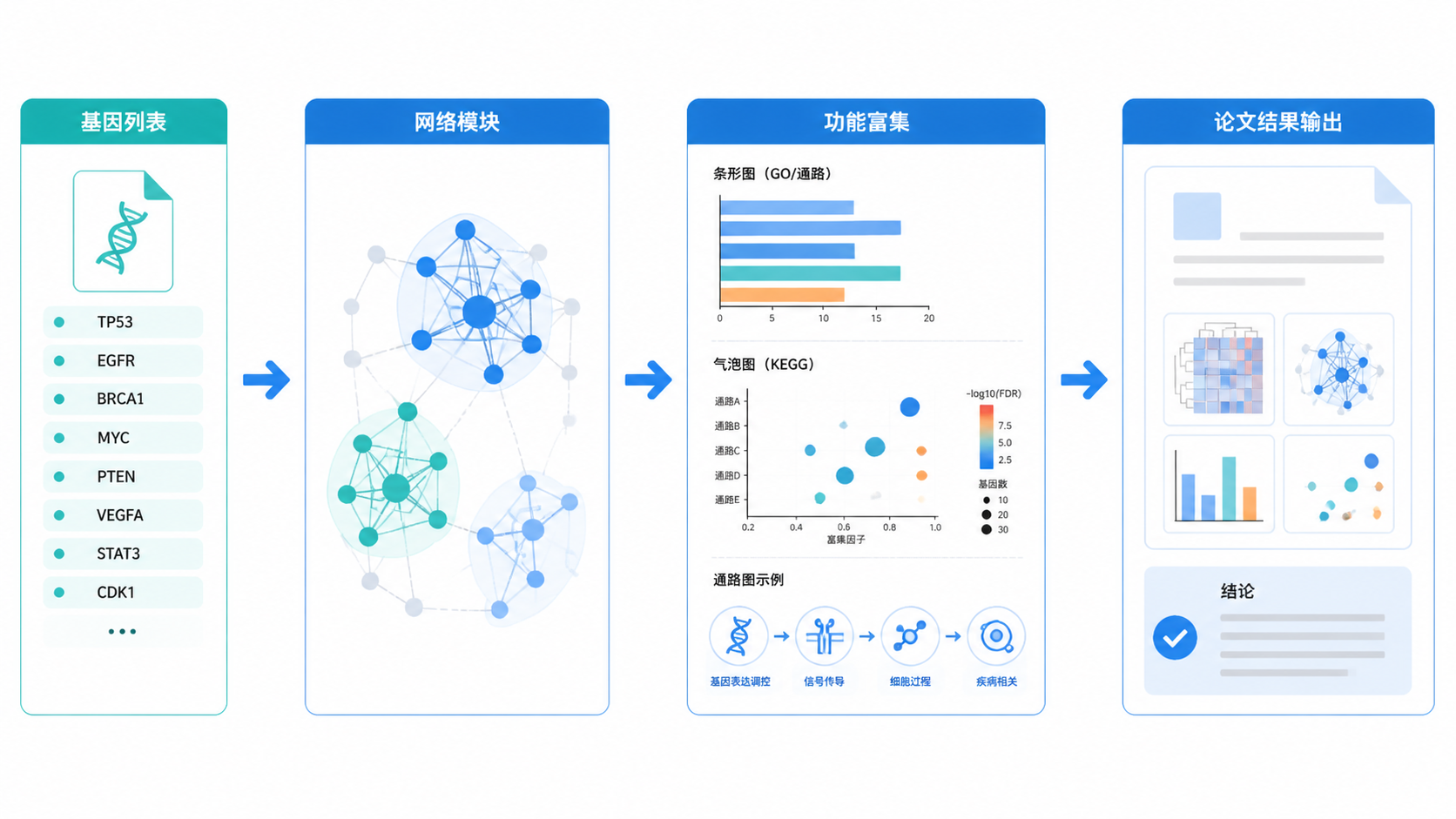
互作网络模块分析是理解分子机制的关键一步。面对一份基因或蛋白列表,很多人知道“有互作”,却不知道“哪些互作共同构成功能模块”。这正是模块分析的价值。它能把零散信号变成可解释的生物学单元,帮助你更快锁定通路、疾病相关基因和潜在靶点。

1. 互作网络模块分析解决的核心问题
1.1 从“列表”走向“系统”
在组学研究中,常见起点是一组差异基因、蛋白或药物靶点。但单个分子往往难以解释表型。互作网络模块分析的核心作用,就是把分子放回系统背景中,识别彼此协同工作的子网络。
在 NetworkAnalyst 中,输入可以是基因列表、表达谱数据,甚至来自 GEO 的挖掘结果。随后可映射到蛋白互作网络、基因调控网络、疾病网络和药物网络。这样做的意义在于,研究对象不再是孤立节点,而是具有生物学意义的模块。
1.2 模块比单点更接近真实机制
真实生物过程通常由一组相关分子共同驱动,而不是单一基因决定。PPI 网络中,蛋白之间可能通过复合物形成、信号传递或功能关联共同作用。模块分析把高度关联的节点聚在一起,更接近真实调控单元。
这也是为什么模块分析常被用于疾病机制研究、标志物筛选和药物靶点优先级排序。 相比逐个基因解读,模块更稳定,也更容易和 KEGG、GO 等功能结果建立对应关系。
2. 互作网络模块分析为什么能提升研究效率
2.1 缩小解释范围,提升可读性
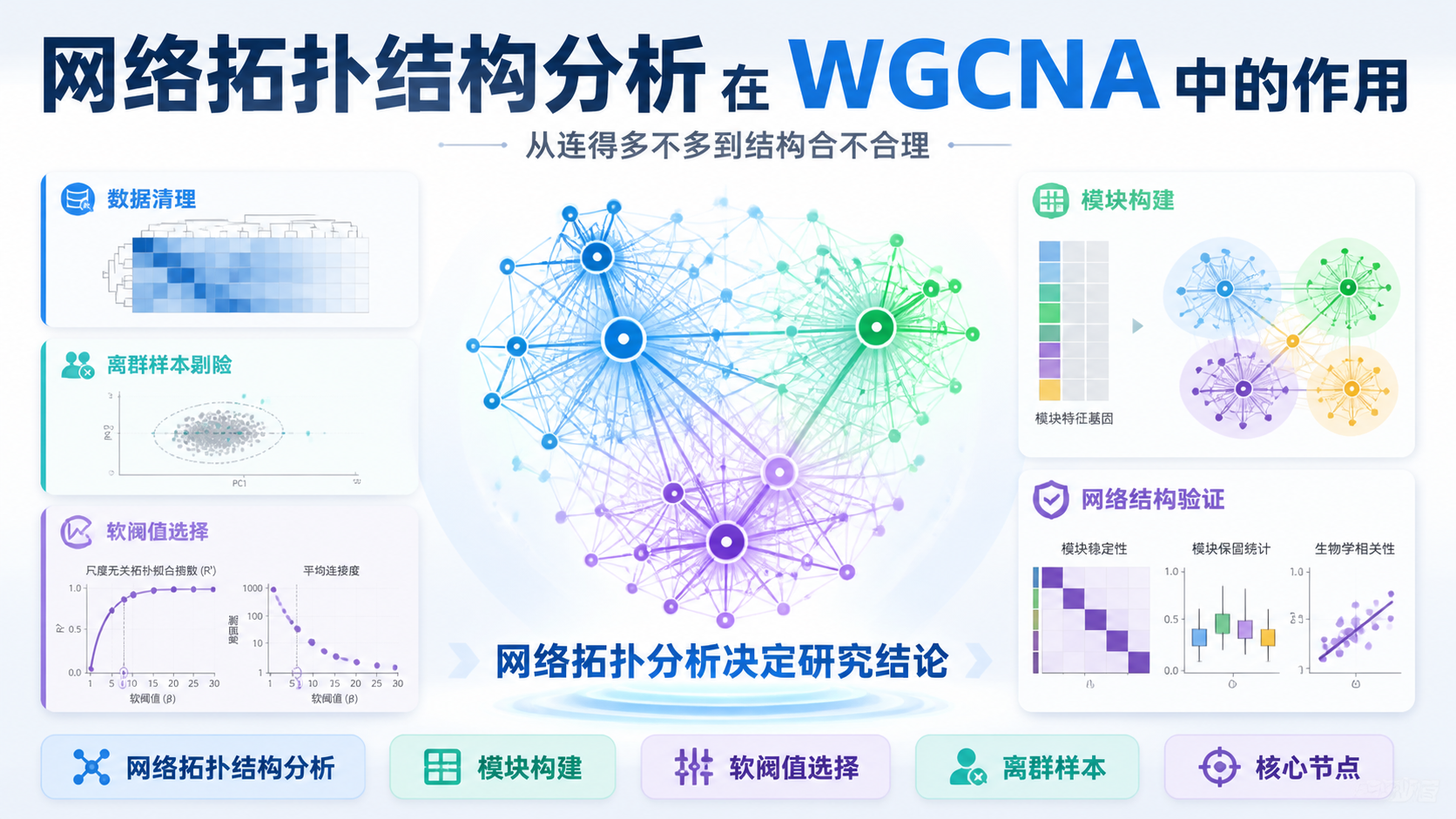
当网络节点很多时,整张图往往很难解释。课程中也强调,后续分析更推荐使用 200 到 2000 个节点 的网络。太大难以解释,太小又缺乏系统性。
