引言Introduction
生信网络图分析常让人卡在“图很多、变量很多、先看哪张”的问题上。其实,先抓主变量,再理清关系,再判断网络模块,效率会高很多。如果你想快速看懂文章里的网络图,先掌握筛选、连接、验证这条主线。
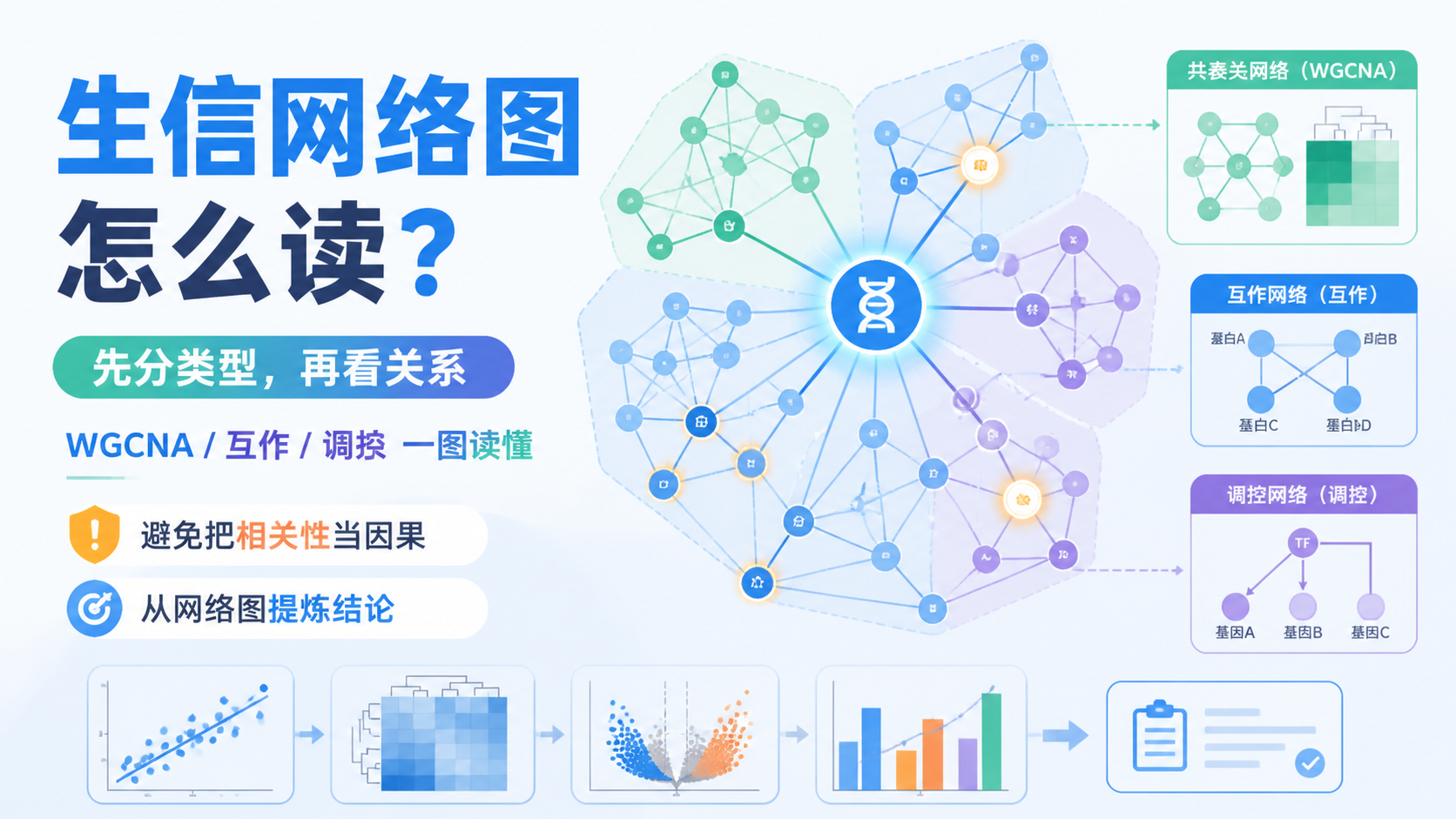
1. 先分清网络图的类型
1.1 网络图不是一类图,先看它在论证什么
在生物信息学论文里,网络图常见于三类场景。第一类是筛选变量,比如差异基因、候选基因、蛋白互作。第二类是关系论证,比如共表达、互作、调控。第三类是临床意义展示,比如预后相关、风险分层、模块相关性。
先判断它属于“筛选图”还是“机制图”,阅读效率会差很多。
如果是火山图、聚类图、PPI图,通常偏筛选。
如果是调控网络、rescue关系、模块-表型关联,通常偏机制。
1.2 读图时不要平均用力
知识库里反复强调一个原则,一篇文章里最该花时间的是中间的核心机制图。
开头图往往是现象和筛选。结尾图多是补充和验证。真正决定文章档次的,常常是中间几张图。
