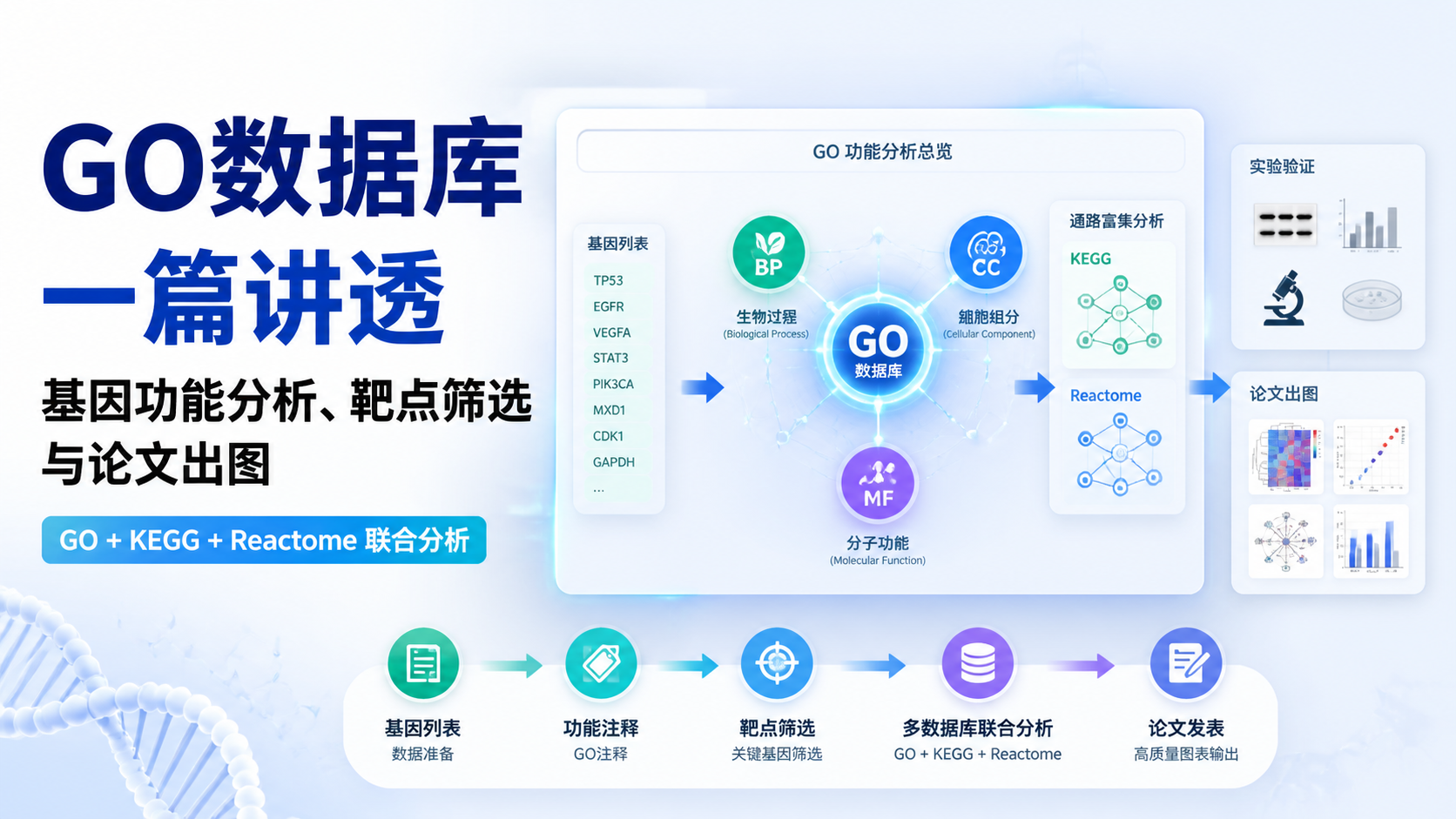
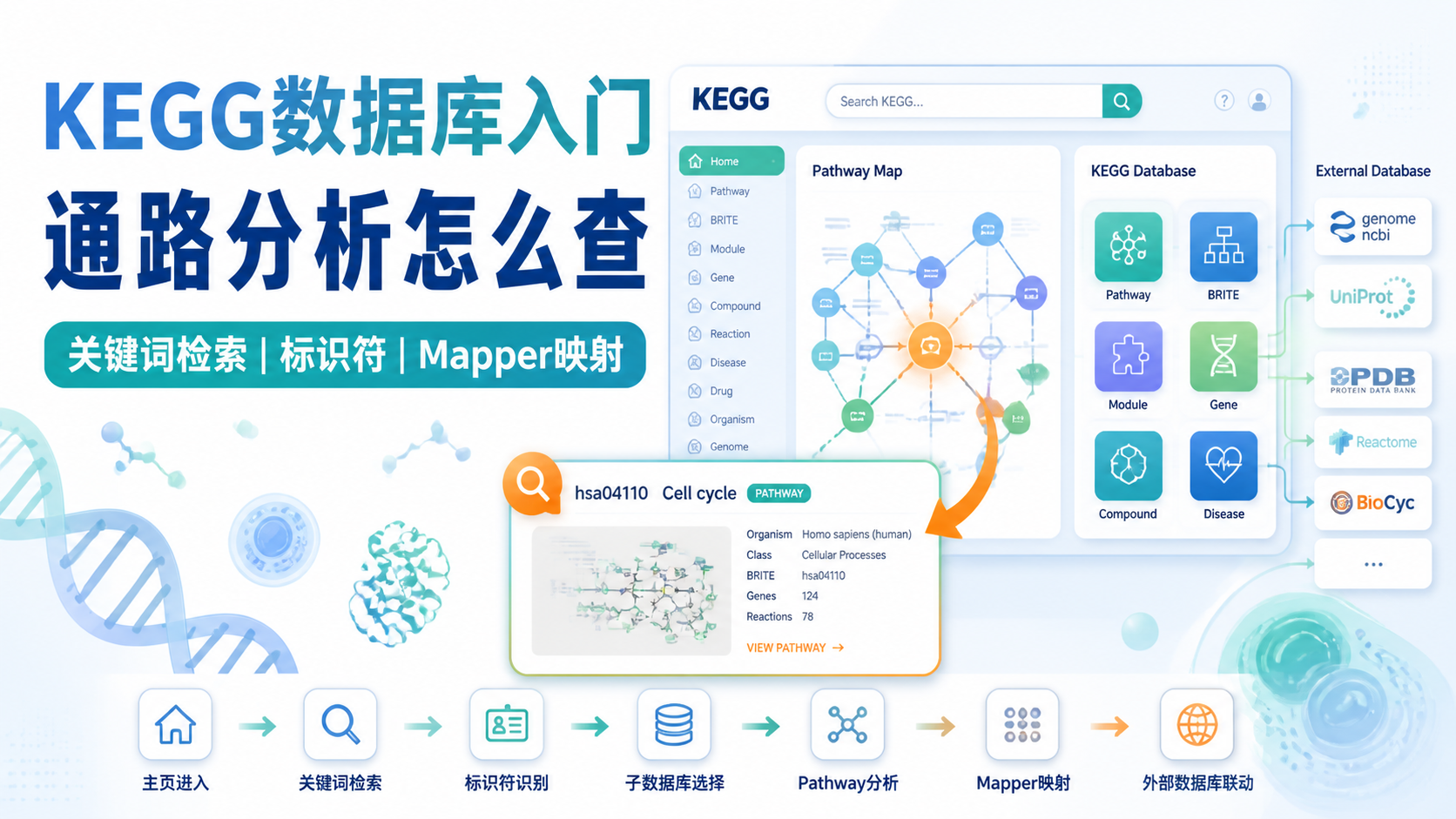
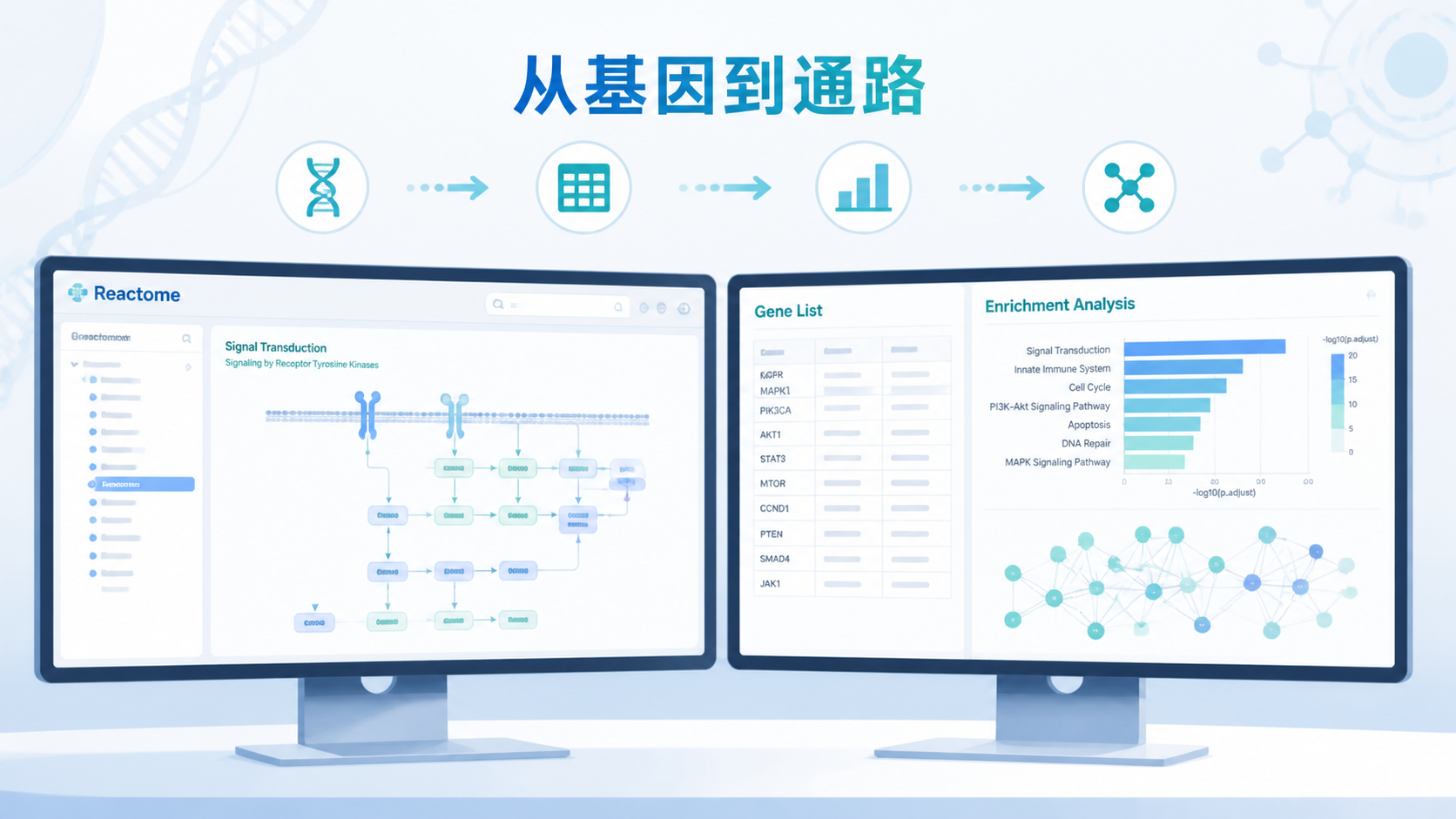
引言Introduction
做高通量研究时,最常见的痛点不是没有数据,而是不知道这些基因到底落在哪条通路里。 对医学生、医生和科研人员来说,** reactome数据库**是一个能把基因、蛋白和通路快速串起来的工具。它开源、免费,且数据经过手动筛选和同行评审,适合用来解释差异基因、做通路富集和构建机制假设。
1. 先认识Reactome数据库的定位
1.1 它不是普通的“基因列表库”
reactome数据库 的核心价值,是把分子事件整理成可追溯的通路知识。它不仅收录通路,还提供反应层级的注释。每条注释都尽量有原始文献支持,并与NCBI、Ensembl、UniProt、UCSC、ChEBI、PubMed等100多个资源交叉引用。
这意味着,用户看到的不只是一个结果,而是一套可回溯的证据链。对写论文、做课题设计、解释组学结果,这一点非常重要。
截至V80版本,Reactome已收录16个物种数据。仅人类部分就包含14,108个反应、2,580条通路、11,084个蛋白质、13,869个复合物、1,987个小分子和532种药物,并有34,703篇文献支持。这说明它不是实验室内部整理的小数据库,而是一个规模大、证据强的通路资源。
1.2 谁最适合用它
reactome数据库 常用于三类场景。
- 临床医生,用于理解疾病相关信号通路。
- 遗传学和基因组学研究人员,用于解释高通量测序结果。
- 系统生物学和生信人员,用于构建疾病通路模型。
如果你的工作涉及差异表达分析、单细胞测序、蛋白组学或多组学整合,Reactome都能直接派上用场。它既能做单基因检索,也能做整批基因的通路富集分析。
