引言Introduction
GSEA数据库 是做通路分析、转录调控分析和细胞类型注释时最常用的资源之一。但很多人第一次检索时,常会卡在“集合太多、命名太乱、版本不同、结果难解释”这四个问题上。本文用4个关键技巧,帮助医学生、医生和科研人员更高效地查找与使用GSEA数据库。
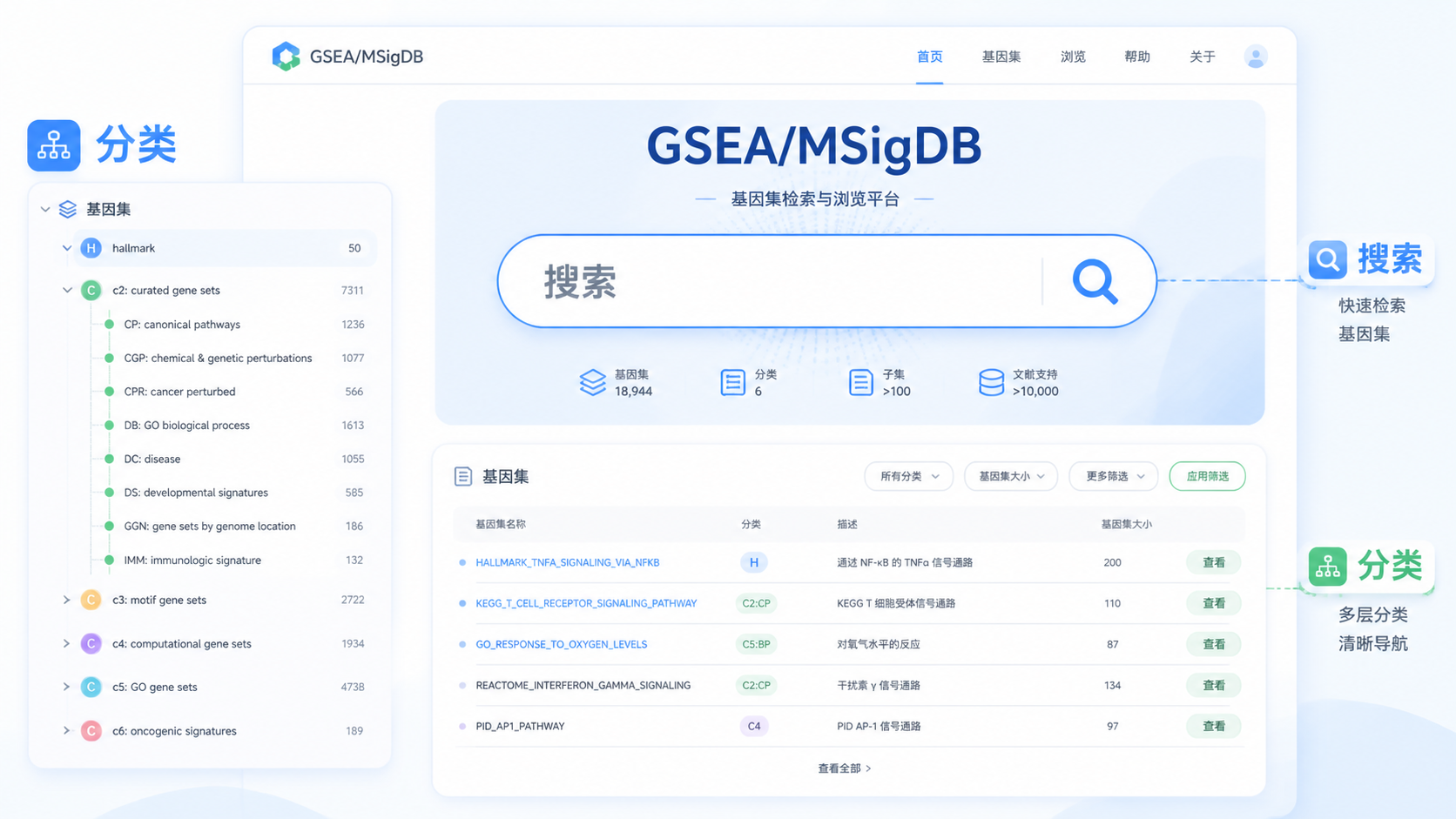
1. 先搞清GSEA数据库的核心结构
1.1 先从集合类型入手,而不是直接搜关键词
高效检索GSEA数据库的第一步,是先理解它不是单一数据库,而是按集合分类的基因集资源。 常见的MSigDB集合中,和机制解释最相关的是M3、M5、M8等。
其中,M3包含调控相关基因集。它分为microRNA靶点和转录因子靶点两类。前者如miRDB microRNA targets,来源于miRDB v6.0,且仅保留MirTarget评分大于80的高置信度预测。后者如GTRD transcription factor targets,基于启动子区域的潜在转录因子结合位点。
1.2 不同集合决定了你能回答什么问题
如果你关心“哪个miRNA可能参与表型变化”,优先看M3中的miRNA靶基因集。
如果你关心“哪个转录因子可能驱动表达变化”,优先看M3中的TFT集合。
如果你关心“这个差异基因属于什么生物过程”,可优先查M5中的GO基因集。
如果你关心“细胞来源或组织类型”,则M8这类细胞类型签名基因集更合适。
换句话说,先选对集合,再谈检索效率。 这是使用GSEA数据库时最容易被忽略的一步。
2. 用“问题导向”筛选,而不是盲目浏览
2.1 先定义你的研究问题
检索GSEA数据库前,先把问题写成一句话。比如:
- 某肿瘤是否存在特定转录因子调控增强。
- 某药物处理后是否激活了某条生物过程。
- 某类样本是否更接近特定细胞类型特征。
问题越具体,检索路径越短。 这比直接在数据库里翻页找结果更有效。
2.2 再按集合前缀和来源库缩小范围
MSigDB中的基因集通常有明确前缀。比如:
- GOBP,生物过程。
- GOMF,分子功能。
- GOCC,细胞组分。
- MP,肿瘤相关表型术语。
对于调控类数据,还可以直接锁定来源库。比如miRDB和GTRD。前者适合做microRNA靶点层面的解释,后者适合做转录因子层面的解释。
