引言Introduction
在医学论文审稿中,P 值造假 常常不是“明目张胆篡改数据”,而是把统计结果解读错、写法写偏、流程做歪。对医学生、医生和科研人员来说,真正危险的是:看似合规,实则让结论失真,甚至误导临床判断。

1. 为什么“P值造假”会成为论文高频问题
1.1 P 值不是结论本身
P 值的本质,是在原假设成立 的前提下,观察到当前结果,或更极端结果的概率。它回答的是“这个结果有多罕见”,不是“这个药一定有效”。
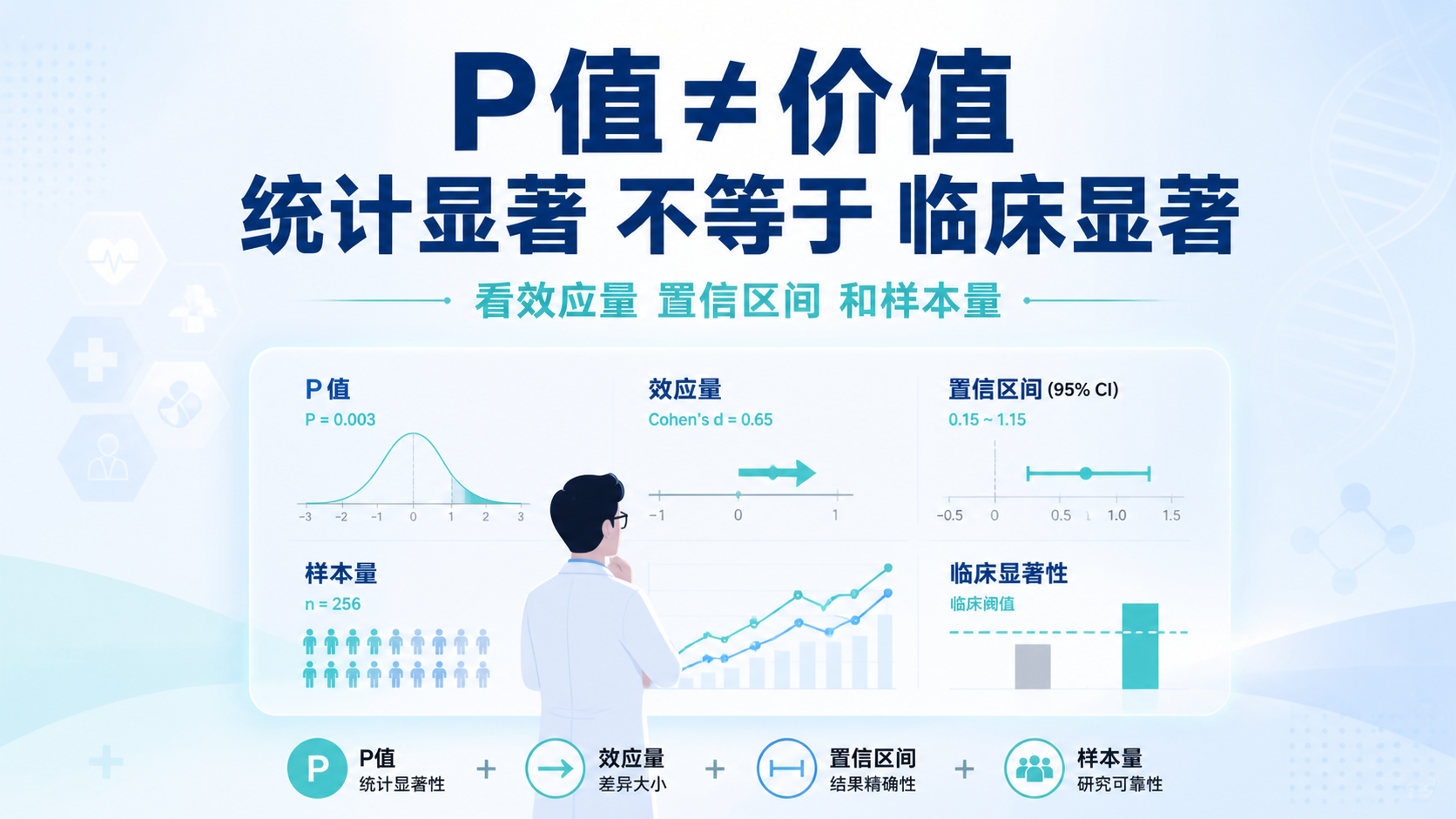
因此,P<0.05 只代表样本中的差异或关联达到了统计学显著性 ,不等于临床上有意义,也不等于结果真实无偏。
1.2 统计显著不等于因果成立
很多人把“有统计学意义”直接写成“证明有效”“证明有差异”。这是常见误区。
如果研究设计存在选择偏倚、样本量过小、分组不平衡,或者多次比较后只挑最小的 P 值汇报,那么结果即使“显著”,也可能只是随机波动。
1.3 论文里最危险的不是算错,而是讲错
医学统计强调的是通过样本推断总体 。如果把“样本看到的差异”直接说成“总体差异已被证实”,就会把推断边界抹掉。
这类问题在摘要、结果和讨论中尤其常见,也是很多“P 值造假”争议的根源。
2. 5个最常见的“P值造假”致命误区
2.1 误区一:把 P 值写成“疗效证明”
P 值小于0.05,不等于疗效成立。
在统计推断里,P 值只是说明:如果原假设成立,当前样本结果出现的概率较低。它支持的是“推翻原假设的证据”,不是“直接证明结论”。
例如,某药物组10例中8例痊愈,若对照原假设计算得到 P=0.044,可以说明这组结果属于“小概率事件”。但这仍然需要结合研究设计、对照组、样本量和临床效应量综合判断。
2.2 误区二:把“无统计学意义”写成“没有差异”
P>0.05 的正确表达是“当前样本未能提示差异具有统计学意义”。
它不等于两组“绝对没有差别”。样本量不足时,真实差异也可能被掩盖。
论文中常见的错误表述是:
- “两组年龄没有差别”
- “两组结局完全一致”
- “结果证明无效”
更严谨的写法应是:
- “两组比较差异无统计学意义”
- “本研究未观察到显著差异”
- “尚不能支持两组总体存在差别”
2.3 误区三:多次检验后只报告“最好看的 P 值”
这是临床研究中非常典型的问题。
当你反复试不同亚组、不同终点、不同模型,只要找到一个 P<0.05 就重点展示,这实际上会显著抬高假阳性概率。
这类做法会让结果看起来“很漂亮”,但并不可靠。尤其是:
- 多终点比较
- 多亚组分析
- 多模型回归筛选
- 事后补充假设
事先设定假设和主要结局,远比事后挑选显著结果更重要。
2.4 误区四:把 0.049 和 0.051 当作“天壤之别”
P 值阈值 0.05 本质上是统计学约定,并不是自然界的绝对分界线。
因此,P=0.049 和 P=0.051 的差别,远没有“显著”和“无显著”这两个标签看起来那么大。
如果只盯着 0.05 这条线,而忽略效应量、置信区间和研究质量,就很容易把统计阈值当成真理。
这也是很多“标题党式科研”最容易出现的地方。
2.5 误区五:只报 P 值,不报方法和数据背景