模块分析能把大网络切成多个子网络。比如 NetworkAnalyst 会生成较大的 continent 和多个较小的 islands。这样,研究者可以先关注包含关键基因的模块,再做富集分析和文献验证。模块化之后,网络阅读难度明显下降。
2.2 快速定位高价值候选基因
模块分析不是只看连接数,还看节点在模块中的组织位置。对于互作网络模块分析,常见流程是先构建网络,再进行模块识别,然后对感兴趣模块做功能富集。这样能把“显著但零散”的基因,筛选为“位于关键模块中的候选基因”。
实际分析中,常见做法包括:
- 先筛选差异分子或高变异基因。
- 映射到 PPI 或调控网络。
- 识别模块。
- 对模块做 KEGG 或 GO 富集。
- 再回到原始数据验证表达趋势。
这条路径比单纯看差异倍数更适合机制研究。
3. 互作网络模块分析的常用方法和参数
3.1 先建网,再分模块
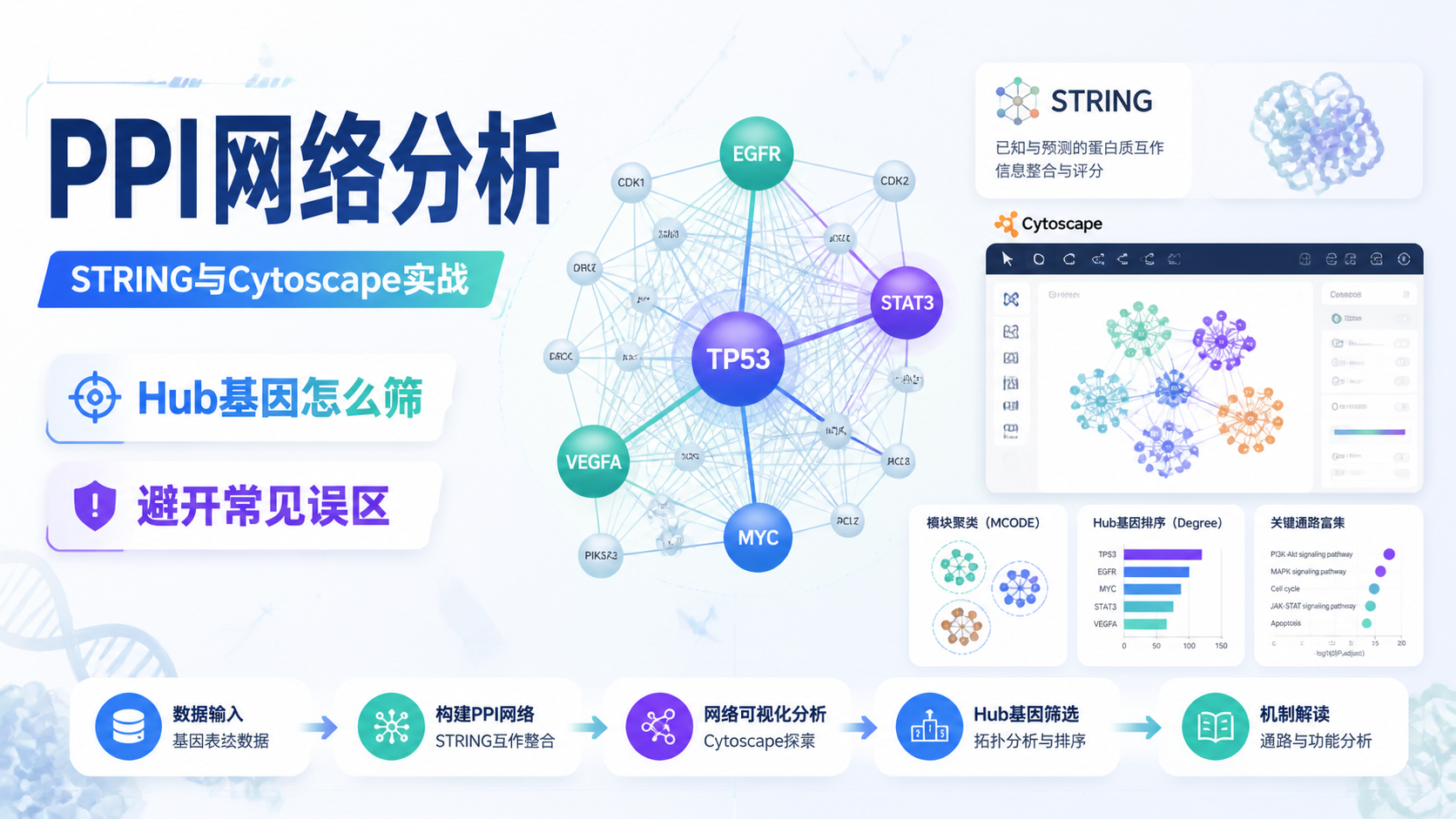
在 NetworkAnalyst 中,模块分析通常从上传数据开始。若是基因列表,可选择物种和 ID 类型;如果 ID 不在支持范围内,也可保留为 Not Specified,继续后续分析,或先用注释文件转换为 Entrez、Ensembl 等常见 ID。
网络数据库选择也很关键。常见模块包括:
- 通用 PPI,如 STRING、IMEx、HuRI、Rolland。
- 组织特异性 PPI,如 DifferentialNet。
- 基因调控网络,如 miRNA、转录因子相关互作。
- 疾病、药物和化合物网络。
- 共表达网络。
