引言Introduction
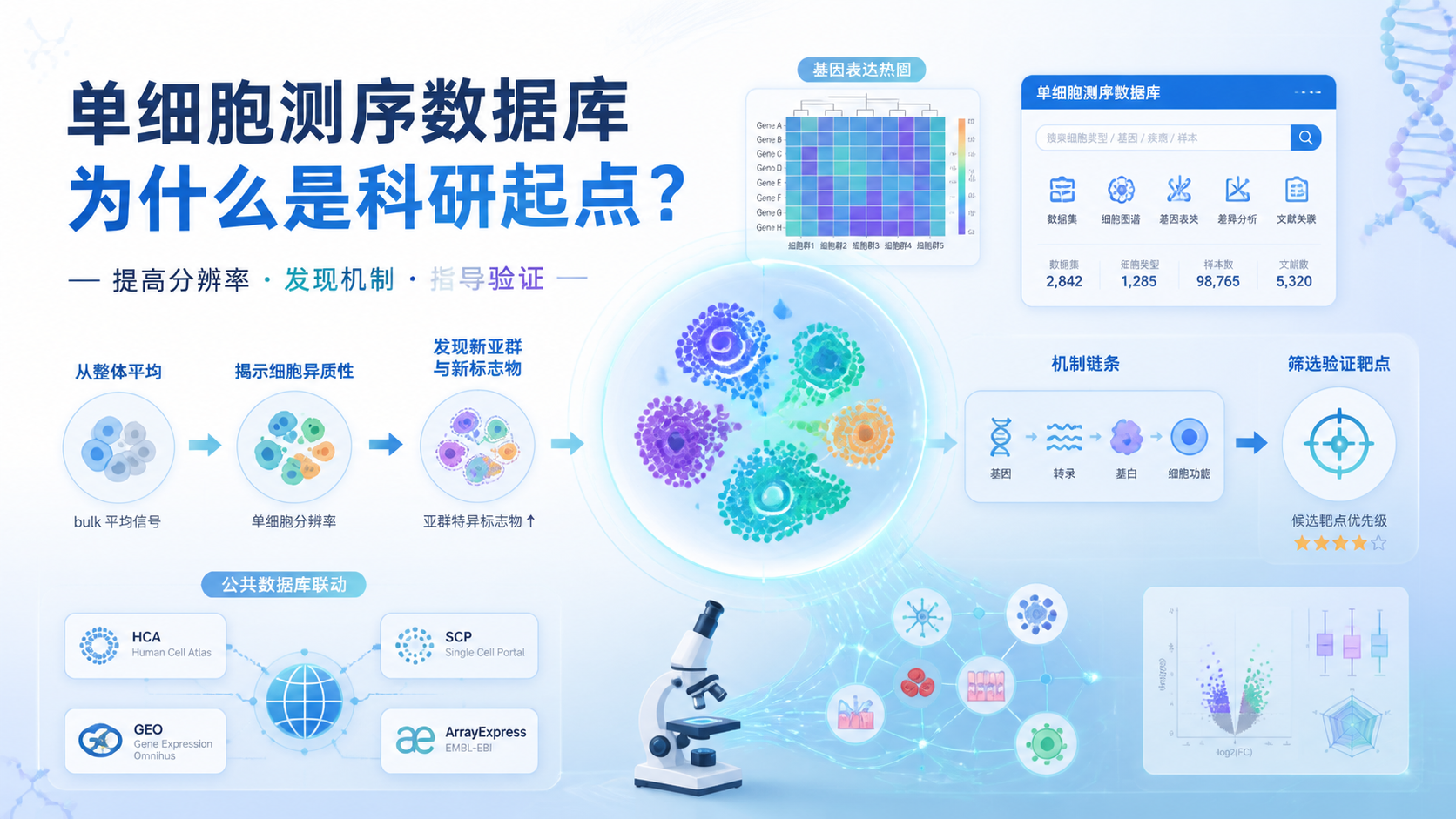
scRNA-seq数据库 已经成为单细胞研究的高频入口。面对海量样本和复杂细胞类型,很多医学生、医生和科研人员最常见的痛点是,找不到合适数据,也不清楚该怎么快速验证基因表达和细胞特异性。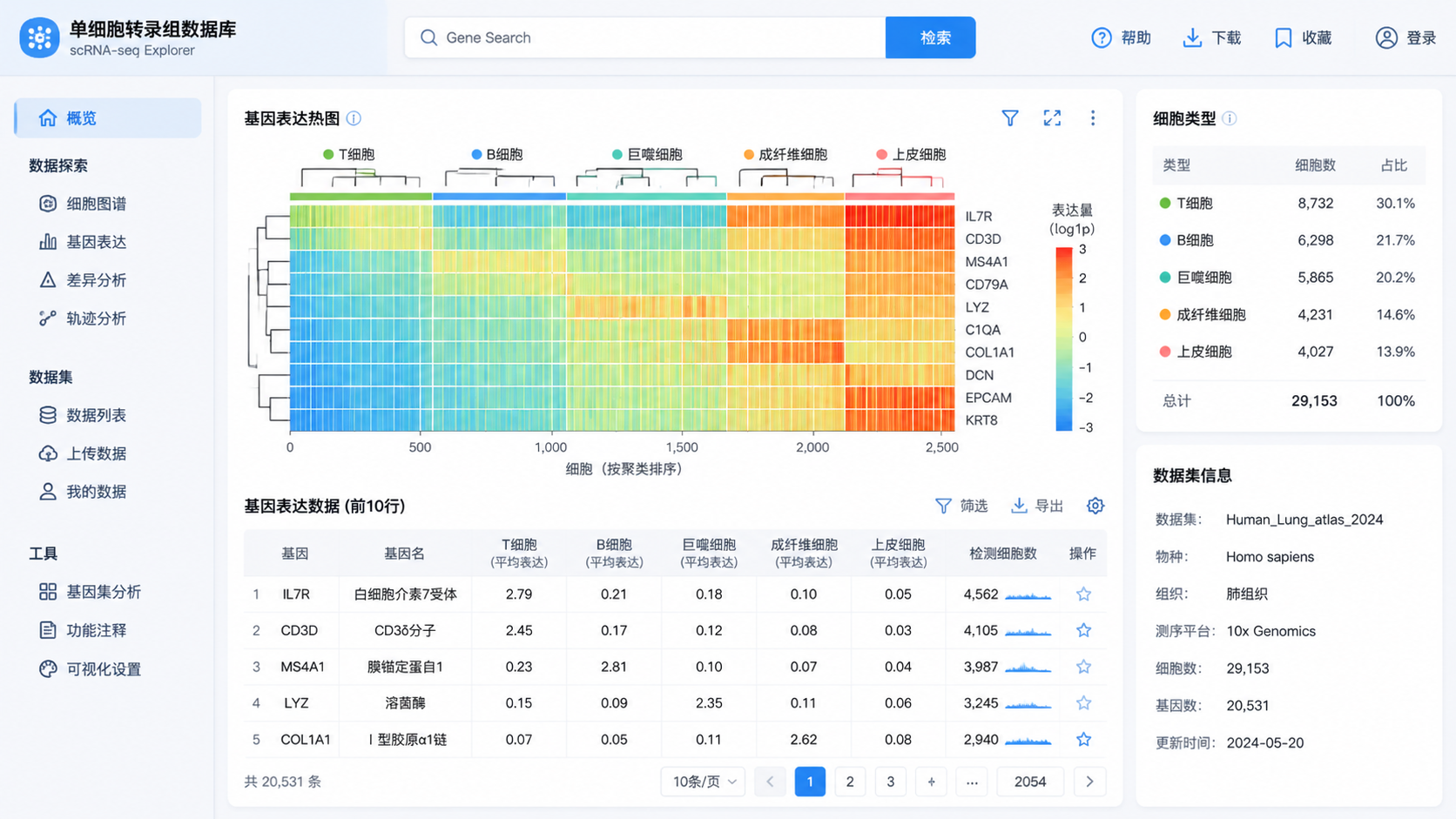
1. 什么是scRNA-seq数据库,为什么要先选对
1.1 scRNA-seq数据库的核心作用
scRNA-seq数据库的价值,不只是“存数据”,而是帮助研究者快速完成数据检索、表达验证和初步功能注释。
以知识库中的scRNASeqDB为例,它收录了38个GO数据集、13,000多个样本和200个细胞分组,说明这类资源已经能覆盖不少常见研究场景。
对临床和基础研究用户来说,数据库的第一任务有三个。
- 查基因在不同样本和细胞类型中的表达。
- 查细胞类型对应的marker和相关文献。
- 快速做公开数据挖掘,减少重复试错。
1.2 选库时最容易忽视的点
很多人只看“收录多少数据集”,但真正影响效率的,是检索方式和结果展示能力。
一个好用的scRNA-seq数据库,必须支持基因检索、细胞检索、结果可视化和外部链接跳转。
如果数据库只能给出静态列表,不能看热图、TPM分布、相关基因和文献链接,后续分析就会明显变慢。对于需要赶进度的课题,这一点尤其重要。
2. 2026年值得关注的5类scRNA-seq数据库
2.1 按“基因检索能力”对比
