引言Introduction
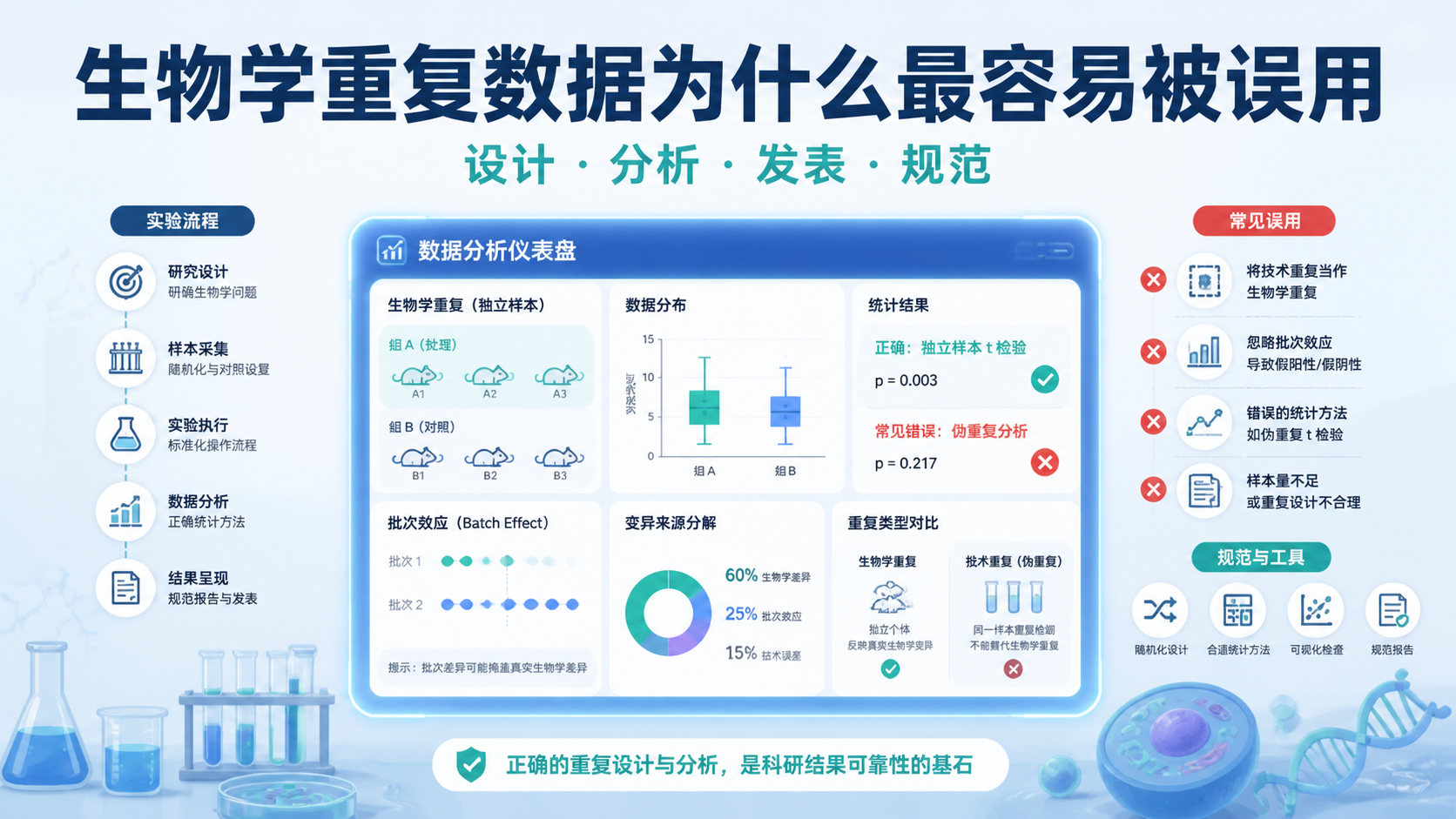
很多实验做完后,结果看似漂亮,投稿却被质疑。问题常出在生物学重复数据 的设计与呈现。重复数不够、把技术重复当成生物学重复、不同批次混在一起分析,都会直接影响统计结论。生物学重复数据一旦定义错误,后续再多分析都难以补救。
1. 生物学重复数据为什么最容易被误用
1.1 重复的“单位”常被混淆
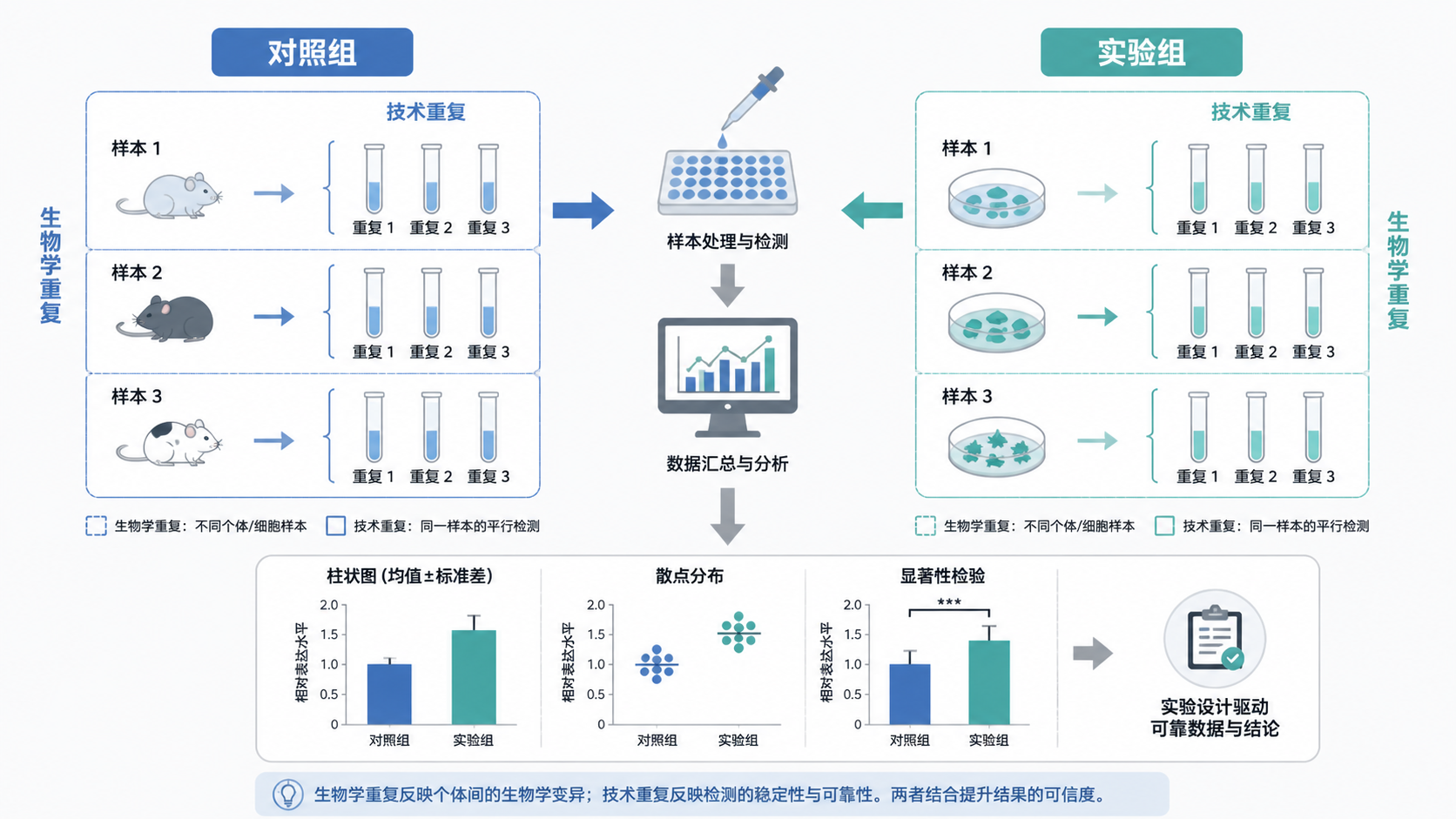
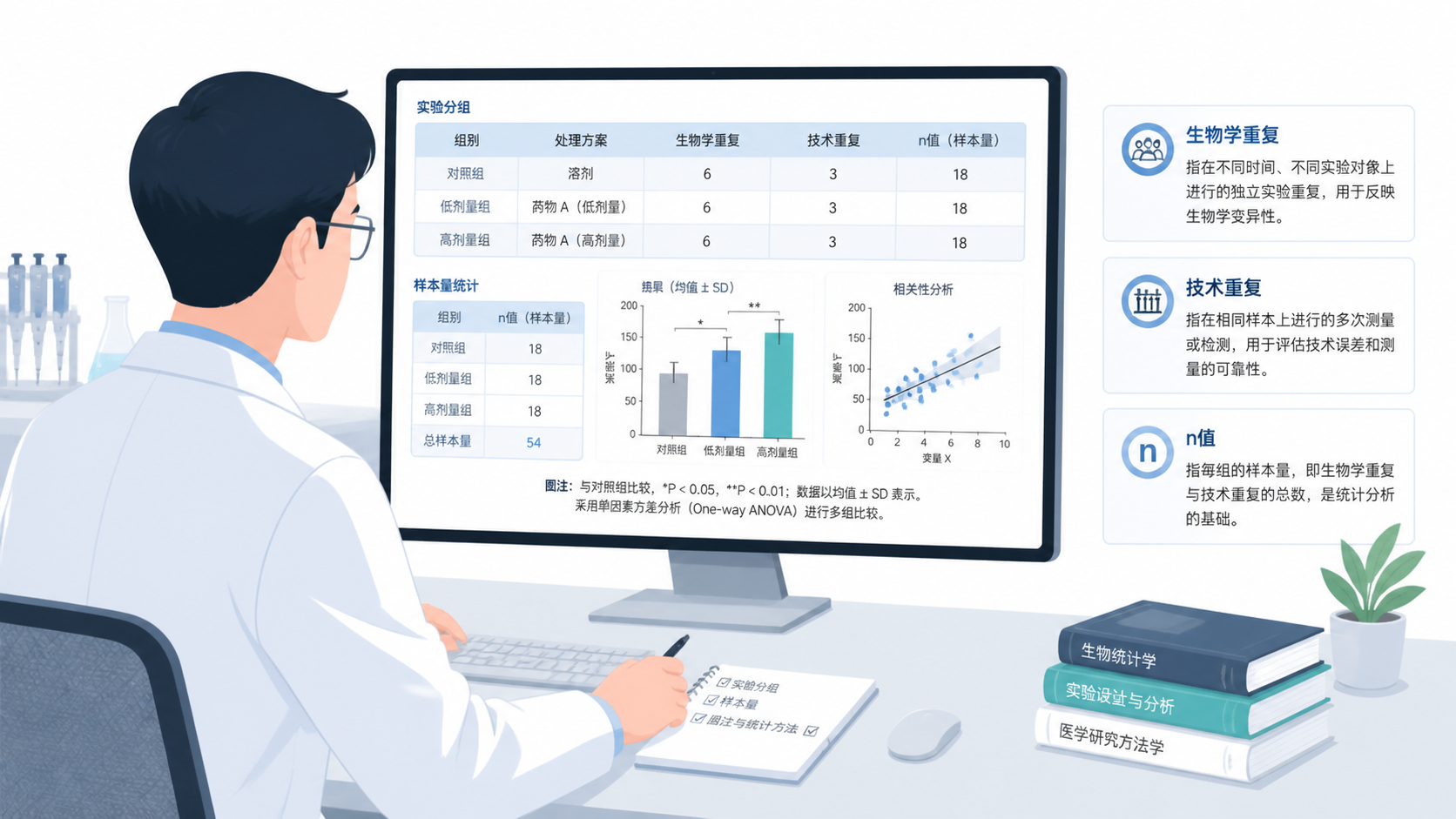
在科研写作里,最常见的错误不是没有重复,而是把不同层级的重复混为一谈 。例如,同一批蛋白样本做了5次Western blot,这属于技术性重复,不等于5个生物学重复数据。前者只能说明检测流程稳定,不能证明样本本身具有独立性。
真正的生物学重复数据,要求样本来源彼此独立。 比如独立培养的细胞、不同个体的动物、不同病人的临床样本。只有这种设计,才能反映真实的个体差异。
1.2 复孔不等于重复
很多初学者会把同一块板上的复孔当作重复数。实际上,复孔只能提高单次检测的稳定性,不能替代独立样本。
如果一组实验只有1份样本,却做了3个复孔,这不是3个生物学重复数据。投稿时一旦被审稿人追问,文章很容易被认定证据不足。
1.3 批次差异会放大误差
生物学重复数据最怕批次偏差。比如动物实验分了多个批次,若不同批次的饲养条件、造模时间、检测平台不同,数据就可能出现系统性偏移。
批次内重复和批次间重复,不能简单合并成一个n值。 在图注里,如果写“n=24”,但实际是3个批次、每批8只动物,这种表述很容易被质疑。