检索时不要把所有集合放在一起比较。 这会显著增加噪音,也会降低结果解释的准确性。
3. 关注版本、置信度和注释来源
3.1 版本不同,结果可能不同
GSEA数据库中的基因集会更新。以miRDB为例,数据来源于miRDB v6.0,miRNA信息来自miRBase v22。版本变化会影响靶基因定义,也会影响后续富集结果。
在写论文或做复现时,必须记录数据库版本。 这是GSEA结果可重复性的基础。
3.2 置信度阈值决定结果质量
在miRDB microRNA targets中,MirTarget评分大于80才会进入高置信度集合。这个细节很重要。因为它意味着你检索到的不是“所有可能靶点”,而是更偏向可信预测的靶点集合。
同样地,GTRD来源的转录因子靶点,是基于统一处理流程提取的候选调控靶点,而不是直接实验验证的全部靶点。
对医学生和科研人员来说,理解“预测”和“证据等级”的差异,比记住集合名字更重要。
3.3 读懂注释来源,才能避免误解
GO注释由权威机构维护,且每个注释都与参考文献和证据代码相关联。也就是说,GSEA数据库里的一个基因集,背后并不是简单的名单,而是有来源、有注释体系、有证据链的。
这也是为什么在结果解读时,不能只看富集分数,还要回到集合定义本身。
4. 结合GSEA算法思路,提高检索准确率
4.1 先理解GSEA在找什么
GSEA不是单纯找“显著差异基因”。它是看一个预定义基因集,是否在排序后的基因列表顶部或底部显著聚集。
这意味着,检索GSEA数据库时,核心不是“基因有没有显著”,而是“这一组基因是否成体系地偏向某个方向”。
这点对临床样本尤其重要。因为很多真实生物学变化会分散在多个基因上,单基因未必显著,但通路层面可能已经明显改变。
4.2 先准备好排序列表,再选合适基因集
GSEA分析通常基于排序后的基因列表。排序可以依据差异倍数、相关性等指标。实际操作中,列表应按从高到低排列,涵盖正负变化。
如果输入排序本身不稳定,后续再怎么检索GSEA数据库,结果都不可靠。
所以,正确流程应当是:
- 先得到稳定的排序基因列表。
- 再根据研究问题选择集合类型。
- 再看ES、NES和FDR等指标。
- 最后回到数据库注释做解释。
4.3 重点看Leading-edge基因
GSEA的leading-edge subset,是对富集贡献最大的那部分基因。它比整个基因集更接近“真正驱动富集”的核心成员。