对网络图也一样。
不是每个节点都要细看。
先看分组。再看关系方向。最后看是否有验证。
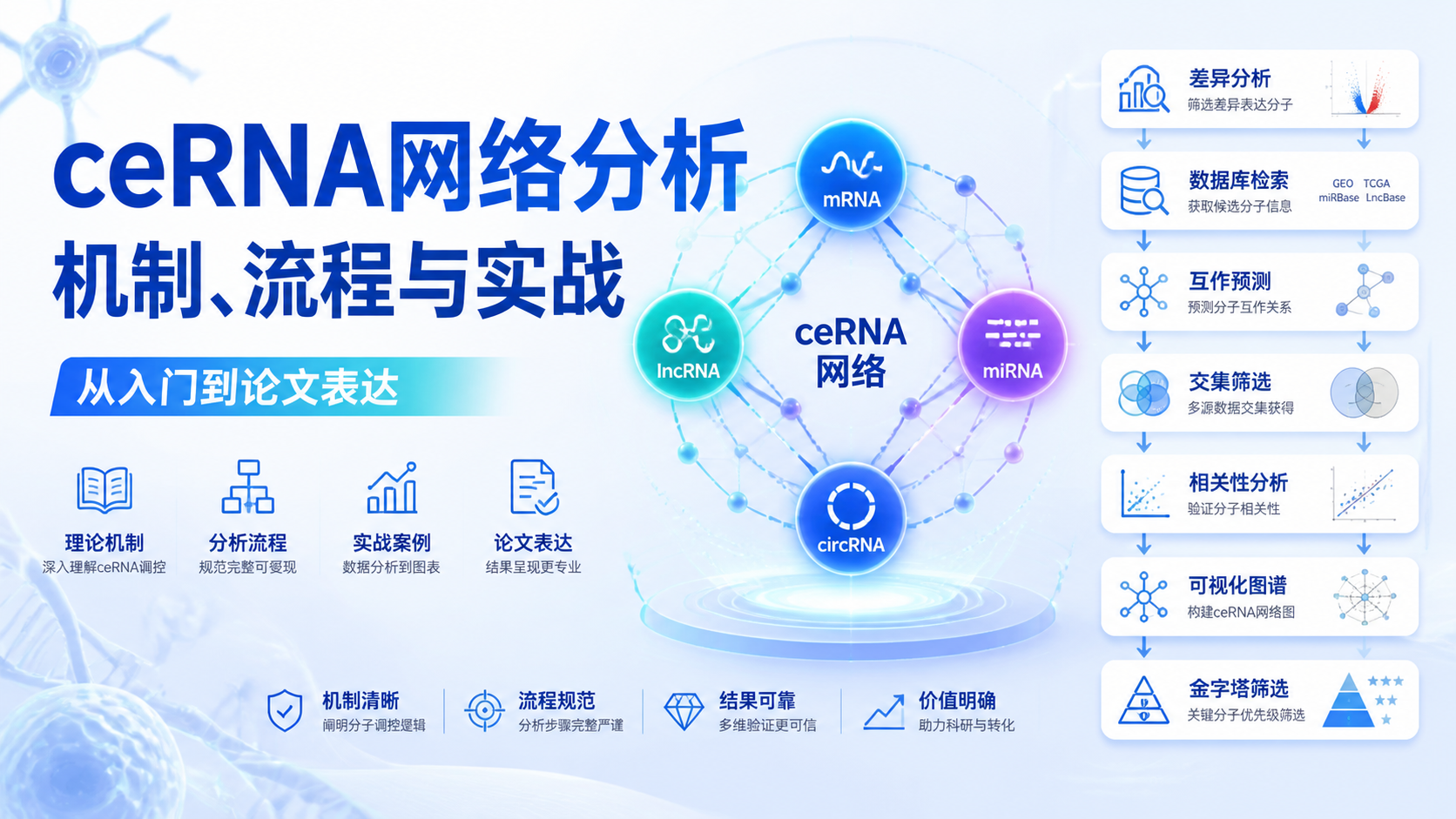
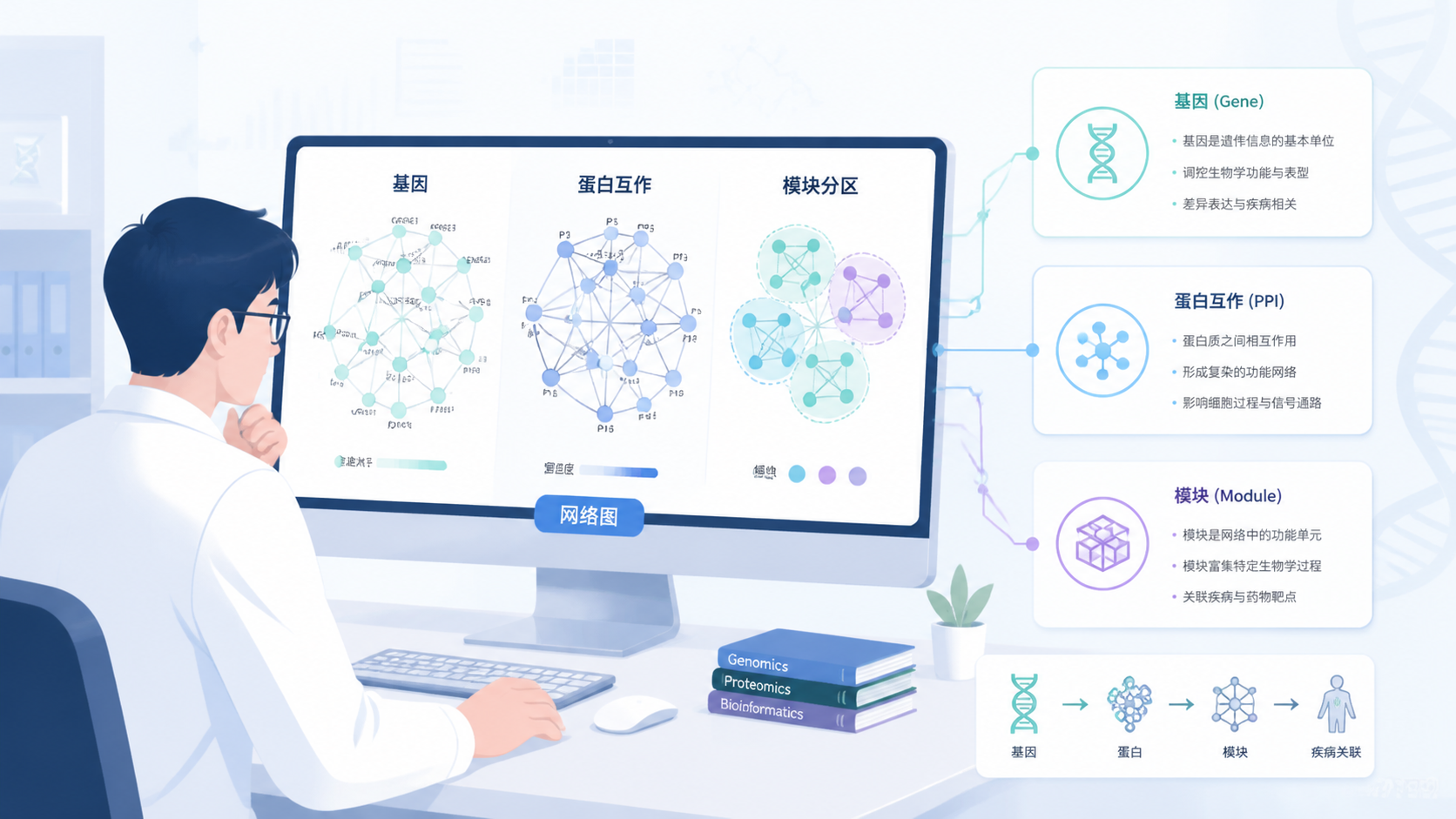
2. 生信网络图分析的核心逻辑
2.1 先找变量,再找关系
做生信网络图分析,第一步不是直接画图,而是确定变量来源。常见来源包括表达矩阵、差异矩阵、临床分组、互作数据库和生存数据。
一个实用顺序是:
- 先筛选候选基因或蛋白。
- 再构建相关性或互作关系。
- 再用模块或节点中心性找关键对象。
- 最后结合表型、临床或实验验证。
没有变量筛选,网络图就只是“连线很多的图”。
有了筛选和验证,网络图才有解释力。
2.2 关系方向要先图形化
在阅读交互效应和调控与表型关系后,最好把假设图形化。
正调控用箭头,负调控用倒T字形。
两个正调控是正正得正。
一个正一个负是正负得负。
两个负调控是负负得正。
这一步非常重要。
图形化不是为了好看,而是为了避免你在复杂网络里迷失。