知识库里的scRNASeqDB支持两种输入格式,分别是基因symbol和Ensembl基因ID。
这对跨平台比对非常实用。 因为很多项目组的数据注释格式并不一致。
检索后,系统会展示该基因在所有样本中的表达情况,并按高到低排序。用户还可以查看基因所在的细胞分组,以及跳转到Ensembl获取更完整的基因信息。
这种设计适合先验证候选基因,再决定是否进入进一步实验。
2.2 按“细胞类型检索能力”对比
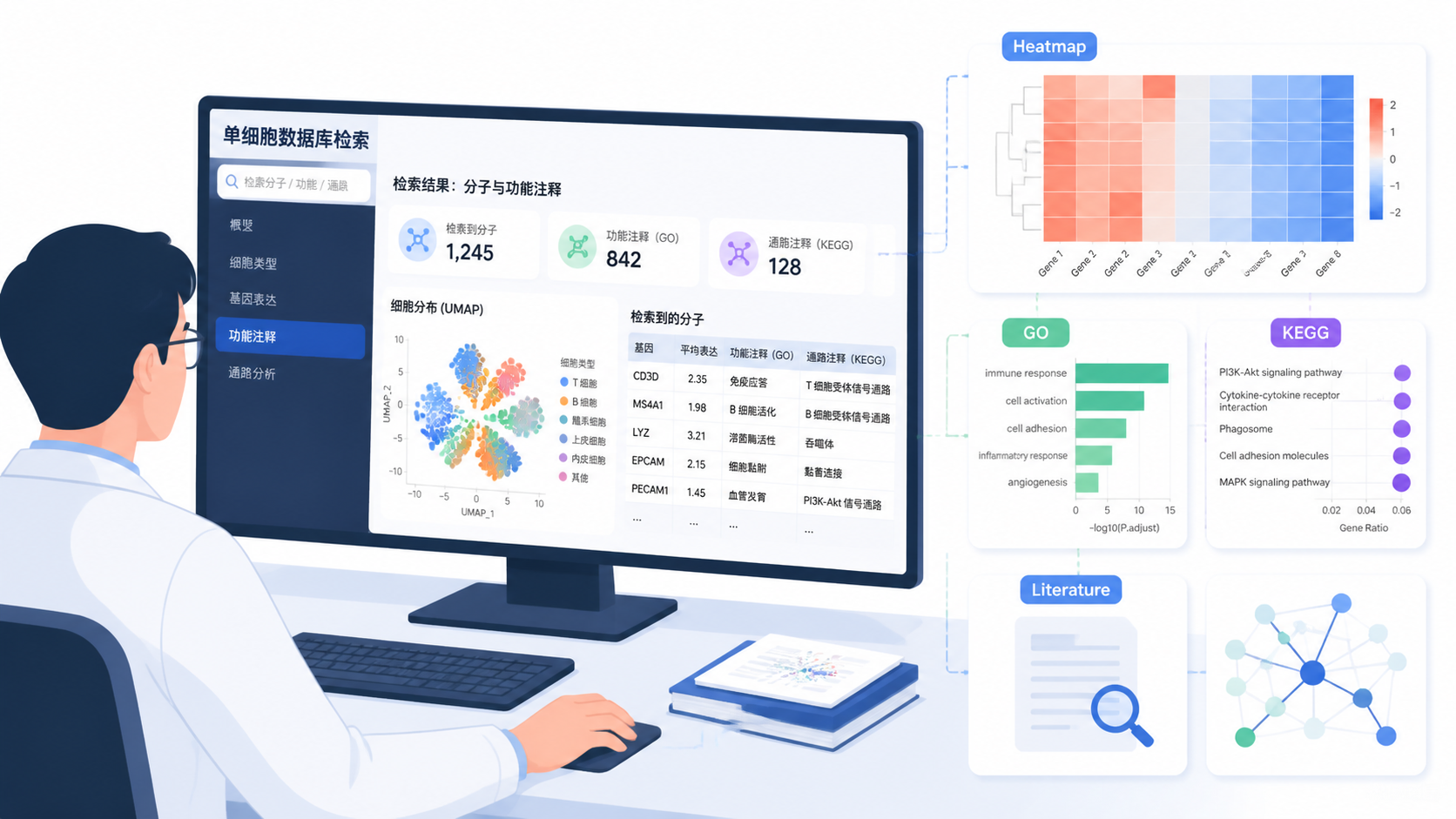
除了基因,细胞检索同样重要。以NK细胞为例,scRNASeqDB可直接检索相关细胞类型,输出基因集编号、NCBI数据集链接、PubMed文献链接、细胞说明和样本信息。
这类功能特别适合快速建立细胞图谱认知。
对初学者来说,细胞检索可以帮助他们从“我有一个细胞类型”直接走向“这个细胞有哪些marker、来自哪些数据集、有哪些公开证据”。
2.3 按“可视化深度”对比
数据库的可视化能力,直接决定读图效率。
在知识库示例中,GSE36552数据集的表达结果会以热图展示,并给出五个样本的表达情况。
此外,系统还会展示不同细胞类型中的最小值、中位数和最大值TPM表达量。
这比单纯看一个均值更有参考价值。 因为单细胞数据的离散度往往很高,中位数和区间信息更能反映真实分布。
2.4 按“功能注释能力”对比
一个合格的scRNA-seq数据库,不应只停留在表达图。
scRNASeqDB还会展示与目标基因相关的前100个基因的KEGG和GO结果。如果有显著结果,系统会直接给出运行结果。
