引言Introduction
在医学论文、临床研究和数据挖掘中,P 值滥用学术不端 几乎是最常见、也最隐蔽的问题之一。很多人只盯着 P<0.05,却忽略了研究设计、样本量和效应量。结果是,结论看似“显著”,实际却可能不可靠。
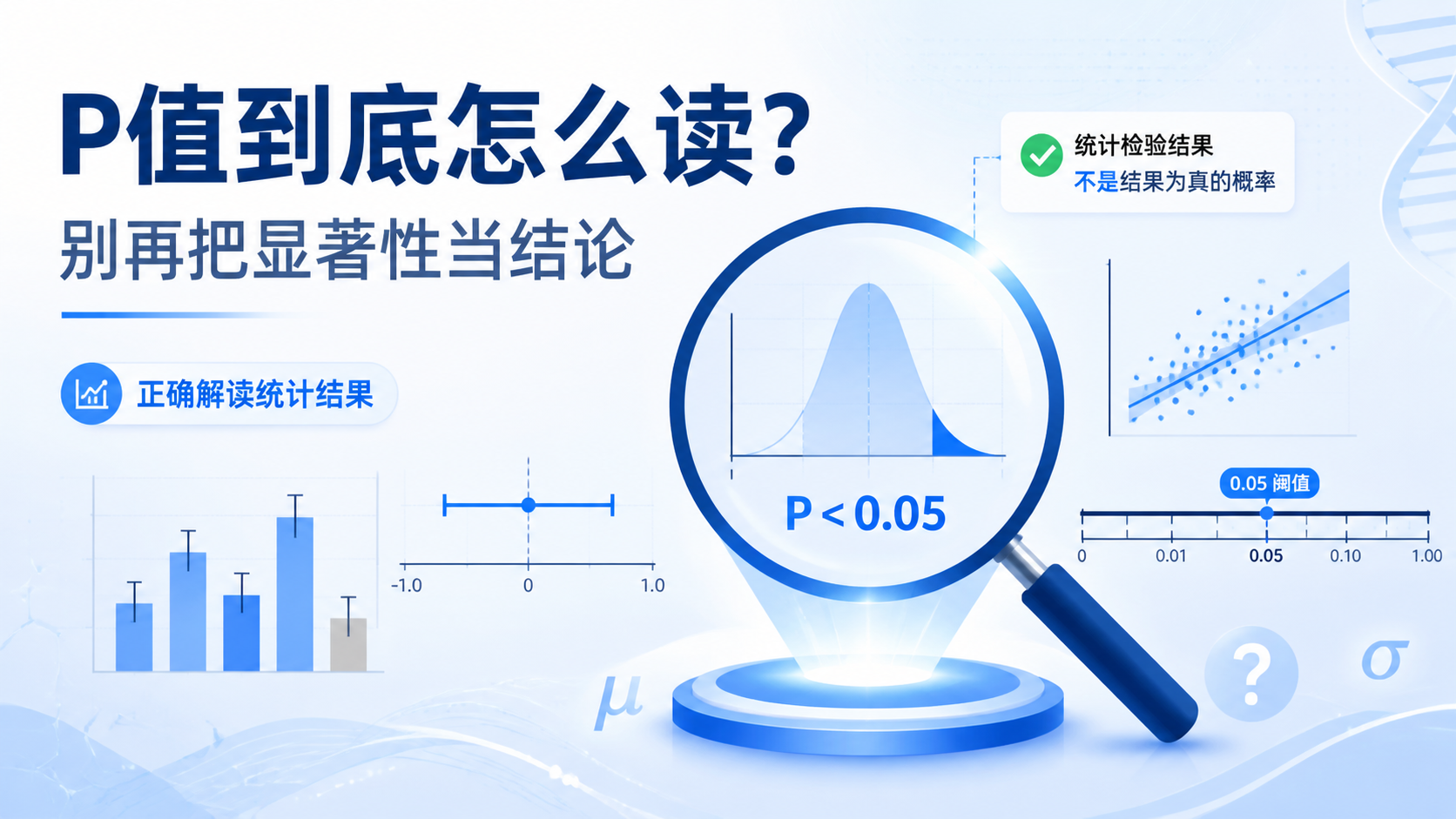
1. 先弄清楚,P值到底在回答什么
1.1 P值不是“假设为真的概率”
P值的核心含义是:在原假设成立的前提下,当前观察结果及更极端结果出现的概率 。它不是“结果为真的概率”,也不是“研究结论正确的概率”。
这一区分很关键。很多误用都来自把 P 值当成了“真实性证明”。实际上,P 值只能帮助我们判断数据与原假设是否相容。它不能单独证明因果关系,也不能直接说明临床获益大小。
1.2 为什么医学研究离不开假设检验
在医学研究里,我们常见的原假设通常是“两组没有差异 ”或“变量之间没有关联 ”。当样本数据出现明显偏离时,就需要通过假设检验来判断这种偏离是否属于小概率事件。
如果 P<0.05,说明在原假设下出现当前结果的概率较低,研究者可考虑拒绝原假设。但这并不等于研究结论绝对正确。 它只意味着,这个结果不太容易用随机波动解释。
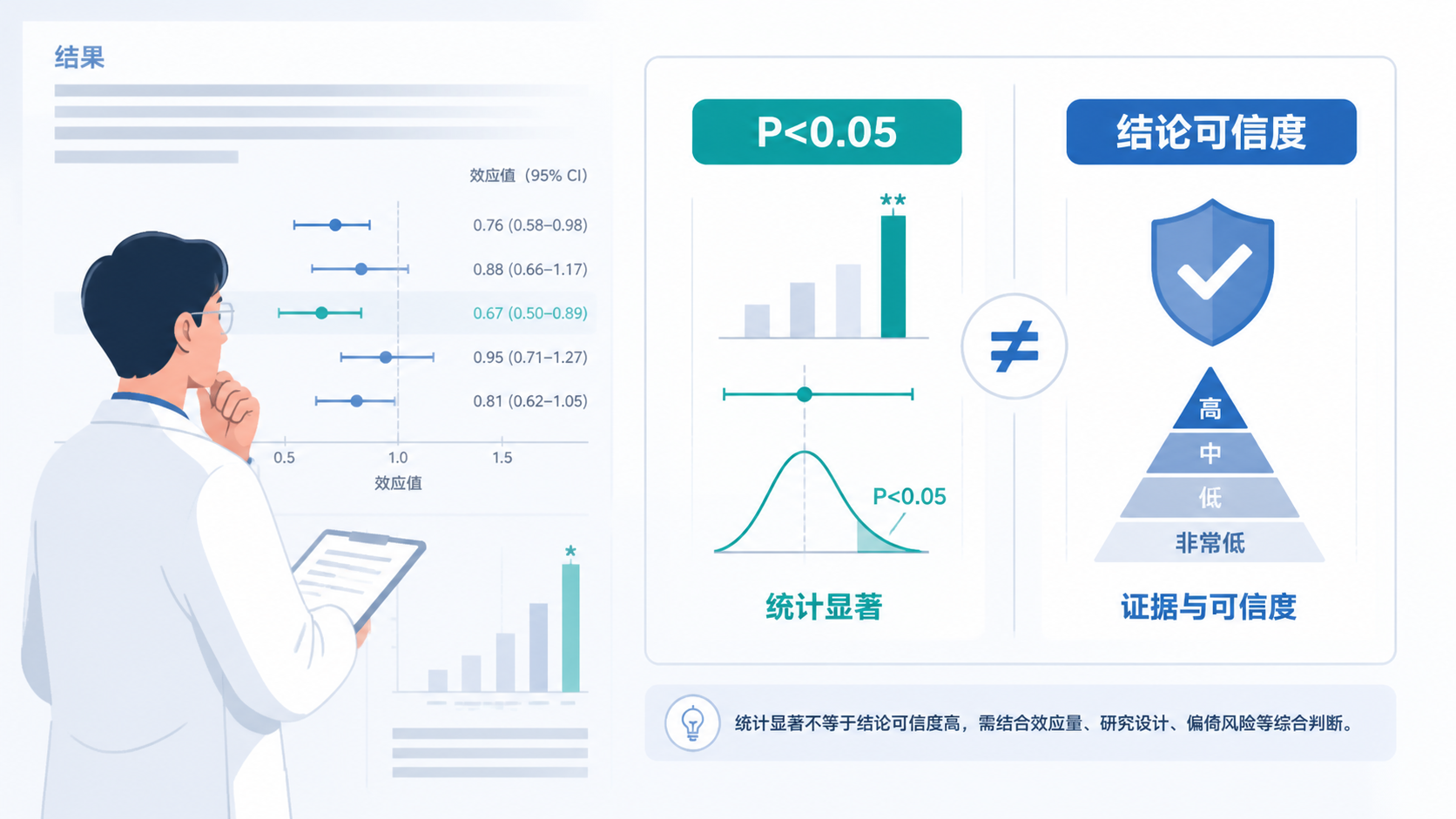
1.3 P值与统计学意义,不等于临床意义
这是最常见的混淆之一。统计学显著,不代表临床上重要。
例如,一个干预能让某指标下降 1%,样本量足够大时,P 值可能非常小。但这个变化是否足以影响预后、治疗方案或患者体验,还要看效应量、置信区间和临床场景。对医学生和科研人员来说,这一步不能省。
2. 警惕P值滥用学术不端:3个致命误区
2.1 误区一:把 P<0.05 当作“真理门槛”
很多论文写作中,作者把 P<0.05 直接等同于“结果成立”。这是一种典型误区。
P 值只是证据强弱的一个指标,不是科学真相的开关。 如果研究存在选择性报告、数据清洗不透明、重复试验后只保留显著结果,那么即使 P<0.05,也可能只是偶然得到的结果。
更严重的是,研究者可能在多个终点、多个分组、多个模型中不断尝试,直到找到一个“显著”的结果。这种做法会显著抬高假阳性风险,是典型的 P 值滥用学术不端 表现之一。
2.2 误区二:只报显著结果,回避不显著结果
