引言Introduction
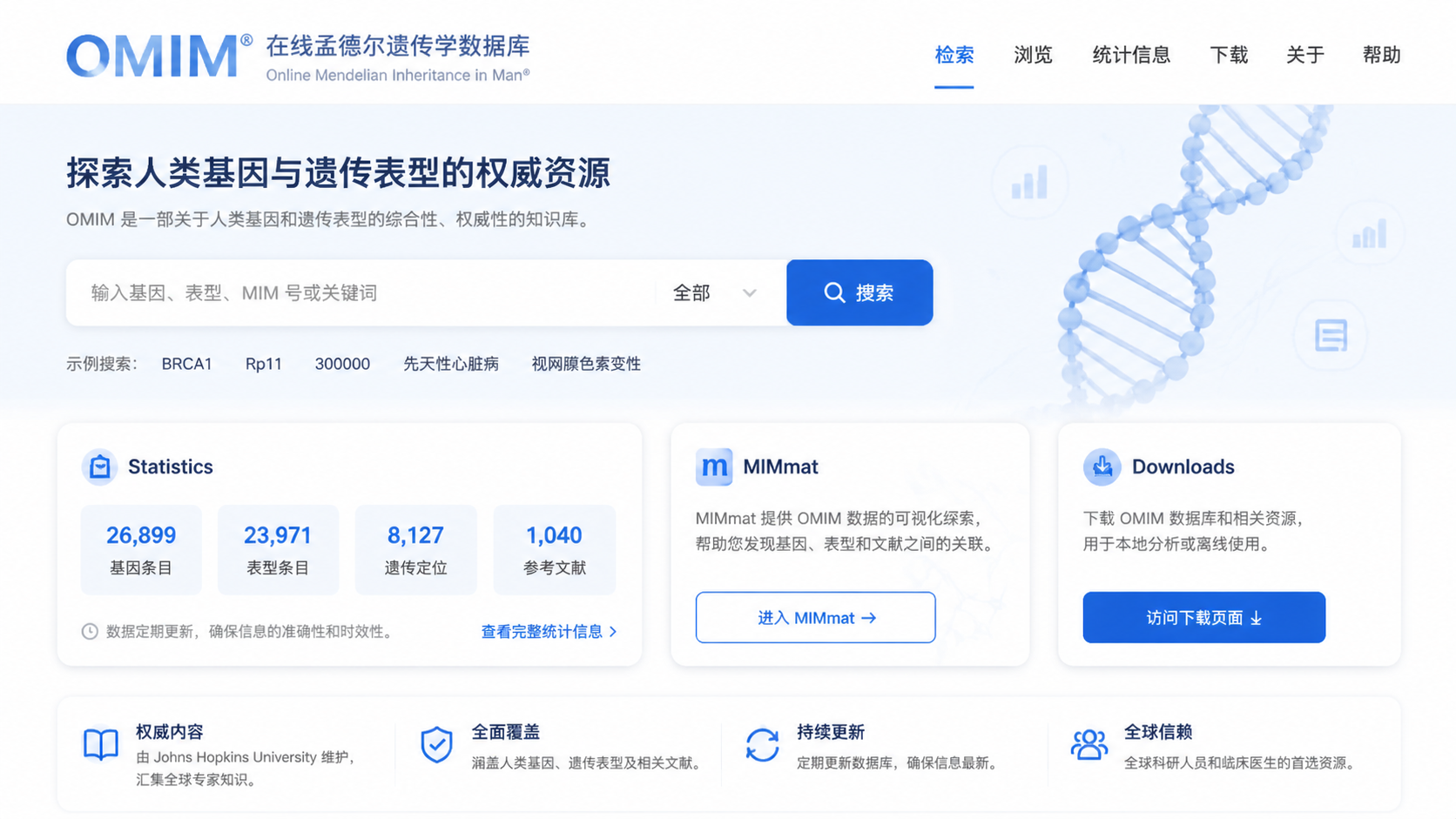
OMIM数据库怎么用,很多医学生和科研人员的共同痛点,是“知道它重要,却不清楚怎么快速检索”。如果你也常被基因名、表型名、MIM编号和更新信息弄乱,这篇文章会用3步带你建立清晰方法。
1. 先认识OMIM数据库的定位,再开始检索
1.1 OMIM数据库是什么
OMIM数据库是一个权威的人类基因与遗传表型概要数据库,免费提供下载数据,并且每日更新。它收录了全部已知孟德尔疾病 和16000多个基因 ,重点关注表型与基因型之间的关系 。这意味着,它不是普通文献库,而是面向遗传病研究的专业索引工具。
对医学生、医生和科研人员来说,OMIM数据库最有价值的地方在于,它把疾病、基因、突变和临床表现串联起来。你可以从一个临床表型切入,也可以从一个基因名反查相关疾病。这一步决定你后面的检索是否高效。
1.2 它适合查什么
OMIM数据库的检索入口支持多种常见信息。包括:
- 临床特征
- 表型名称
- 基因名
- 染色体定位
- MIM编号
从知识库来看,OMIM主要有四类检索对象。Gene Entry 对应基因条目,Phenotypic Entry 对应表型条目,Gene Map 对应基因图谱,External Links 则提供外部资源链接。
如果你研究的是单基因病、家系分析、候选基因验证,OMIM数据库通常是第一站。
1.3 先看懂符号和更新信息
进入OMIM数据库首页后,很多人会忽略Statistics模块。其实它很重要。你可以查看新发现和更新的基因数,也能看到已知分子基础表型总数、已知表型致病基因总数等统计信息。
条目符号也要先看懂:
*表示一个基因+表示已知基因和表型描述#表示描述条目,通常是疾病表型%表示分子基础未知
先理解这些符号,能减少后续误读条目的风险。
2. 用3步掌握OMIM数据库专业检索
2.1 第一步,选对检索模式
OMIM数据库首页提供三种核心模式:
- OMIM模式
- Clinical Synopses模式
- Gene Map模式
如果你要查疾病、基因、突变、MIM编号,优先用OMIM模式。
如果你想快速查看临床概要,可以进入Clinical Synopses。
如果你关心基因组区域、染色体条带或定位信息,用Gene Map更合适。
模式选错,后面的结果就会偏。 这是最常见的低效原因。
2.2 第二步,合理设置检索条件
在OMIM模式下,知识库给出了较完整的高级检索选项。你可以限定:
- 时间:Relevance、Date Updated、Date created
- 检索词类型:MIM编号、题目、文本、等位基因突变体、HGNC编号、贡献者
- 条目类型:等位基因突变体、临床概要、基因图谱定位
- MIM前缀:
*、+、#、% - 染色体:1到22、X、Y、线粒体
- 时间范围:创建或更新时间
这一步的关键不是把条件全部勾满,而是围绕你的研究问题做限制 。比如:
- 查已知基因对应的疾病,优先输入基因名。
- 查临床表型对应基因,优先输入疾病表型词。
- 查某染色体区域候选基因,使用Gene Map模式并限定区域。