这一步的意义很明确。
- 帮助研究者判断该基因是否参与某条通路。
- 帮助缩小后续机制验证范围。
- 帮助写作时快速组织结果段落。
2.5 按“文献和外链整合度”对比
数据库是否能直接链接到NCBI、PubMed、Ensembl,决定了它是不是一个真正的工作入口。
知识库里的scRNASeqDB支持从基因、细胞到文献的多跳转链路,这让用户可以在一个界面内完成初筛、验证和追溯。
对于科研人员而言,这种整合能显著减少切换网页的时间成本。 对临床研究者而言,也更方便回查原始研究背景,提升结果可信度。
3. scRNA-seq数据库怎么用,才能提高效率
3.1 先从问题出发,而不是先搜数据
使用scRNA-seq数据库时,最推荐的顺序不是“随便逛”,而是先明确问题。
例如,先问自己以下三个问题。
- 我要验证的是某个基因。
- 我要比较的是某类细胞。
- 我要找的是表达证据,还是功能证据。
这样检索效率会高很多。
如果目标是验证一个候选基因,优先用基因检索。
如果目标是了解某类细胞的marker,优先用细胞检索。
3.2 看表达结果时重点关注什么
单细胞数据库返回结果后,不要只看“有没有表达”。
更重要的是看以下四项。
- 表达排序。
- 细胞分组。
- TPM的中位数和极值。
- 是否存在相关GO和KEGG富集结果。
这些信息组合起来,才能判断某个基因是普遍表达,还是具有细胞偏好性。
对于论文图表设计来说,这也是后续验证优先级的依据。
3.3 适合哪些研究场景