不少文章只展示 P<0.05 的变量,把 P≥0.05 的结果完全隐藏。表面上看,文章更“漂亮”,但其实破坏了证据链的完整性。
科研写作强调可重复、可验证。如果只保留显著结果,读者无法判断研究中到底经历了多少筛选。 这不仅削弱可信度,还可能让后续 meta 分析或临床决策建立在偏倚数据上。
建议在结果呈现中至少同时报告:
- 主要终点和次要终点
- 效应量,如均值差、OR、HR
- 95% 置信区间
- 精确 P 值,而不是只写“P<0.05”
这样,读者才能判断结果是否稳定,而不是只看一个阈值。
2.3 误区三:把样本量不足或过度放大当作“显著工具”
小样本研究中,P 值往往不稳定。一次抽样的偶然性很强,容易出现假阴性。反过来,大样本研究中,极小差异也可能获得很小的 P 值。
这意味着,P 值会受到样本量强烈影响。 样本太小,真实差异可能检不出来。样本太大,微小差异也可能被“放大成显著”。如果研究者只追求显著,而不关注实际效应,就容易把统计学结果包装成“突破”。
这类问题在真实世界研究、回顾性队列和多中心数据分析中尤其常见。对科研人员而言,最危险的不是“没有 P 值”,而是“拿 P 值替代科学判断”。
3. 如何减少P值滥用,提升研究可信度
3.1 预先定义假设和主要终点
要避免 P 值滥用,第一步就是在研究开始前明确:
- 主要研究终点是什么
- 次要终点有哪些
- 主要分析方法是什么
- 是否进行多重比较校正
先定规则,再看结果。 这是减少选择性报告的关键。若在结果出来后再决定分析路径,容易把偶然发现误判为可靠证据。
3.2 同时看效应量和置信区间
只看 P 值,信息量太少。更合理的做法是把 P 值放到完整统计框架中看。
建议至少同时关注:
- 效应量大小
- 95% 置信区间是否跨越无效值
- 样本量是否足够
- 结果是否具有生物学或临床解释
例如,两个组别的差异即使 P=0.03,但如果置信区间很宽,说明估计不稳定,结论仍需谨慎。统计学显著,不等于结果稳健。
3.3 正确理解“非显著”并不等于“没有差异”
P≥0.05 不能简单翻译成“没有差异”。它更准确的表达是:当前样本提供的证据不足以证明存在差异。
这一区别在论文写作中非常重要。很多作者把“无统计学意义”直接写成“无差异”,这会过度解读结果。对于样本量不足的研究,真正合理的说法应该更保守。