尤其当文章涉及多个分子、多个分组、多个干预条件时,图形化笔记能明显减少理解偏差。
3. 生信网络图分析常见模块怎么读
3.1 共表达网络,重点看模块而不是单个点
WGCNA是生信网络图分析中很常见的一类。它的核心不是“每个基因长什么样”,而是“哪些基因属于同一模块,哪个模块和表型相关”。
标准流程通常是:
- 数据清理。
- 去除离群样本。
- 选择软阈值。
- 构建网络模块。
- 做模块可视化。
在实践中,常用标准差、中位绝对偏差或全基因方法来筛基因。样本部分则可先做聚类,识别离群样本,再决定是否剔除。
软阈值的选择要平衡无尺度拟合度和平均连接度。
一般会用 pickSoftThreshold 之类的方法看 R 平方、斜率、平均连接度、中位连接度和最大连接度。
不是 R 平方越高越好。连接度太低,网络会过于稀疏。
常见做法是在两者之间找平衡点。
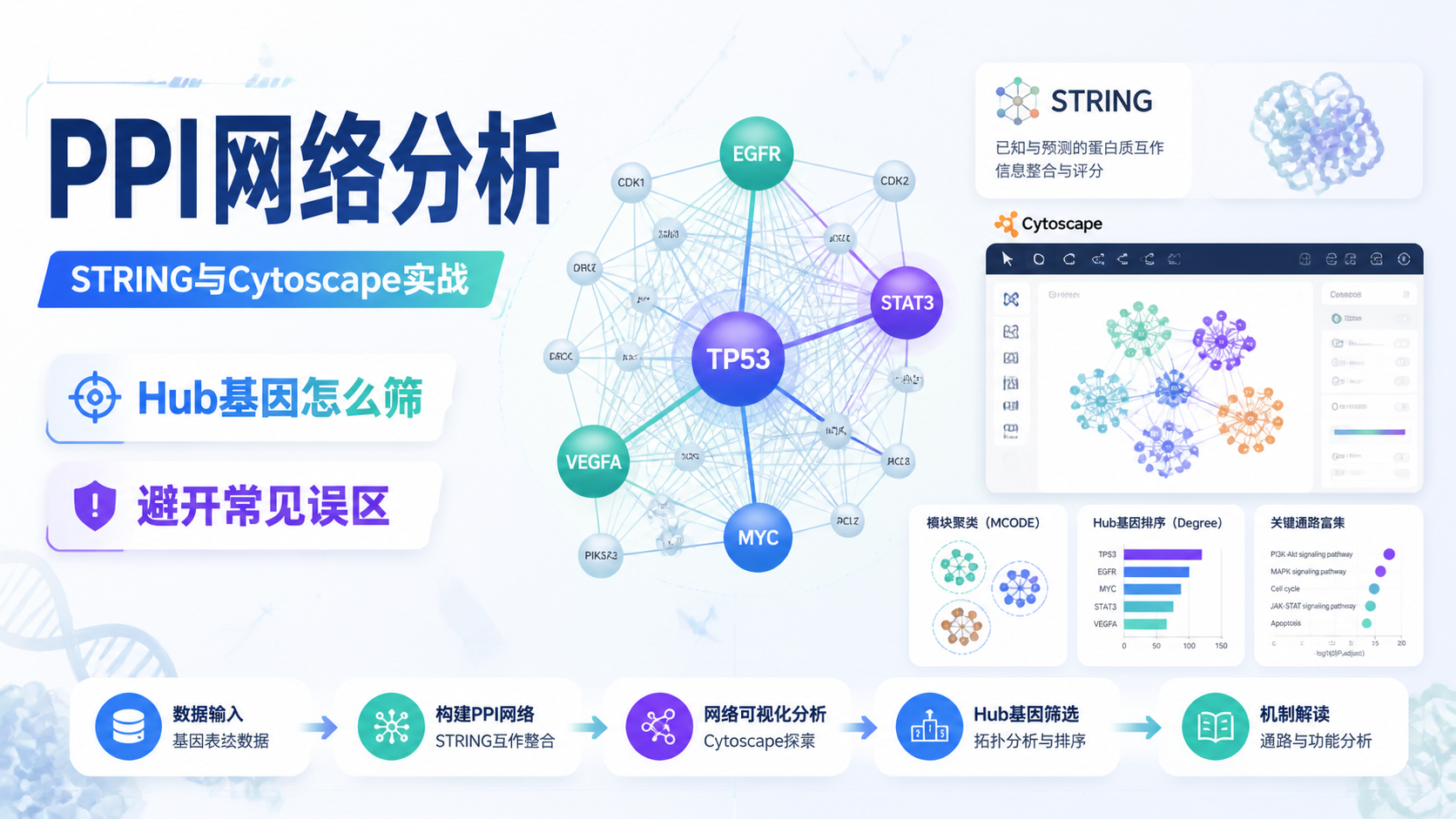
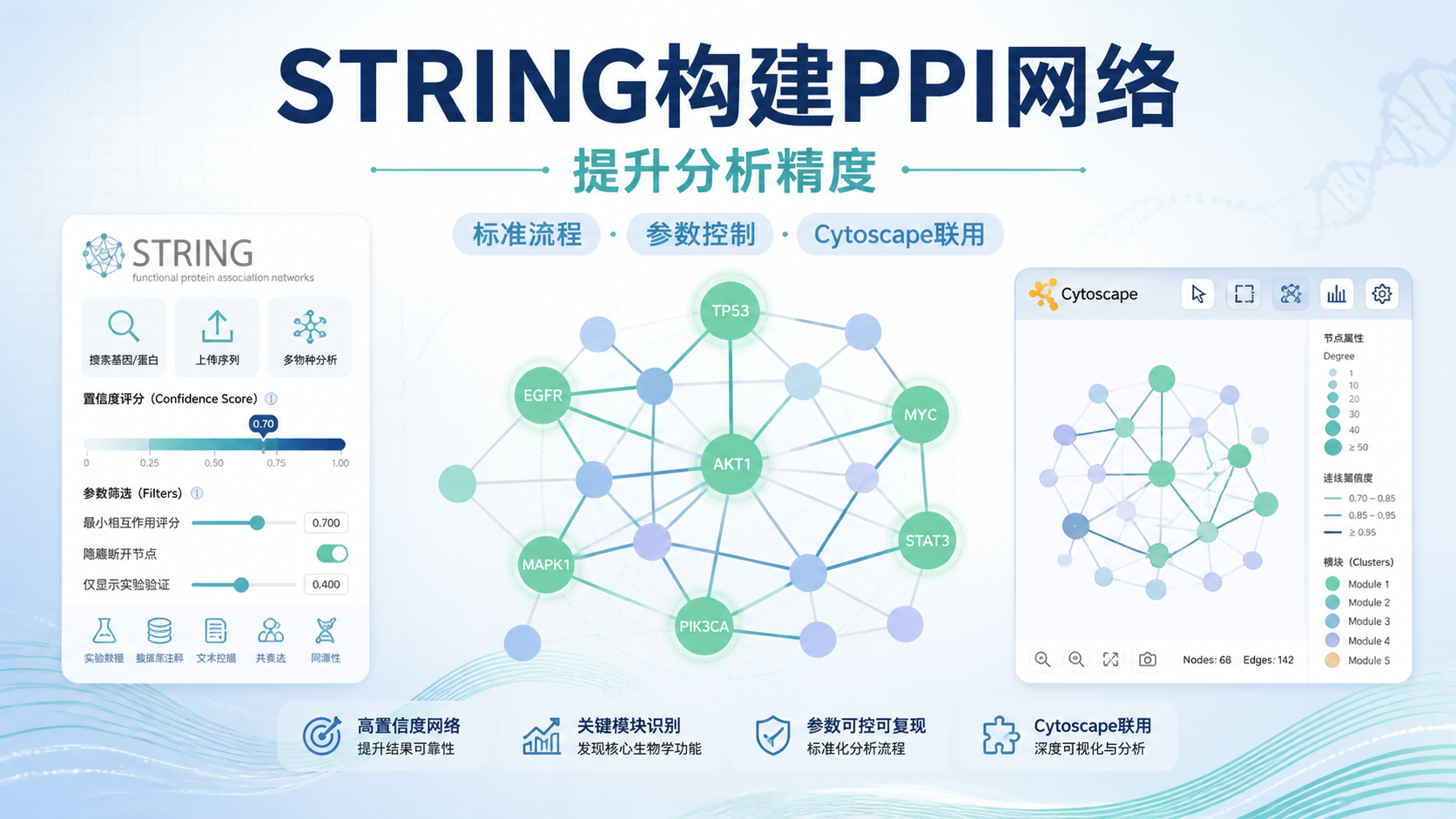