从知识库信息看,scRNASeqDB尤其适合以下场景。
- 候选基因的表达验证。
- 细胞marker的公开数据支持。
- 公开数据挖掘和预实验假设生成。
- 结果讨论阶段的文献补充。
如果你的课题正在做单细胞转录组分析,这类数据库可以作为起点,而不是终点。
它的价值是帮你更快筛选方向,降低无效实验成本。
4. 2026年选择scRNA-seq数据库的5项标准
4.1 数据规模
优先选择样本量较大、细胞分组较完整的资源。
知识库中的scRNASeqDB包含13,000多个样本和200个细胞分组,已经具备较强的检索价值。
样本越丰富,表达参考越稳健。
4.2 输入灵活性
至少要支持gene symbol和Ensembl ID两种格式。
这能减少不同项目、不同注释版本之间的转换成本。
4.3 结果可读性
结果最好能同时给出列表、热图和统计量。
只有这样,研究者才能在短时间内完成初筛。
4.4 外部数据库联动
能否跳转到Ensembl、NCBI和PubMed,非常关键。
这决定了你是否能快速完成“数据验证到文献追溯”的闭环。
4.5 更新与可维护性
数据库更新时间和维护状态也很重要。
知识库信息显示,scRNASeqDB最新更新于2017年。
这意味着它更适合作为经典公开资源和教学分析入口。
如果是追求最新大规模整合资源,建议同时结合其他更新更频繁的平台使用。
5. 对医学生、医生和科研人员的实际建议
5.1 医学生怎么用
医学生可以用scRNA-seq数据库建立细胞和基因的基础认知。
重点是学会从基因到细胞,再从细胞回到通路。