2. 设计阶段为什么最容易埋下错误
2.1 样本量不足会让波动失真
生物学重复数据最常见的错误,是样本量太少。知识库中提到,计量资料的样本数通常每组不少于3至5例,但在动物实验中,6对6 更常见,因为个体差异更大。
如果只做3对3,可能出现两个样本方向不一致,结果就会非常脆弱。样本少时,偶然波动会被误判为真实效应。
2.2 对照组设置不完整
重复问题不仅在数量,也在分组逻辑。对照设置的目标,是让各组除了处理因素不同之外,其余条件尽量一致。
常见对照包括:
- 空白对照,或正常对照。
- 自身对照,如同一只动物给药前后比较。
- 组间对照,如不同药物之间比较。
- 标准对照,如与标准值或正常值比较。
如果对照组设置不合理,生物学重复数据再多,也无法说明问题。因为错误的比较对象,本身就会制造假阳性或假阴性。
2.3 样本来源不均衡
临床研究里,这个问题更明显。知识库指出,样本来源可能受年龄、居住地、收入、职业、饮食等影响。
例如,若只收集大医院病例,可能忽略偏远诊所或基层医院患者。这样得到的生物学重复数据,看似数量足够,实际上存在选择偏倚。结果不能代表总体。
3. 分析阶段为什么最容易算错
3.1 n值写法常常不规范
很多论文把“技术重复次数”写成“生物学重复数”,这是最典型的统计错误。
图中n代表独立生物学样本数,不是检测次数。
如果一批细胞只独立培养了3份,但每份做了2次检测,图上应该写n=3,而不是n=6。
3.2 不同批次不能直接相加
在动物实验中,如果每批8只鼠,共做了3批,柱状图里的n通常仍然按每批独立计算,而不是简单写成24。
原因很直接。不同批次之间并非完全独立,合并后会低估方差。统计上看似更“漂亮”,实际上会夸大显著性。
3.3 离群值处理要有原则
