引言Introduction
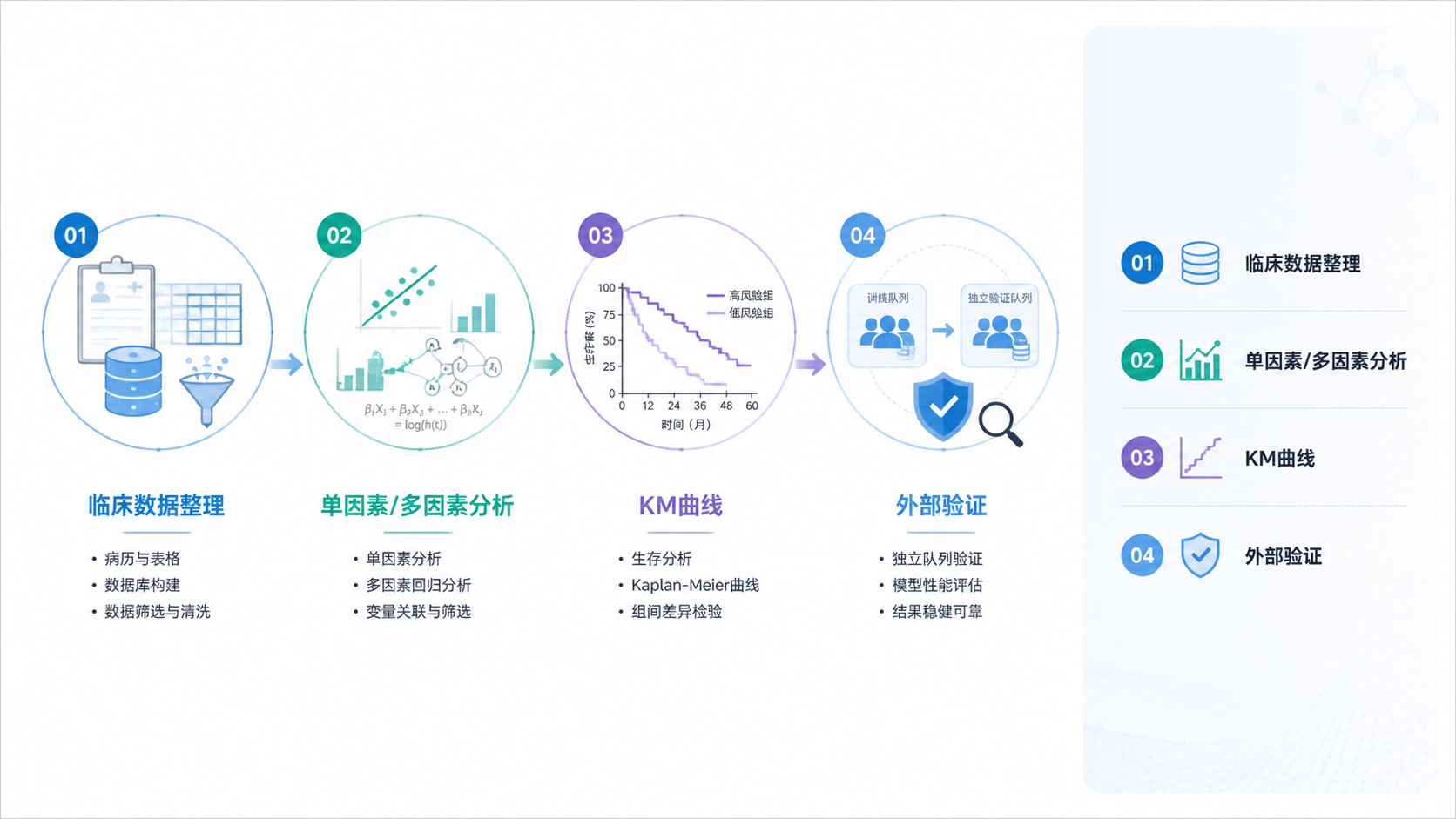
癌症临床数据怎么读,常见问题不是“数据太少”,而是“变量太杂、缺失太多、结论不稳”。面对癌症临床数据,先抓基线、再看分层、最后做生存验证,效率最高。 
1. 先读懂癌症临床数据的结构
1.1 先看数据来源和样本边界
癌症临床数据通常来自 TCGA、ICGC 这类公开队列,也可能来自单中心回顾性队列。第一步不是直接建模,而是确认样本范围。比如肝癌研究中,TCGA 队列可包含肿瘤组织和癌旁组织,外部队列还可用于验证模型稳定性。
你要先回答三个问题。
- 这批癌症临床数据有多少例。
- 包含哪些结局指标,如总生存期、疾病特异性生存期。
- 是否有可用的分组变量,如分期、分级、年龄、性别、血管浸润。
如果样本定义不清,后面的差异分析、生存分析和回归结果都可能失真。临床数据解读的核心,不是把表跑出来,而是先保证“样本可比”。
1.2 先处理缺失值,再谈统计
癌症临床数据最常见的问题是缺失值。课程中的做法很明确,先统计缺失比例,再决定保留还是删除。一般来说,缺失超过 20% 的变量,优先过滤。 剩余变量可进一步用多重插补补齐。
这个步骤有两个意义。
- 避免因为空缺太多导致模型不稳定。
- 避免临床特征表出现偏倚。
对于连续变量,常用多重插补。它不是简单填均值,而是基于重复模拟生成完整数据集。在正式分析前,必须比较插补前后分布,确认没有明显偏移。 这一步能显著提高癌症临床数据的可信度。
1.3 把原始变量转成可分析变量
原始临床字段往往不适合直接建模。需要做格式转换。比如:
- 年龄按 60 岁分层。
- 组织学分级合并为低级别和高级别。
- T 分期合并为早期和晚期。
- 血管浸润转成“有”与“无”。
这样处理的好处是,变量更适合做基线表、单因素分析和多因素 Cox 回归。癌症临床数据解读,本质上就是把“原始字段”变成“临床可解释变量”。
2. 用三张表抓住关键临床信息
2.1 先看基线资料表
基线资料表是临床研究的起点。它告诉你样本是否均衡,哪些变量可能影响结局。标准做法是先生成 Table 1,查看年龄、性别、分级、分期、浸润等变量的分布。
例如,在肝癌队列中,可以看到年龄、组织学分级、TNM 分期、血管浸润等信息的比例分布。如果高危组和低危组在关键临床变量上明显不平衡,后续结果就需要谨慎解释。
基线表的价值不只是“描述样本”,更是为后面的分层分析和回归分析做铺垫。看懂基线表,才算真正开始读癌症临床数据。
2.2 再看单因素分析
单因素分析的作用,是从一堆变量中找出和结局相关的候选因素。对于癌症临床数据,常见做法是先对临床因素进行单因素 Cox 回归,观察哪些变量与生存显著相关。
这一步通常会输出:
- HR。
- 95% CI。
- P 值。
如果某个变量的 HR 明显大于 1,说明风险上升;小于 1,说明可能有保护作用。单因素分析不是终点,而是筛选入口。 它帮助你从临床字段中找出值得进一步验证的变量。
2.3 最后看多因素分析
多因素分析更关键。它回答的是:在控制其他变量后,这个因素是否仍然独立影响预后。对医学生和科研人员来说,这一步是判断模型是否“真有用”的核心。