3.2 互作网络,重点看中心节点和连接密度
PPI 网络、Cytoscape 网络、String 互作图,都属于典型的关系图。
这类图通常用于找核心节点、hub 基因或关键蛋白。
读这类图时,重点看三件事:
- 节点是否明显分层。
- 是否存在高连接度节点。
- 是否有实验或数据库支持。
中心节点不等于因果节点。
它只能提示可能的重要性,不能单凭连线数量就下结论。
如果文章后面没有功能实验或临床验证,结论强度就有限。
3.3 调控网络,重点看正负关系和链路长度
调控网络比互作网络更强调方向。
常见形式包括转录因子-靶基因、miRNA-mRNA、lncRNA-轴、蛋白-位点调控等。
这类图要重点关注:
- 谁在上游。
- 谁在下游。
- 是正调控还是负调控。
- 是否存在 rescue 设计。
rescue 实验不复杂,本质是看“回复后表型能不能拉回来”。
它是单因素比较逻辑的延伸。
读图时只要确认谁被操作、谁被回复、回复后表型是否逆转即可。
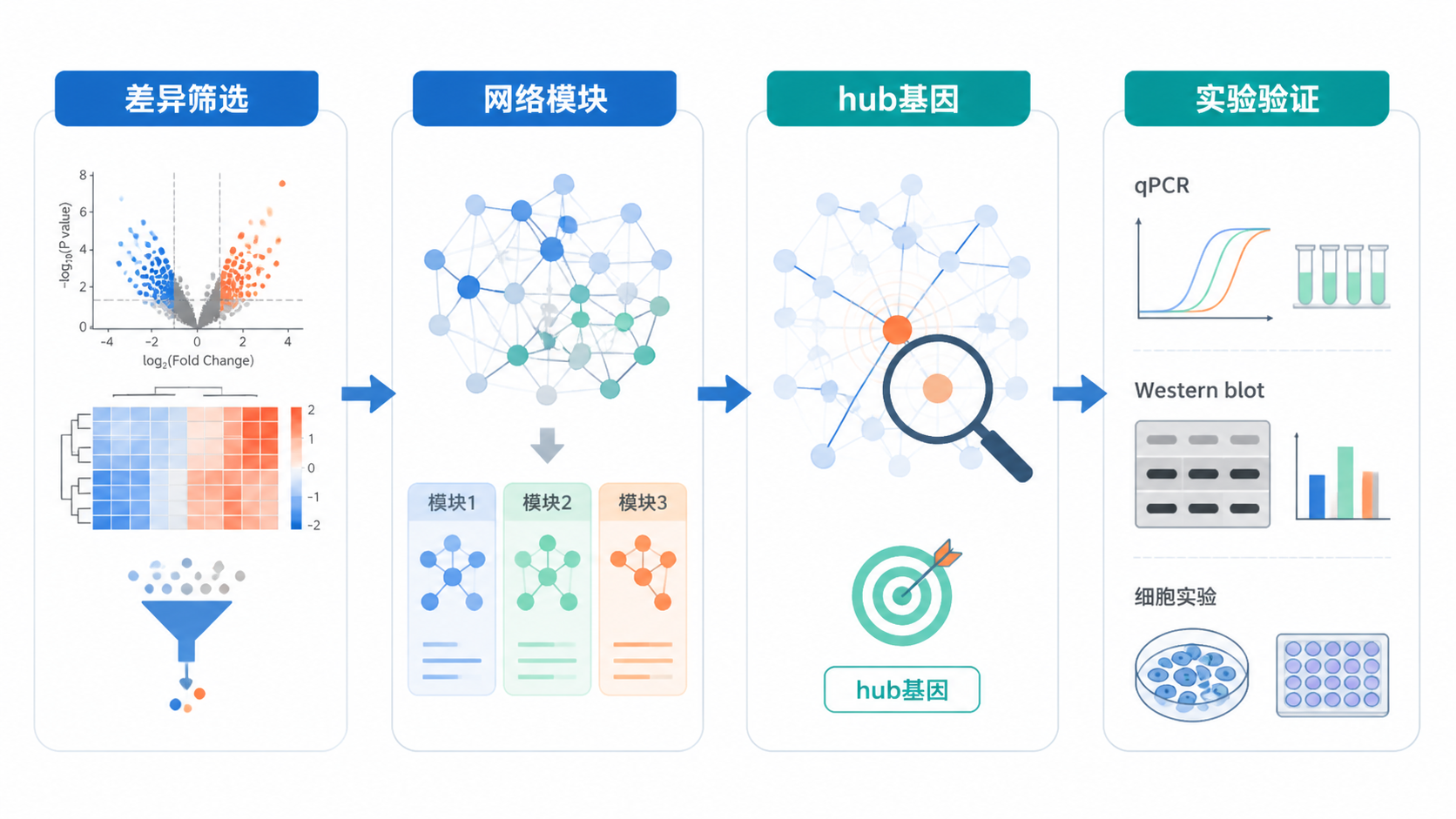
