引言Introduction

在蛋白组学、转录组和药物筛选中,互作数据格式 不统一,最常见的问题不是“没有数据”,而是“数据难复用、难对接、难发表”。字段混乱、命名不一致、证据链缺失,都会直接影响分析效率和结果可信度。本文用9步拆解专业模板构建方法,帮助医学生、医生和科研人员把互作数据整理成可检索、可共享、可审稿的标准格式。
1. 明确互作数据的使用场景
1.1 先定义数据要服务什么问题
构建互作数据格式 前,第一步不是填表,而是明确用途。不同场景决定不同字段。
常见场景包括:
- 蛋白-蛋白互作分析。
- 药物-靶点互作整理。
- 基因调控网络构建。
- 文献证据汇总与数据库入库。
如果目标是机器学习建模,格式要强调结构化和完整性。如果目标是论文补充材料,格式要强调证据来源和实验条件。场景越清楚,后续字段越稳定。
1.2 区分人工阅读和机器处理需求
人工阅读更关注可解释性,机器处理更关注一致性。比如同样是“阳性互作”,人工可以接受描述性文字,机器却需要固定编码。
建议在模板设计时同时考虑:
- 人工可读字段,如实验结论、备注。
- 机器可读字段,如标准ID、数值型证据。
- 统一枚举值,如“Y/N”“High/Medium/Low”。
这样设计的互作数据格式 ,后续更容易导入Excel、R、Python或数据库。
2. 统一核心对象与命名规则
2.1 先锁定“谁和谁在互作”
互作数据最容易出错的地方,是对象定义不清。必须先明确互作双方是谁,并尽量使用标准数据库ID,而不是只写简称。
建议优先采用:
- UniProt蛋白ID。
- HGNC基因符号。
- Ensembl编号。
- ChEMBL或DrugBank编号。
标准ID优先于自由文本。 自由文本适合展示,不适合做主键。若同一对象存在多个别名,建议保留一个主名称,其他作为别名字段。
2.2 建立统一的命名规范
命名规范要在项目开始时固定下来,避免后期反复清洗。比如:
- 基因符号统一大写。
- 物种名称使用拉丁学名。
- 细胞系名称按标准写法。
- 组织样本按来源和病理类型分层。
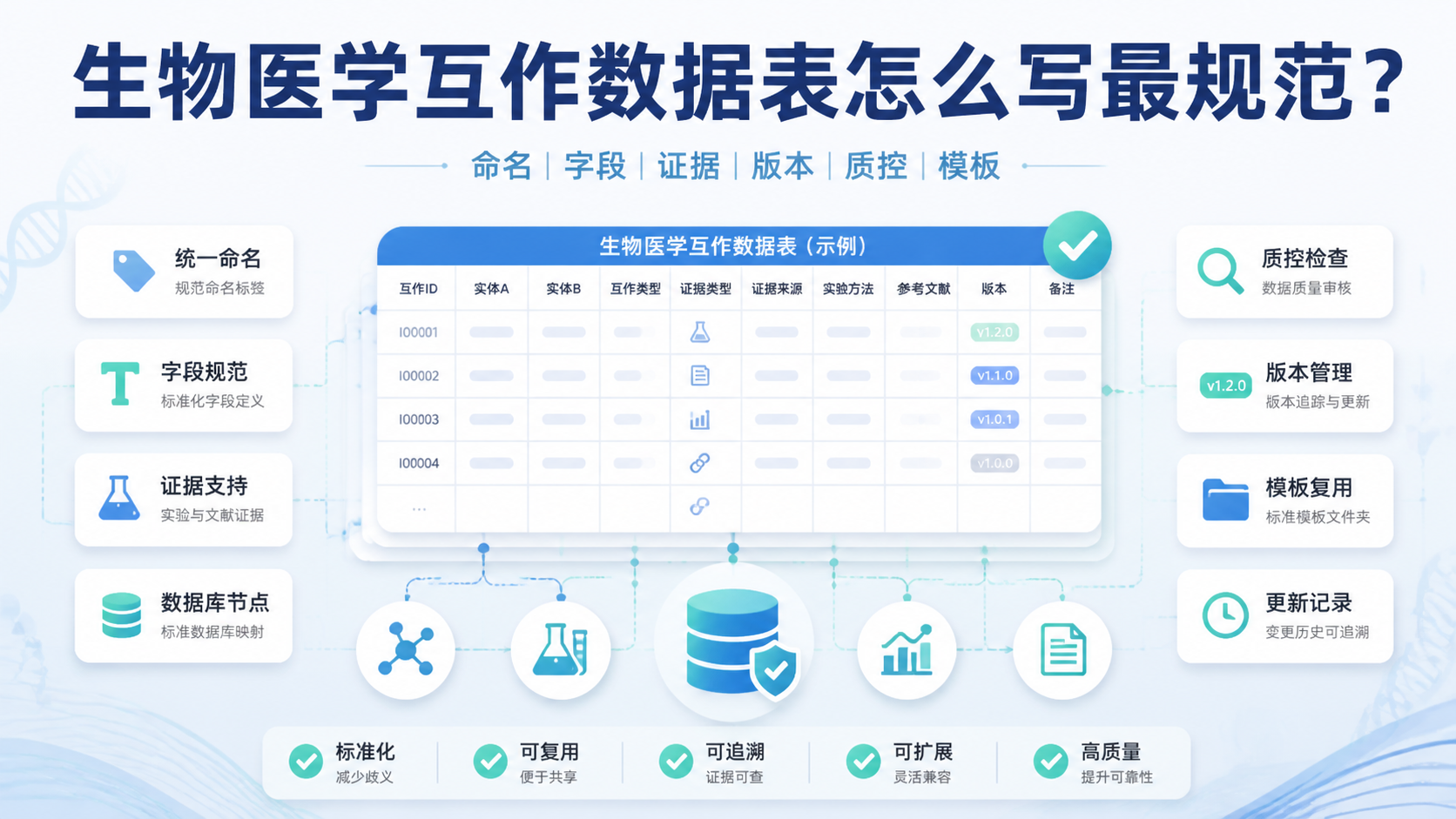
一个稳定的互作数据格式 ,通常至少包含:
- 主对象ID。
- 主对象名称。
- 互作对象ID。
- 互作对象名称。
- 物种信息。
这一步看似简单,但它决定了数据能否真正被复用。
3. 设计最小必需字段
3.1 先做“最小可用模板”
专业模板不等于字段越多越好。初始阶段应先建立最小必需字段,保证每条记录都能被追溯。
建议核心字段至少包括:
- 记录编号。
- 互作双方ID。
- 互作类型。
- 证据来源。
- 实验方法。
- 文献PMID或数据库来源。
- 结论状态。
最小字段集的目标,是保证每条数据都有身份、证据和结论。
3.2 再按研究目标扩展字段
如果项目需要更深入分析,可以继续增加:
- 物种。
- 组织或细胞系。
- 处理条件。
- 作用方向。
- 置信度评分。
- 重复次数。