在检索GSEA数据库时,如果你已经锁定某条通路或某类调控因子,不妨进一步查看leading-edge基因。这样更容易把结果和具体实验验证连接起来。
这一步特别适合后续做qPCR、Western blot或机制验证。
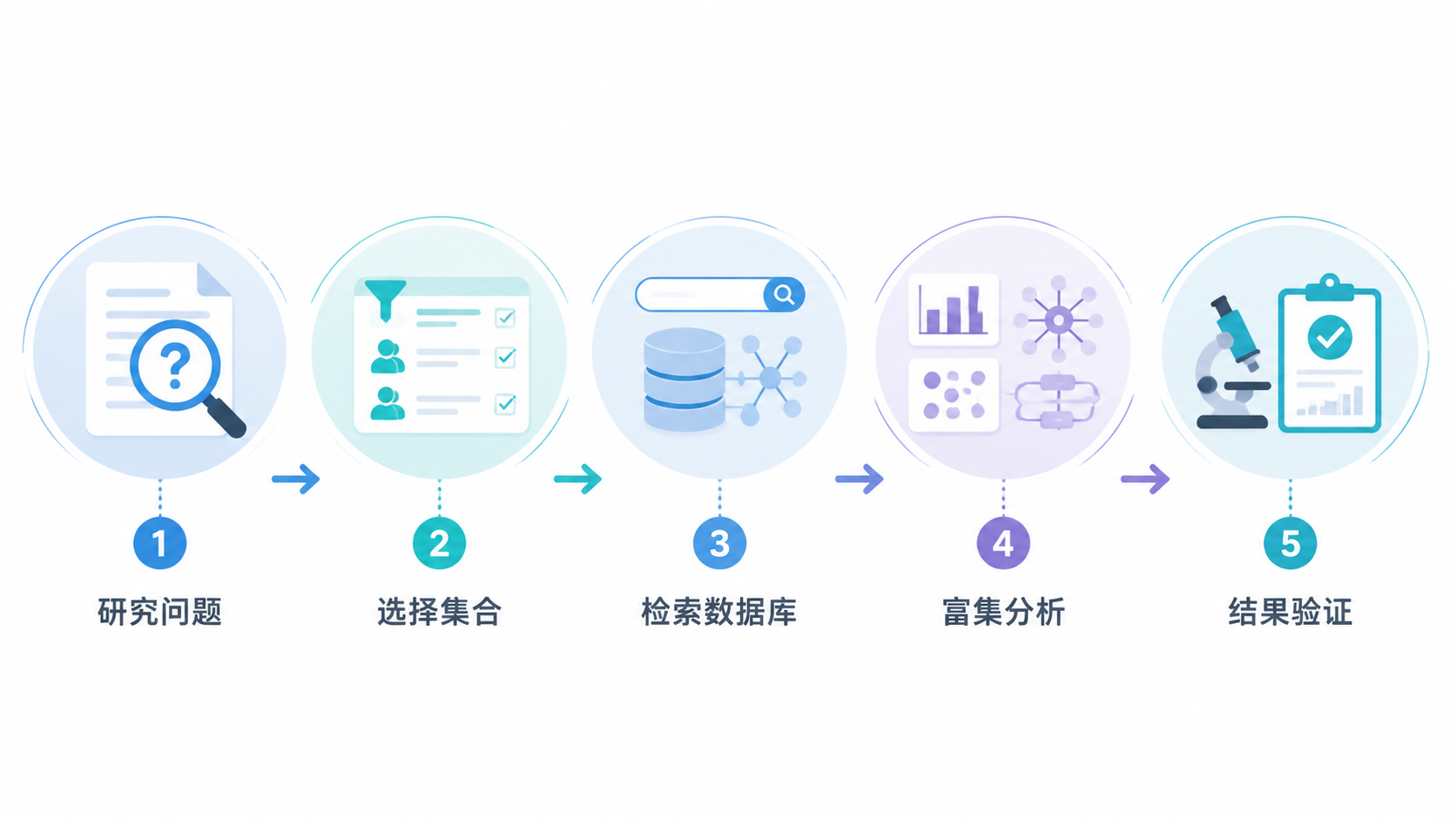
5. 实用检索策略:4步直接提高效率
5.1 第一步,先定研究层级
你要先判断自己是在找:
- 通路层面。
- 调控层面。
- 细胞类型层面。
- 表型层面。
不同层级,对应不同集合。不要把它们混在一起检索。
5.2 第二步,优先查高相关集合
如果是表达变化与转录调控相关,优先查M3。
如果是功能注释,优先查M5。
如果是细胞归属,优先查M8。
如果是肿瘤表型相关,优先查MPT。
5.3 第三步,记录关键元数据
每次检索GSEA数据库,至少记录以下信息:
- 数据库名称。
- 集合类型。
- 版本号。
- 置信度阈值。
- 注释来源。
- 排序指标。
这些信息决定结果能否复现。
5.4 第四步,结果回到生物学问题
GSEA数据库检索的终点不是“找到一个富集条目”,而是回答研究问题。
例如:
- 某miRNA是否可能调控该表型。
- 某转录因子是否可能是上游驱动因素。
- 某GO过程是否与疾病进展一致。
- 某细胞类型签名是否提示样本组成变化。
只有这样,检索才真正服务于论文、课题和临床转化。
总结Conclusion
高效检索gsea数据库 ,关键不在于“搜得多”,而在于“选得准、记得清、解释得对”。你需要先理解集合结构,再按问题筛选范围,接着关注版本和证据等级,最后结合GSEA算法思路回到生物学解释。
对于医学生、医生和科研人员来说,这套方法能显著减少无效浏览,提高分析效率,也能让结果更适合论文撰写和机制验证。 如果你希望进一步把GSEA检索、富集分析和结果解读串成标准流程,欢迎结合解螺旋的专业内容与工具方案,进一步提升课题推进效率。
- 引言Introduction
- 1. 先搞清GSEA数据库的核心结构
- 2. 用“问题导向”筛选,而不是盲目浏览
- 3. 关注版本、置信度和注释来源
- 4. 结合GSEA算法思路,提高检索准确率
- 5. 实用检索策略:4步直接提高效率
- 总结Conclusion