4. 生信网络图分析的实操步骤
4.1 从差异分析到网络构建
如果你是从头做项目,可以按这个顺序推进:
- 做差异分析。
- 得到候选基因列表。
- 做功能富集或互作筛选。
- 构建网络图。
- 找模块、hub 或关键轴。
- 做实验验证。
这条路径适合医学生、医生和科研人员。
因为它既能兼顾文章逻辑,也方便后续转化到实验设计。
网络图不是起点,而是承接筛选和机制的中间环节。
如果前面的筛选不稳,后面的图再漂亮也难以支撑结论。
4.2 不同图的阅读时间要分配
知识库给了一个很实用的判断:一篇文章里,大约一半的图会消耗80%的理解时间。
所以不要把时间平均分给所有图。
建议这样分配:
- 现象图,快速扫。
- 相关性图,确认方向。
- 机制图,重点精读。
- 补充图,最后回看。
对于组织标本、生存曲线、免疫组化、简单表型图,通常一眼就能识别。
真正要花时间的,是带有交互、回复、位点验证、双操作的图。
4.3 图上信息要快速标签化
阅读网络图时,建议你边看边做标签。
例如:
- 这是筛选图。
- 这是共表达模块图。
- 这是PPI互作图。
- 这是调控轴图。
- 这是验证图。
标签化可以显著降低记忆负担。
尤其是面对多张图、多组分、多层机制时,标签比纯记忆更可靠。
5. 生信网络图分析里最容易踩的坑
5.1 把相关性当因果
这是最常见的问题。
网络图里的连线,很多时候只是相关、共现或互作预测。
它不等于因果。
所以要看文章有没有:
- 干预实验。
- 回复实验。
- 位点验证。
- 动物实验。
- 临床样本验证。
没有验证的网络图,最多说明“可能有关”。
5.2 只看图,不看分组
很多读者会看图形,却忽略分组逻辑。
实际上,分组才是论证核心。
你要看清楚谁是对照,谁是操作组,谁是回复组。
如果是双操作实验,要确认第二个操作是在验证什么。
如果是动物实验,通常是对细胞层机制的补充论证,不必每次都从零推断。
5.3 忽略数据层级
网络图来自不同层级的数据。
有的是细胞。
有的是动物。
有的是组织。
有的是生信数据库。
层级不同,结论强度不同。
组织相关性图适合做相关论证,不适合直接替代机制证明。
