引言Introduction
呼吸专科研究常见痛点是,数据分散、分析重复、发文周期长。呼吸专科生信数据库 把公开数据、临床信息和分析流程整合到同一平台,可显著减少检索、清洗和重复作图时间,帮助医学生、医生和科研人员更快进入结果验证阶段。

1. 呼吸研究为什么需要专科化数据库
1.1 传统生信研究的主要耗时点
呼吸系统疾病的研究对象多,常见方向包括肺癌、慢阻肺、哮喘、肺纤维化和感染性疾病。问题在于,数据来源往往分散在不同数据库和文献中。研究者需要自行检索、筛选、清洗、整合,再完成差异分析、富集分析和可视化。
这一步最耗时。 如果没有统一的数据框架,重复劳动会非常多。尤其是做多个队列验证时,每个数据集都要重新处理,效率会明显下降。
上游知识库中提到,数据库化整合的核心价值就是把常规分析“封装”起来。研究者不用每次从零开始,而是直接调用已整理好的数据和模块。
1.2 专科数据库比通用检索更高效
呼吸专科生信数据库 的优势,不只是“数据多”,而是“方向准”。它围绕呼吸系统疾病建立,能把相关公共数据、临床特征、预后信息和常用分析模块预先组织好。这样一来,研究者输入疾病、基因或表型,就能快速定位结果。
知识库中也说明,类似的数据库模式在肿瘤、临床预后和多组学整合中已经被反复验证。对于呼吸专科研究,这种思路同样成立。专科化比泛化更容易形成稳定的研究路径。
2. 呼吸专科生信数据库能提升哪些环节
2.1 缩短数据检索与预处理时间
公共数据库很多,但真正能用的数据并不多。研究者通常要花大量时间判断样本量、平台类型、注释质量和是否可比较。知识库强调,做生信研究首先要甄别数据集质量,避免把不适合的队列硬塞进分析流程。
呼吸专科生信数据库 把这些基础工作前置后,研究者可以直接使用已筛过的队列。对课题组来说,这意味着少走弯路。对学生来说,这意味着更快完成一篇可投稿的初稿。
2.2 提高分析一致性和结果可复现性
研究效率不只是“快”,还要“稳”。如果每次分析参数不同,结果就很难复现。数据库化工具的价值之一,就是把常用流程标准化,包括:
- 表达差异分析
- 生存分析
- 相关性分析
- 通路富集分析
- 基因表达可视化
标准化流程能减少人为波动。 这对教学、科研协作和多中心项目尤其重要。多个成员使用同一套规则,结果更容易统一,文章也更容易形成完整叙事。
2.3 支持从“大文章”到“小文章”的连续产出
知识库提到,丰富的数据集不仅能支撑高分文章,也能支持“小文章”持续产出。这个逻辑对呼吸研究非常实用。一个成熟的呼吸专科数据库,既可以做宏观机制研究,也可以围绕单个分子、单条通路或一个临床表型,拆分出多个子课题。
这能显著提高课题组产出效率。
例如:
- 先用数据库筛出候选基因。
- 再做单基因的表达、预后和分层分析。
- 最后结合临床特征和验证队列完善结论。
这样,基础资源可以重复利用,研究链条更长,成果转化更快。
3. 建设呼吸专科生信数据库时要关注什么
3.1 数据质量优先于数据数量
上游知识库反复强调,选数据集不能只看“有多少”,还要看“能不能用”。呼吸专科数据库也一样。建议优先关注以下几点:
- 样本量是否足够
- 分组是否清晰
- 平台是否一致
- 注释是否完整
- 是否适合做分层验证