- 统计学结果。
扩展时要遵循一个原则:每新增一个字段,都要回答一个明确问题。 否则只会增加维护成本。高质量的互作数据格式 ,不是字段最多,而是字段最有用。
4. 规定证据类型与实验来源
4.1 证据要可追溯
互作关系最怕“只有结论,没有证据”。因此每条记录都应保留来源信息,最好能追溯到原始文献或数据库条目。
常见证据来源包括:
- 实验研究。
- 文献整理。
- 公共数据库。
- 高通量筛选结果。
如果来源是实验数据,建议记录实验平台和方法名称。如果来源是数据库,建议记录数据库名、版本号和下载日期。没有来源的数据,不适合进入正式模板。
4.2 统一实验方法描述
实验方法写法要标准化,避免同义不同写。比如同一类实验不要一会儿写“Co-IP”,一会儿写“免疫共沉淀”,一会儿又写“共免疫沉淀”。
建议建立方法字典,统一为:
- Co-IP。
- Y2H。
- Pull-down。
- SPR。
- ITC。
- qPCR验证。
- ChIP-seq。
这样整理后的互作数据格式 更利于后续统计不同方法的证据强度。
5. 加入互作方向、类型与强度
5.1 互作不是只有“有”或“没有”
很多初学者只记录互作是否存在,但在实际研究中,互作类型和方向同样重要。比如激活、抑制、结合、调控,含义完全不同。
建议至少区分:
- 物理互作。
- 功能互作。
- 调控互作。
- 间接关联。
如果研究对象涉及信号通路,还可增加方向字段,如上调、下调、正向调控、负向调控。类型越清楚,网络图越可靠。
5.2 用统一规则表达强度
若有定量数据,建议统一记录评分或数值范围,而不是随意写“强”“弱”。可采用:
- 定性分级,如1-3级。
- 统计阈值,如P值、FDR。
- 亲和力数值,如Kd。
- 富集倍数或logFC。
对于互作数据格式 而言,强度字段的标准化,能显著提升后续筛选效率,也更方便进行可视化分析。
6. 规范时间、版本与更新记录
6.1 数据要有版本意识
互作数据往往会随着新文献、新实验不断更新。如果没有版本管理,团队成员很难判断哪一版才是最新数据。
建议记录:
- 数据版本号。
- 更新日期。
- 更新人。
- 更新说明。
- 删除或修订原因。
这对课题组协作尤其重要。版本控制是科研数据可信度的一部分。
6.2 保留修改痕迹
不要直接覆盖旧数据。最好采用“新增记录+状态标记”的方式保留历史。例如把旧结论标记为“已修订”,并注明新证据来源。
对长期项目来说,这种做法能避免:
- 结果回溯困难。
- 审稿时证据链断裂。
- 多人协作时发生冲突。
一个成熟的互作数据格式 ,应同时支持当前分析和历史追踪。
7. 统一文件结构与编码规则
7.1 列名要短、清晰、稳定
模板文件建议采用简洁列名,避免中英文混杂。列名一旦确定,后续尽量不要频繁改动。
推荐做法是:
- 使用英文缩写作为字段名。
- 在说明文档中写全称。
- 保持大小写一致。
- 避免空格和特殊符号。
例如可设置为:
- Record_ID
- Obj_A_ID
- Obj_B_ID