生物学重复数据中,个别离群值并不少见。特别是动物模型,死亡、造模失败、样本污染都可能发生。
但离群值不能凭感觉删除。应先回看实验记录,判断是否存在明确技术原因,再决定是否剔除。如果一批实验最终只有少数样本可用,整批实验应视为失败,重做比硬分析更可靠。
4. 发表时为什么最容易被审稿人抓住
4.1 重复类型写不清
审稿人最关心的是:这到底是技术重复,还是生物学重复?
如果文章只写“实验重复3次”,却不说明是独立重复还是同一样本重复,可信度会明显下降。
尤其在图注中,最好明确:
- 样本来源。
- 重复类型。
- 重复次数。
- 统计方法。
4.2 图例和方法不一致
很多稿件的问题,不在实验本身,而在写作表达。方法部分写的是“每组6只”,图注却显示“n=18”。
这种不一致会让审稿人怀疑数据整合方式。对于生物学重复数据,写作必须和原始实验设计完全对应。
4.3 过度依赖单一结果
有些研究只做一次测序或一次临床验证,就想支撑完整机制链条。这样的证据链往往不够稳。
知识库中明确提到,验证生信筛选结果时,常可用ELISA等方法在病人外周血中进行验证,并结合临床资料做相关性分析。
也就是说,生物学重复数据最好与独立验证形成闭环。 这比单点结果更能提升文章说服力。
5. 怎样把生物学重复数据做对
5.1 先定义独立样本
先问自己一个问题:哪些样本彼此真正独立?
独立个体才有资格成为生物学重复数据。若样本来自同一培养体系、同一组织块、同一检测批次,就不能简单视为独立重复。
5.2 预先写清分组规则
实验开始前就要明确:
- 对照组与实验组如何对应。
- 每组最少多少独立样本。
- 哪些情况算失败样本。
- 批次之间是否需要分开统计。