没有质量的数据,反而会拖慢研究进度。 因为后续补救、重算和重写的成本更高。对呼吸疾病研究尤其如此,因为不同疾病的临床异质性很强。
3.2 让数据库服务于明确的课题目标
知识库中提到,数据库不是为了“做大而大”,而是要有明确切入点。呼吸研究可以优先围绕高频临床问题设计,比如预后、免疫微环境、耐药、炎症反应、纤维化进展和药物靶点筛选。
先定问题,再定功能。
如果目标是发文,数据库模块就要围绕文章主线设计,而不是堆砌功能。对于医学生和年轻科研人员来说,这一点尤其重要。因为时间有限,最有效的路径是用少量高价值模块快速形成结果。
3.3 结合公共数据和本地数据,效率更高
知识库给出的经验很明确。单靠公共数据可以起步,但如果能结合本地队列、测序数据或验证数据,文章完整度会更高。呼吸专科研究尤其适合这一模式,因为很多临床场景都有明确样本来源。
公共数据负责发现,本地数据负责验证。
这种组合能兼顾效率和可信度。对研究生来说,前期可先用数据库完成假设生成,再向导师申请小规模验证实验,路径更清晰。
4. 呼吸专科生信数据库在实际发文中的价值
4.1 帮助快速形成可投稿框架
知识库中提到,数据库文章的优势之一是能把常规分析封装成平台形式,提升辨识度。对于呼吸领域,这种文章结构通常包括:
- 疾病背景与临床需求
- 数据整合与分组策略
- 核心基因或核心通路筛选
- 预后模型或临床模型构建
- 外部队列验证
- 机制补充或实验验证
这个结构非常适合快速写作。
因为每一步都有固定输出,作者只需要围绕核心问题组织语言,就能形成较完整的文章骨架。
4.2 提升团队协作和课题复用率
数据库化平台最大的优势之一,是团队协作效率高。不同成员可以分别负责数据筛选、统计分析、图表整理和文字撰写。知识库也提到,团队作战、个性化分析和模块化整合,是提高发文概率的重要方式。
对呼吸专科课题组来说,一套成熟的呼吸专科生信数据库 可以反复服务多个项目。上一篇文章筛出来的候选基因,下一篇还可以继续用于亚组分析、药物分析或新队列验证。研究积累会越来越快。
4.3 让研究从“单次结果”变成“持续产出”
这类数据库的真正价值,不只是帮你做完一篇文章,而是形成持续产出能力。知识库中提到,数据库整合后,同行引用时不需要重复提交代码,只需引用原始数据库或平台文章即可。这会反过来提升学术影响力。
对呼吸专科研究者而言,这意味着更强的可持续性。
当一个数据库稳定运行后,后续新数据、新分子、新算法都可以继续接入,研究效率会随着使用次数不断提高。
总结Conclusion
呼吸专科研究要想提效,关键不在于盲目增加分析数量,而在于建立可复用、可验证、可扩展的研究平台。呼吸专科生信数据库 能把数据筛选、流程标准化和结果输出整合起来,明显减少重复劳动,也更适合医学生、医生和科研人员在有限时间内完成高质量课题。
如果你希望把呼吸疾病研究从“手工分析”升级为“平台化产出”,可以考虑借助解螺旋品牌 的数据库化与个性化分析思路,尽快把课题落地到可投稿的结果。
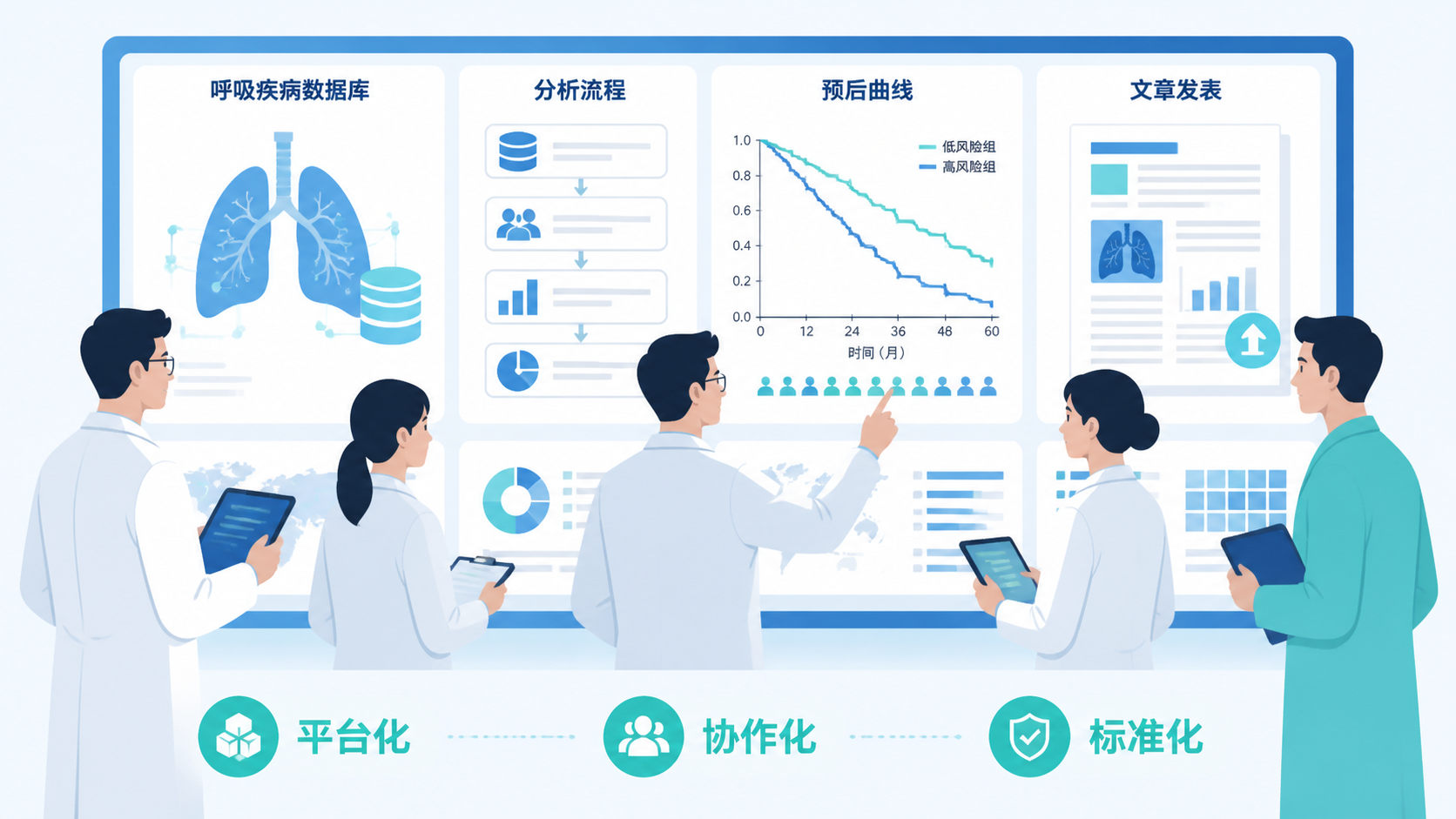
- 引言Introduction
- 1. 呼吸研究为什么需要专科化数据库
- 2. 呼吸专科生信数据库能提升哪些环节
- 3. 建设呼吸专科生信数据库时要关注什么
- 4. 呼吸专科生信数据库在实际发文中的价值
- 总结Conclusion