2. 第一步,学会搜索你关心的分子或通路
2.1 用首页搜索框直接检索
reactome数据库 的入门方式很简单。打开首页后,直接在搜索框输入基因、蛋白、复合物或通路关键词即可。比如输入TP53,系统会返回与该基因相关的反应、通路和注释信息。
你还可以按物种、分子类型等条件筛选结果。这样能减少无关信息,尤其适合在跨物种比较时使用。
对初学者来说,建议先从一个明确的基因开始。比如肿瘤研究可查TP53,免疫研究可查IL6或STAT3。先看它属于哪些通路,再追溯到上下游分子。这样更容易建立机制框架。
2.2 用Pathway Browser看通路全貌
搜索后,不要只停留在结果列表。reactome数据库 的Pathway Browser能把通路结构层层展开。你可以看到某个反应属于哪条通路,上游和下游分别是什么。
这类可视化很适合做汇报。因为它能把抽象的基因名单转化为直观的通路图。对于医学生和临床科研人员而言,这比单纯看表格更容易理解生物学意义。
如果你在写文章,Pathway Browser还能帮助你确认某个基因是否真正在目标通路中出现,避免把“相关”误写成“直接参与”。
3. 第二步,把基因列表变成通路结果
3.1 使用Analysis Tools做富集分析
当你已经有一批差异基因时,reactome数据库 最实用的功能之一就是Analysis Tools。上游知识库中提到,用户可在拿到公司或平台输出的高通量初步结果后,筛选出关注的基因,例如差异显著的前20个基因,再进行深入分析。
常用入口是“Analyse gene list”。把基因列表输入后,系统会输出通路富集结果。一般会选择pValue或FDR小于0.05 的通路作为重点展示对象。这个阈值设置能帮助你把主要信号和背景噪音分开。