这样比死记细胞marker更高效。
5.2 医生怎么用
医生更适合把数据库用于疾病相关基因的预筛选。
例如某个标志基因在特定细胞中的表达是否明显。
这能帮助形成更清晰的病理机制假设。
5.3 科研人员怎么用
科研人员要把scRNA-seq数据库当成“验证层”。
先用数据库确认表达,再进入实验设计。
这一步往往能显著减少盲目做实验的概率。
如果你需要把公开单细胞数据快速变成可用证据,建议使用像解螺旋这样的专业生信内容与分析支持平台。它更适合帮助你把数据库检索、结果解读和论文写作串成一个完整流程,提升课题推进效率。
总结Conclusion
scRNA-seq数据库的选择,核心不是“谁最花哨”,而是“谁最能帮你更快得到可信结果”。从基因检索、细胞检索、表达可视化,到KEGG和GO注释、文献跳转,知识库中的scRNASeqDB展示了一个成熟单细胞数据库应具备的关键能力。对于医学生、医生和科研人员来说,真正高效的用法,是把数据库作为假设验证和公开数据挖掘入口。
如果你正在做单细胞课题,想更快找到合适的scRNA-seq数据库、提高检索效率并减少分析弯路,可以进一步了解解螺旋的专业支持服务。
- 引言Introduction
- 1. 什么是scRNA-seq数据库,为什么要先选对
- 2. 2026年值得关注的5类scRNA-seq数据库
- 3. scRNA-seq数据库怎么用,才能提高效率
- 4. 2026年选择scRNA-seq数据库的5项标准
- 5. 对医学生、医生和科研人员的实际建议
- 总结Conclusion