这种前置设计,能显著降低后期补写和误读风险。
5.3 区分生物学重复与技术重复
写论文时,建议在方法和图注里同时说明:
- 生物学重复数。
- 技术重复次数。
- 是否合并均值。
- 是否采用独立批次分析。
这一步看似琐碎,却是决定论文可信度的关键。
5.4 优先保证样本质量
重复数再多,样本质量差也没用。比如动物模型不稳定、临床入组不均衡、测序样本降解,都会让生物学重复数据失去意义。
宁可少而稳,也不要多而乱。 这是实验设计里最实用的原则。
6. 用规范工具减少重复数据错误
对于医学生、医生和科研人员来说,生物学重复数据的错误,往往不是“不会做”,而是“做了但没写对、没算对、没分清”。
这类问题在组稿、投稿、返修时尤其高发。借助解螺旋的科研写作与分析支持工具,可以更系统地检查样本量、重复类型、图注表达和统计逻辑,减少低级错误。把重复设计、数据整理和论文表达统一起来,才是提高通过率的关键。
总结Conclusion
生物学重复数据最易出错,核心原因只有一个。它同时牵涉实验设计、统计分析和论文表达。样本独立性不足、复孔冒充重复、批次混算、图注不清,都会让结果失真。
对科研人员来说,最稳妥的做法是:先定义独立样本,再区分技术重复与生物学重复,最后用规范图注和统计方法完整呈现。如果你希望在科研写作、数据整理和投稿返修中少踩坑,可以借助解螺旋的专业支持,把生物学重复数据从源头做规范。
- 引言Introduction
- 1. 生物学重复数据为什么最容易被误用
- 2. 设计阶段为什么最容易埋下错误
- 3. 分析阶段为什么最容易算错
- 4. 发表时为什么最容易被审稿人抓住
- 5. 怎样把生物学重复数据做对
- 6. 用规范工具减少重复数据错误
- 总结Conclusion