富集结果的价值在于,它回答的是“这批基因最可能参与什么生物过程”,而不是“每个基因单独做了什么”。这正是组学研究最需要的整合视角。
3.2 如何提高结果可解释性
做富集时,输入列表的质量很关键。建议先做三步整理。
- 统一基因ID格式。
- 去除重复项。
- 根据研究目的限定物种。
reactome数据库 支持按物种筛选,这能显著减少错误映射。对人类样本来说,优先确认输入的是人类基因符号或标准ID。对跨物种实验,则要特别注意同源基因映射是否合理。
另外,不要只看显著性。还要看通路名称是否符合你的实验背景。比如免疫刺激样本出现炎症、细胞因子或信号转导通路,通常比随机代谢通路更有生物学解释力。
4. 第三步,学会下载和联动分析工具
4.1 数据和软件都可免费获取
reactome数据库 的一个优势是开放。知识库明确提到,所有数据和软件均可免费下载。对于课题组和教学场景,这意味着可以低成本开展通路分析。
如果你常用R,可以下载ReactomeGSA包做多组学分析。它适合把不同层面的数据放到同一框架里比较。
如果你更习惯可视化软件,可以在Cytoscape中使用ReactomeFIVIz进行通路分析。
这类联动方式的意义在于,把Reactome从“网页数据库”变成“分析流程的一部分”。它不只是查资料,更是分析管线的入口。
4.2 让结果更适合写论文和做汇报
建议把Reactome输出结果整理成三层内容。
- 第一层,显著通路列表。
- 第二层,核心基因和关键反应。
- 第三层,和疾病表型相关的解释。
reactome数据库 给的是机制起点,不是最终结论。你需要结合实验设计、临床表型和其他数据库共同验证。比如再结合表达量、蛋白水平或文献证据,结论会更稳。
在汇报中,优先展示最能代表机制的通路图,而不是堆砌所有富集项。这样更符合科研表达逻辑,也更容易让导师或评审抓住重点。