3.4 在多重检验中控制错误率
如果同一研究中进行了很多次比较,单个检验使用 0.05 作为阈值,会累积假阳性风险。比较越多,偶然显著的机会越大。
因此,在基因组学、组学分析、亚组分析和多终点研究中,应考虑:
- Bonferroni 校正
- FDR 控制
- 预先限定主要比较
越是复杂的数据分析,越不能把 P<0.05 当作唯一标准。
4. 结尾前必须记住的研究底线
4.1 论文写作要对统计结论负责
对于医学生、医生和科研人员来说,统计结果不是“修饰语”,而是证据的一部分。若把 P 值用作包装工具,就会损害论文质量,甚至触碰学术诚信边界。
P 值本身不是学术不端,但对 P 值的选择性使用、过度解读和隐瞒结果,可能构成 P 值滥用学术不端。 这也是审稿人和编辑越来越警惕的原因。
4.2 真正可靠的研究,需要完整证据链
一个可信结论,通常应当同时满足:
- 研究设计合理
- 样本来源清晰
- 统计方法匹配数据类型
- 结果报告完整
- 解释不夸大
如果只剩下一个“显著”的 P 值,研究的说服力其实很弱。对临床研究而言,能指导决策的不是一个数字,而是一整套可复核的证据。
4.3 借助专业工具减少低级错误
从选题、统计分析到论文撰写,规范流程能显著降低 P 值误用风险。对于需要高质量医学写作支持的团队,可以借助解螺旋这类专业科研服务,帮助梳理研究问题、规范统计呈现、优化结果表达,减少因方法不当导致的返工和争议。
总结Conclusion
警惕P值滥用学术不端,本质上是在守住医学研究的可信底线。 P 值只能回答“在原假设下,这个结果有多罕见”,不能替代临床意义、效应量和研究设计。本文总结的 3 个致命误区是:把 P<0.05 当真理、只报显著结果、以及忽视样本量与多重比较带来的偏差。
对医学生、医生和科研人员来说,最重要的不是追逐显著,而是建立完整、透明、可复核的证据链。如果你希望让研究结果更规范、更稳健,也可以借助解螺旋品牌的专业支持,让统计表达回到科学本身。
- 引言Introduction
- 1. 先弄清楚,P值到底在回答什么
- 2. 警惕P值滥用学术不端:3个致命误区
- 3. 如何减少P值滥用,提升研究可信度
- 4. 结尾前必须记住的研究底线
- 总结Conclusion