数据库不同,得到的模块生物学含义也不同。 因此,模块分析前要先明确研究问题。
3.2 置信度、组织特异性和模块边界
在 STRING PPI 中,互作关系带有置信度评分,范围通常在 400 到 1000。分数越高,证据越强。若勾选 experimental evidence,则意味着互作需要实验支持。
在组织特异性 PPI 中,Filter 可用于筛选组织相关的互作。课程中提到评分范围是 1 到 30。数值越低,网络越“组织特异”;数值越高,越接近跨组织稳定互作。这一步决定了模块是不是“与你研究的组织真正相关”。
4. 为什么模块分析和功能分析必须联动
4.1 模块不做功能解释,就只是图
单看网络图,最多能看到连接关系。但真正有价值的是把模块和功能联系起来。NetworkAnalyst 的 Function Explorer 可以对选中的节点或模块做富集分析,例如 KEGG。
当你勾选感兴趣节点,再选择 “Highlighted nodes” 和对应数据库提交后,就能看到该模块相关通路。这一步能回答两个关键问题:
- 这个模块在做什么。
- 它可能与哪类疾病或生物过程相关。
没有功能分析,模块只是结构。
加上功能分析,模块才变成机制线索。
4.2 模块结果更适合和实验设计衔接
对于医学生、医生和科研人员来说,最终都要回到实验或临床问题。模块分析的优势在于,它能直接支持下一步设计:
- 选模块核心基因做 qPCR。
- 选枢纽节点做敲低或过表达。
- 选关键通路做药理干预。
- 选组织特异模块做疾病分层研究。
这比漫无目的地验证一串差异基因更高效,也更符合研究资源的现实约束。
5. 互作网络模块分析的质量控制要点
5.1 网络大小要适中