如果检索对象是“breast cancer”这类广义表型,建议先用标题或文本检索,再逐层缩小范围。先广后窄,比一开始就过度限定更稳。
2.3 第三步,学会从结果页反向验证
检索到结果后,不要只看标题。OMIM数据库的价值在于条目内容本身。建议依次检查:
- 条目类型是否匹配
- 是否属于已知基因或已知表型描述
- 临床概要是否与你的病例一致
- 外部链接是否能支持进一步验证
- 更新时间是否足够新
对于科研人员来说,尤其要关注条目的更新日期和证据链。OMIM数据库每日更新,但更新不等于结论自动成立 。你仍需要结合文献、测序结果和临床判断。
3. 提高效率的两个实用功能
3.1 MIMmatch:跟踪你真正关心的条目
如果你经常研究同一批疾病或基因,MIMmatch很有用。它可以帮助你:
- 跟踪感兴趣条目的更新
- 跟踪表型条目的更新
- 保存检索内容
- 与其他研究者建立关注关系
注册后会进入My Dashboard,其中包含MIM Entries Flagged、Phenotypic Series Flagged和Saved Searches。
这对持续追踪某个遗传病方向非常实用。 尤其适合课题组长期做同一疾病谱系研究的人。
3.2 保存检索历史,减少重复劳动
OMIM数据库还支持检索历史管理。你可以编辑、复用或清除历史记录。对于高频检索场景,比如反复比较同一疾病谱系、重复筛选候选基因,这个功能能显著节省时间。
实操上建议这样做:
- 固定常用关键词
- 保存高质量检索式
- 对不同项目分组管理
- 每次更新后重新核查结果
把检索过程标准化,才能把OMIM数据库真正变成工作流的一部分。
4. 3个高频使用场景,快速上手
4.1 场景一,查疾病对应基因
当你面对一个明确的遗传病名称时,直接在搜索框输入疾病名。然后优先查看Phenotypic Entry和相关Gene Entry。重点关注临床提要、已知致病基因和外部链接。
4.2 场景二,查基因对应表型
当你有候选基因时,直接输入基因名。查看它对应的表型、等位基因变异和相关疾病条目。这个过程对变异解读、家系分析和病例报告非常有帮助。
4.3 场景三,查染色体区域候选基因
如果你拿到的是染色体区段,比如某一区域的拷贝数变异或连锁定位,可使用Gene Map模式。按基因组区域、细胞定位条带或染色体号检索,再结合结果筛选候选基因。
这类检索最适合把“区域”快速缩小为“基因名单”。
总结Conclusion
OMIM数据库怎么用,核心不是记住所有按钮,而是掌握一个稳定流程。先判断你要查的是基因、表型还是染色体区域,再选择对应模式,最后用结果页反向验证。 对医学生、医生和科研人员来说,这套3步法足够支撑日常的遗传病检索、变异解读和课题查证。
如果你想把检索效率做得更高,建议结合MIMmatch和检索历史管理,把常用条目长期追踪起来。从现在开始,用解螺旋的专业课程和工具思路,系统掌握OMIM数据库,能让你的文献与数据检索更快、更准、更稳。

- 引言Introduction
- 1. 先认识OMIM数据库的定位,再开始检索
- 2. 用3步掌握OMIM数据库专业检索
- 3. 提高效率的两个实用功能
- 4. 3个高频使用场景,快速上手
- 总结Conclusion