






引言Introduction
PPI 网络是生信分析中最常用的功能模块之一。对医学生、医生和科研人员来说,难点不在“画图”,而在于如何从庞杂互作中快速找到真正有意义的核心靶点。如果你想用PPI 网络筛出10个高价值候选基因,就必须先掌握数据准备、网络构建和Hub筛选的完整流程。
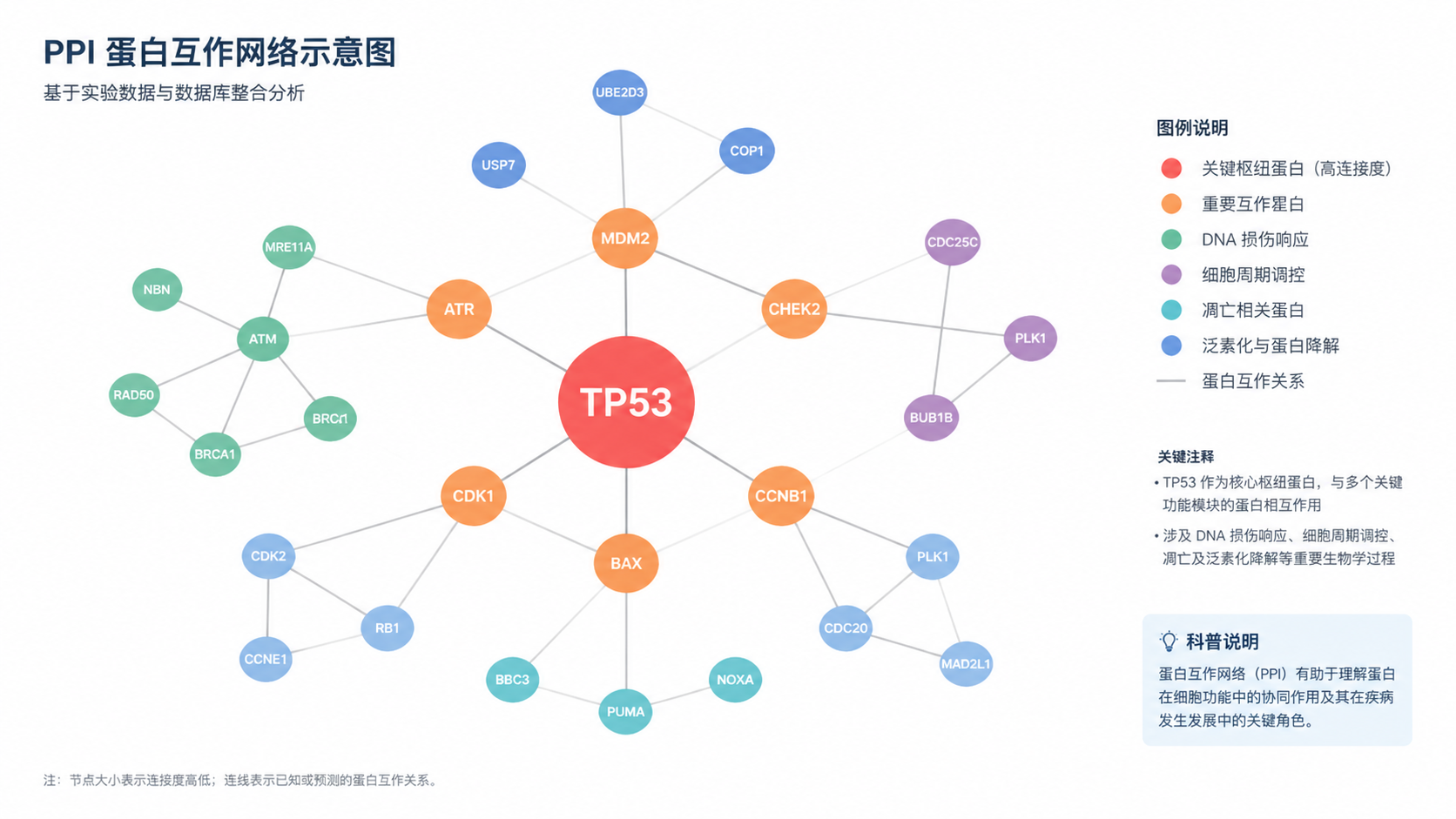
1.PPI 网络是什么,为什么要先做它
1.1从“差异基因”到“功能核心”
PPI 网络的本质,是把基因或蛋白之间的相互作用关系可视化。一个网络由节点和连线构成。节点代表基因或蛋白,连线代表相互作用。相比单纯看差异表达列表,PPI 网络更适合回答“哪些分子处在调控中心”。
在疾病机制研究中,PPI 网络常用于缩小候选范围。 先得到差异基因,再把它们导入互作数据库,最后找出连接度高、处于网络中心的基因,这一步往往决定后续验证效率。
1.2为什么能挖出10个核心靶点
从课程知识库看,Hub 基因指的是在基因表达网络中连接度较高的基因。它们更可能位于通路交汇点,或在疾病过程中承担关键调控作用。
因此,PPI 网络不是最终结论,而是筛选核心靶点的入口。
实际操作中,通常先构建完整网络,再结合算法挑出前10个候选。这样做的好处有三点。
- 减少噪音。
- 提升结果可解释性。
- 便于后续做验证实验或文献回溯。
2.构建PPI 网络前,数据怎么准备
2.1至少要准备两列网络数据
根据知识库,导入网络图数据时,表格至少包含两列。第一列是源节点,第二列是靶节点。处于同一行,就表示存在相互关系。
常见做法是先用 Excel 整理数据。第一列写 node1,第二列写 node2。node1 是基因列表,node2 是通过 STRING 等数据库预测到的互作蛋白。
如果输入数据不规范,后续网络图会直接失真。 这一点在实际项目中很常见。比如基因命名不统一,或者把属性表和网络表混在一起,都会影响 Cytoscape 的导入效果。
2.2还需要一张属性表
构建网络图通常要导入两个文件。一个是网络图数据,一个是数据属性文件。属性文件可包含基因上调、下调、表达量、Combined Score 等信息。