分析前要注意节点规模。课程建议后续网络保持在 200 到 2000 个节点之间。原因很直接。网络过大,模块太多,解释成本高。网络过小,系统性不足,容易漏掉关键联系。
5.2 参数设置要与问题一致
如果研究的是组织相关机制,优先考虑组织特异性 PPI。
如果研究的是信号调控,优先考虑基因-miRNA 或转录因子-基因网络。
如果研究的是药物作用机制,优先考虑蛋白-药物或蛋白-化合物网络。
模块分析不是一套参数走天下。 参数选择应服务于科学问题,而不是反过来。
5.3 结果要能导出和复用
NetworkAnalyst 支持将子网络以 SIF 等格式保存,方便继续导入 Cytoscape 或其他软件。对于后续可视化、文稿绘图和补充分析,这一点非常实用。模块分析的结果如果无法复用,价值会明显下降。
总结Conclusion
互作网络模块分析之所以重要,是因为它把分散的分子信息整理成可解释的功能单元。它既能提升网络可读性,也能帮助你更快定位关键模块、通路和候选靶点。对医学生、医生和科研人员来说,这一步往往决定后续机制研究是否清晰、是否可验证。
如果你希望把基因列表、PPI 网络和功能富集真正串起来,建议使用解螺旋的 NetworkAnalyst 教程与实战资源。它能帮助你更规范地完成上传、建网、模块识别和功能分析,少走弯路,更快产出可发表的结果。
- 引言Introduction
- 1. 互作网络模块分析解决的核心问题
- 2. 互作网络模块分析为什么能提升研究效率
- 3. 互作网络模块分析的常用方法和参数
- 4. 为什么模块分析和功能分析必须联动
- 5. 互作网络模块分析的质量控制要点
- 总结Conclusion