5. 第四步,掌握常见使用场景
5.1 单细胞和多组学研究怎么用
在单细胞转录组、bulk转录组和蛋白组学中,reactome数据库 常被用来解释差异信号。比如先找出细胞类型特异基因,再做通路富集,就能看到这些细胞最活跃的生物过程。
对多组学研究来说,ReactomeGSA更有价值。因为它能把不同组学层面的变化统一到通路层面,减少“各看各的”的碎片化问题。系统生物学研究者尤其适合用它构建正常和疾病状态下的变异通路模型。
5.2 你需要避免的三个常见错误
使用reactome数据库 时,常见问题主要有三个。
- 只看显著性,不看生物学背景。
- 输入ID不规范,导致映射错误。
- 直接把富集结果当成因果结论。
这三个问题都很常见,也最容易影响文章质量。正确做法是,先确认输入数据,再看富集结果,最后回到原始实验和文献进行解释。
如果你希望把这些步骤做得更高效,建议使用解螺旋的数据库与生信支持服务。它能帮助你更快完成基因列表整理、通路分析和结果可视化,减少重复试错,把更多时间留给实验设计和论文写作。
总结Conclusion

reactome数据库的上手逻辑其实很清楚:先搜索,后浏览,再做富集,最后联动工具和文献解释。 它的优势在于开源免费、人工审核、证据链完整,适合医学生、医生和科研人员把高通量结果快速转成通路结论。
如果你正在处理差异基因、单细胞数据或多组学结果,不妨直接从Reactome开始。想少走弯路,可以结合解螺旋的专业支持,把通路分析做得更快、更准、更适合发表。
- 引言Introduction
- 1. 先认识Reactome数据库的定位
- 2. 第一步,学会搜索你关心的分子或通路
- 3. 第二步,把基因列表变成通路结果
- 4. 第三步,学会下载和联动分析工具
- 5. 第四步,掌握常见使用场景
- 总结Conclusion