细胞和动物实验才更适合支撑因果推断。
6. WGCNA式网络图,为什么特别适合做文章
6.1 它能把“很多基因”变成“几个模块”
WGCNA的价值,在于把散乱的表达信息压缩成模块。
模块之间再去和表型相关联。
这样,文章主线会更清晰。
常见输出包括:
- 模块树状图。
- 模块-性状热图。
- 网络拓扑图。
- hub 基因筛选结果。
模块化之后,故事线会比单基因叙事更完整。
6.2 它适合连接生信和实验
对于临床或基础科研文章,WGCNA常常能起到桥梁作用。
前面用数据筛主变量。
中间用模块锁定机制。
后面再用实验验证。
这也是为什么很多文章会把网络图放在核心位置。
它不仅是分析图。
也是论证图。
7. 结尾怎么把网络图变成可用结论
7.1 先得出一句话结论
一张好网络图,最终要落成一句话。
例如:
- 某模块与某表型显著相关。
- 某节点可能是关键hub。
- 某调控轴可能参与疾病进展。
如果你无法用一句话概括这张图,就说明你还没真正读懂它。
7.2 再决定是否继续精读
如果网络图与自己的研究方向高度相关,就进入精读。
如果只是泛读,可以跳过部分枝节,先抓主线。
这正是文献速读的核心方法。
对医学生、医生、科研人员来说,时间有限。
所以先掌握“看懂逻辑”的方法,比死记每种图更重要。
总结Conclusion
生信网络图分析怎么做,核心不是记住所有软件按钮,而是先判断图的类型,再理清变量、关系和验证链条。先筛选,再连线,再找模块,最后回到表型和实验。 这样读图更快,写文章也更稳。
如果你想把网络图分析真正落到项目里,建议从规范的流程开始:差异筛选、网络构建、模块识别、hub定位、验证闭环。解螺旋品牌可以帮助你把这套思路做成可复用的分析路径,减少试错,提升出图和写作效率。
- 引言Introduction
- 1. 先分清网络图的类型
- 2. 生信网络图分析的核心逻辑
- 3. 生信网络图分析常见模块怎么读
- 4. 生信网络图分析的实操步骤
- 5. 生信网络图分析里最容易踩的坑
- 6. WGCNA式网络图,为什么特别适合做文章
- 7. 结尾怎么把网络图变成可用结论
- 总结Conclusion