在 Cytoscape 中,网络数据用 “Network from File” 导入,属性表格用 “Table from File” 导入。
这一步的意义在于,后面不仅能画图,还能给节点着色、定大小、定形状。 对论文作图和结果呈现都很关键。
2.3导入时要注意什么
按照教程,导入网络数据时,需要在菜单栏选择 File,再选 Import Network from File。然后在弹窗中指定 node1 和 node2 的角色。
node1 作为源节点,node2 作为靶节点。确认后即可生成初步网络图。
如果再导入属性表,就可以针对当前网络设置节点属性。一般只选择当前网络,避免误导入到其他图中。这一步会直接影响后续的样式美化和生物学标注。
3.如何在Cytoscape里构建PPI 网络
3.1先导入互作文件,再调布局
Cytoscape 是目前最常用的网络可视化软件之一。构建 PPI 网络的标准流程并不复杂。
先导入网络文件,再导入属性文件,最后根据数据特征调整布局。
常用操作包括:
- 在 File 中导入网络文件。
- 指定源节点和靶节点。
- 生成初步网络。
- 再导入属性表。
- 按需要设置节点样式。
- 在 Layout 中选择合适布局。
布局不是装饰,而是帮助你看清网络结构。 网络过于密集时,合理布局能明显提高可读性。
3.2样式设置决定你能不能“看懂”图
导入完成后,建议根据属性表调整节点颜色、大小和边的显示方式。比如上调和下调基因可用不同颜色区分,表达量高低可用节点大小表示。
这样处理后,PPI 网络的生物学信息会更直观。
对于准备投稿的文章,这一步尤其重要。因为一张清晰的网络图,往往比一页文字更容易向审稿人说明问题。图要能服务结论,而不是只追求好看。
4.如何从PPI 网络筛选10个核心靶点
4.1先认识Hub基因
Hub 基因是网络中连接度高的基因。它们通常连接多个节点,可能在病理过程中处于核心位置。
在 PPI 网络中筛 Hub,是“从全局到局部”的关键步骤。
根据知识库,常见的筛选方法有两种。第一种是 MCODE 插件。第二种是 CytoHubba 插件。两者都可用于从 PPI 网络中提取关键模块或高连接度节点。