- Interaction_Type
- Evidence_Source
- Method
- PMID
- Confidence_Score
这种结构更适合导入分析软件,也是常见的专业互作数据格式 做法。
7.2 用数据字典约束取值
字段设计完成后,还要配套数据字典。数据字典说明每个字段的定义、格式、取值范围和示例。
建议至少写清楚:
- 是否必填。
- 数据类型。
- 单位。
- 允许值。
- 缺失值写法。
没有数据字典,模板只能算表格;有了数据字典,才算规范化数据系统。
8. 增加质控与一致性检查
8.1 上线前先做规则校验
模板做完不代表可以直接用。必须先进行质控,检查重复、缺失、冲突和格式错误。
常见检查点包括:
- ID是否重复。
- PMID是否真实存在。
- 互作对象是否缺失。
- 数值字段是否超范围。
- 枚举值是否统一。
建议在Excel或脚本中设置校验规则。这样能在录入阶段就发现问题,而不是等到投稿或建模时才返工。
8.2 建立抽样复核机制
如果数据量较大,建议采用抽样复核。比如每批随机抽查10%到20%的记录,核对原文和字段一致性。
重点检查:
- 证据是否对应。
- 方法是否正确。
- 结论是否被误读。
- 版本是否更新到最新。
高质量的互作数据格式,不只看模板设计,更看质控是否到位。
9. 用可复用模板提升产出效率
9.1 模板要服务协作
专业模板的最终目标,不是“看起来整齐”,而是能让团队协作更高效。一个好的模板应支持多角色使用:
- 实验人员录入。
- 生信人员分析。
- PI审阅。
- 论文和数据库输出。
建议将模板拆分为主表和辅助表。主表存核心互作信息,辅助表存字典、方法说明和版本记录。这样更易维护,也更适合多人协作。
9.2 借助专业工具减少重复劳动
如果团队长期需要整理互作关系,单靠手工表格效率有限。可考虑使用标准化的数据管理工具,或借助解螺旋这类面向科研场景的品牌服务,快速搭建规范模板、统一字段口径,并减少录入和清洗成本。
把互作数据格式做标准,才能把时间留给真正的分析和验证。 当模板、字段、证据和版本都被统一后,后续论文整理、数据库导出和项目汇报都会更顺畅。
总结Conclusion

互作数据整理的核心,不是把信息堆进表格,而是建立一套可追溯、可验证、可复用的标准体系。围绕场景、对象、字段、证据、版本和质控逐步搭建,才能形成真正专业的互作数据格式 。
如果你希望更快完成标准化模板,减少反复清洗和字段返工,可以直接借助解螺旋品牌的科研数据整理思路和工具支持。把格式先做对,后续分析、发表和协作都会更高效。
- 引言Introduction
- 1. 明确互作数据的使用场景
- 2. 统一核心对象与命名规则
- 3. 设计最小必需字段
- 4. 规定证据类型与实验来源
- 5. 加入互作方向、类型与强度
- 6. 规范时间、版本与更新记录
- 7. 统一文件结构与编码规则
- 8. 增加质控与一致性检查
- 9. 用可复用模板提升产出效率
- 总结Conclusion