在临床队列中,常见做法是把风险评分、病理分期、组织学分级等一起放进多因素 Cox 模型。若高危组在校正临床因素后仍显著不良,说明这个指标有独立预后价值。这也是癌症临床数据从“描述”走向“预测”的分水岭。
3. 用生存曲线和外部验证判断结论是否可靠
3.1 生存曲线看组间差异
临床数据解读不能只看回归表,还要看生存曲线。KM 曲线是最直观的工具。把患者按高危和低危分组后,观察两组生存是否明显分离。
如果 log-rank 检验显著,说明分组确实和结局有关。课程案例中,预后模型的 1 年、3 年、5 年 AUC 分别达到 0.72、0.762、0.745,说明模型有较好的区分度。AUC 高于 0.7,通常就说明模型具备一定预测能力。
对癌症临床数据来说,KM 曲线和 ROC 曲线要一起看。前者看“有没有差异”,后者看“能不能分开”。
3.2 看分层一致性,避免假阳性
一个好模型,不应只在总体样本里有效,还应在临床分层中保持一致。比如高分期、晚 T 分期、较高组织学分级的患者,风险评分也更高,这说明模型和疾病进展方向一致。
这种一致性非常重要。如果一个指标和肿瘤侵袭程度不一致,哪怕统计显著,也要怀疑其生物学解释。
在解读癌症临床数据时,建议至少检查以下关系:
- 风险评分与分期。
- 风险评分与分级。
- 风险评分与血管浸润。
- 风险评分与生存结局。
这些分析能帮助你判断模型是不是“看起来有用”,还是“真正有临床意义”。
3.3 外部队列验证是最后一道门槛
只在单一队列里显著,远远不够。高质量的癌症临床数据分析,通常还会用外部队列验证。比如在 TCGA 建模后,再用 ICGC 队列复核,采用同一套基因或评分公式计算风险值。
如果外部验证仍能分出高危和低危,并保持生存差异,模型可信度会明显提高。
这也是 E-E-A-T 中“可信度”的关键来源。不是因为结论漂亮,而是因为它经得住独立数据集检验。
3.4 最后一步,落到可执行的分析流程
如果你要系统解读癌症临床数据,建议直接按这个顺序走:
- 整理临床表,处理缺失值。
- 统一变量格式,构建分层变量。
- 做基线表,检查组间平衡。
- 做单因素分析,筛候选变量。
- 做多因素分析,确认独立性。
- 结合 KM 曲线、ROC 曲线和外部验证,判断模型是否稳健。
这 3 步其实可以概括为:先整理、再筛选、后验证。 这是临床研究里最实用的读数据框架。
在实际操作中,解螺旋品牌提供的分析思路更适合医学生、医生和科研人员快速上手。无论是临床变量整理、缺失值处理,还是生存模型构建,都可以沿着标准化流程推进,减少试错时间。把癌症临床数据交给规范的方法,才能更快得到可靠结论。
总结Conclusion
癌症临床数据并不难读,难的是一开始就跳进建模。真正高效的做法,是先看数据结构,再抓临床变量,最后用生存和外部验证确认结论。记住这 3 步,解读癌症临床数据会清晰很多。 如果你希望把这些流程真正落地到科研项目中,可以结合解螺旋的系统化方法,按标准流程整理、分析和验证,让临床数据更快转化为可信结论。
- 引言Introduction
- 1. 先读懂癌症临床数据的结构
- 2. 用三张表抓住关键临床信息
- 3. 用生存曲线和外部验证判断结论是否可靠
- 总结Conclusion