4.2方法一,MCODE筛关键模块
MCODE 适合找局部高密度模块。操作思路是先打开插件,按默认参数或自定义参数进行分析,再点击 Analyze Current Network。
分析结果会在右侧面板展示多个模块,按 score 值从高到低排序。
然后选中第一个模块,点击 Create Cluster Network。此时主视图会显示关键网络。这个模块里的基因,往往就是你后续要重点关注的候选靶点来源。
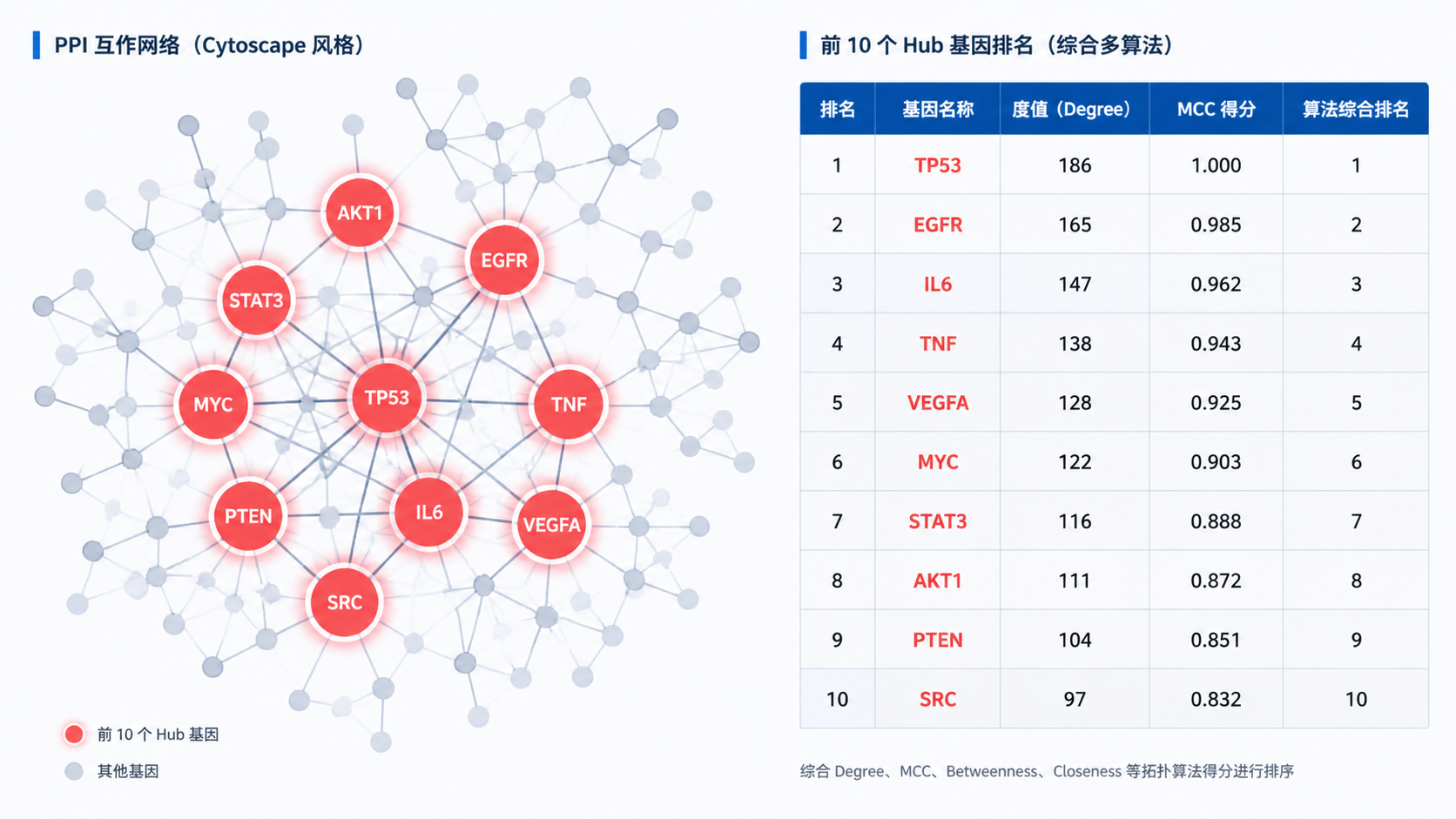
4.3方法二,CytoHubba筛核心节点
CytoHubba 更适合做 Hub 基因排名。它提供了 12 种算法。教程中建议先用所有算法计算,再选择其中一种算法展示结果。
一般可设置 Top 10,输出前10个 Hub 基因。
如果你的目标是“挖掘10个核心靶点”,CytoHubba 是最直接的工具。 它能把复杂网络压缩成清晰的排名结果,便于后续验证和写作。
4.410个核心靶点怎么定义更合理
严格来说,10个核心靶点不是随意挑出来的,而是基于算法排序和模块结果综合确定的。常见逻辑是:
- 先用 STRING 和 Cytoscape 构建 PPI 网络。
- 再用 CytoHubba 计算节点重要性。
- 结合 MCODE 找到高密度模块。
- 取交集或排名靠前的基因作为核心靶点。
这种方式比单独看差异倍数更稳健。因为它把“表达变化”和“网络中心性”结合了起来。
5.结果怎么呈现,才能更像一篇合格论文
5.1结果部分要和方法一一对应
生信文章写作的基本原则,是结果与方法对应。先说明差异基因筛选,再写功能富集分析,然后写 PPI 网络构建,最后写核心靶点筛选。
这一顺序更符合审稿人的阅读习惯。
如果你在文章中使用 PPI 网络筛选了 10 个核心靶点,结果里最好明确交代:
- 网络如何导入。
- 使用了哪些插件。
- 采用了哪种算法。
- 最终得到多少核心基因。
写作时不要只说“筛选出10个核心靶点”,而要说明“怎么筛出来的”。
5.2图例和图注要简洁准确
图例不是重复正文,而是帮助读者快速理解图中信息。对于 PPI 网络图,建议标明节点含义、边的含义、颜色代表什么、大小代表什么,以及核心模块如何定义。
如果用了 MCODE 或 CytoHubba,也要在图注里写清楚。
这类信息看似细节,实际很影响论文质量。很多生信文章的可信度,就是从图注完整度体现出来的。
6.写PPI 网络相关文章时,常见误区有哪些
6.1只会作图,不会解释
很多人能把 PPI 网络画出来,但解释不到位。比如只说“中心节点很重要”,却不说明依据是什么。
实际上,中心性高并不等于临床意义强。它只是一个候选信号,需要结合富集分析、文献证据和实验验证。
6.2把算法结果当成最终结论
CytoHubba 和 MCODE 给出的只是计算结果。它们能帮助你缩小范围,但不能替代生物学验证。
如果后续没有 qPCR、Western blot、ELISA 或临床样本验证,文章的说服力会明显下降。
6.3忽视属性表
属性表能体现上调、下调和表达量信息。如果只导入网络,不导入属性表,图会少很多层次。
尤其是在疾病机制研究里,属性信息常常直接关系到结果展示和结论表达。
总结Conclusion
PPI 网络的价值,不只是“画出一张互作图”。它真正的作用,是帮助研究者从大量候选基因中筛出最可能的核心靶点。通过规范准备网络数据、在 Cytoscape 中导入文件、结合 MCODE 和 CytoHubba 分析,你可以把复杂网络压缩为清晰的10个核心靶点列表。这一步对后续机制研究、实验验证和论文发表都非常关键。
如果你正在做疾病机制、生信挖掘或靶点筛选,建议用更系统的工具链提高效率。解螺旋品牌提供的生信实操课程和分析思路,可以帮助你把 PPI 网络从“会画”提升到“会用”,让核心靶点筛选更规范、更可复现。
- 引言Introduction
- 1.PPI 网络是什么,为什么要先做它
- 2.构建PPI 网络前,数据怎么准备
- 3.如何在Cytoscape里构建PPI 网络
- 4.如何从PPI 网络筛选10个核心靶点
- 5.结果怎么呈现,才能更像一篇合格论文
- 6.写PPI 网络相关文章时,常见误区有哪些
- 总结Conclusion