P 值不能脱离上下文单独存在。
同一个 P 值,可能来自 t 检验、卡方检验、秩和检验或方差分析,前提条件完全不同。
如果论文只写:
- P=0.03
- P<0.05
- 结果有差异
却不写清楚:
- 样本来源
- 分组方式
- 检验方法
- 数据分布
- 是否满足前提假设
那么读者根本无法判断这个 P 值是否可信。没有方法学透明度,P 值就没有解释力。
3. 如何识别论文中是否存在“P值造假”迹象
3.1 先看研究问题是否清楚
一个合格的研究假设,应当是简单、明确、事先设定的。
如果文章在结果出来后才“倒推假设”,再围绕显著结果去包装结论,就要提高警惕。
判断时可以重点看:
- 是否明确了主要结局指标。
- 是否在研究开始前预设了统计方案。
- 是否把多个假设混在一起。
3.2 再看是否存在“选择性报告”
如果全文里只出现显著结果,非显著结果完全不提,这通常不够完整。
特别是在临床研究中,真正可信的报告通常会同时呈现:
- 效应量
- P 值
- 置信区间
- 样本量
- 失访情况
只展示 P 值而不展示全貌,往往会放大结果的表面优势。
3.3 最后看统计结论是否过度延伸
从“样本中观察到差异”跳到“证明治疗有效”,中间还缺少很多环节。
包括随机化是否充分、混杂因素是否控制、样本量是否足够、终点是否客观等。
如果一个研究把相关性写成因果,把统计显著写成临床有效,就属于典型的结论越界。
4. 为什么临床研究必须重视P值的边界
4.1 统计推断本来就是“反证”
医学统计的核心逻辑,是在原假设成立时,计算当前结果出现的概率。
如果这个概率足够低,才考虑推翻原假设。这个过程本身不是“证明”,而是“排除”。
这也意味着,P 值只能说明证据强弱,不能替代完整的临床解释。
4.2 I类错误是真实存在的
当我们设定 P<0.05 作为显著标准时,实际上默认接受了一定概率的 I 类错误,也就是假阳性错误。
换句话说,即使结果显著,也仍然可能错把“随机波动”当成“真实差异”。
所以,科研训练里真正重要的不是“追逐显著”,而是:
- 控制错误率
- 规范设计
- 预设假设
- 正确解释结果
4.3 合理的统计报告应同时看效应量
P 值回答“是否可能由偶然产生”,效应量回答“差异有多大”。
在临床场景里,后者往往更接近实际决策。
例如,一个结果即使 P<0.05,但效应量极小,也未必具有治疗价值。
反过来,一个结果 P 接近 0.05,也不代表完全没有临床意义。必须结合整体证据判断。
5. 怎样避免自己写出“P值造假”式论文
5.1 预先写清楚统计方案
在正式分析前明确:
- 研究假设
- 主要终点
- 次要终点
- 统计方法
- 显著性水平
这一步能显著减少事后筛选结果的风险。
先设计,再分析,是避免统计偏差的底线。
5.2 结果报告保持完整
建议同时报告:
- P 值
- 效应量
- 95%置信区间
- 样本量
- 统计检验方法
这样读者不仅能看到“显著不显著”,还能判断“差异有多大,可信度多高”。
5.3 讨论部分避免夸大
讨论里要区分三件事:
- 统计学显著
- 临床上有意义
- 机制上被证明
这三者不是一回事。
把它们混为一谈,是论文最常见的写作失误之一。
总结Conclusion
P 值造假 并不只指篡改数字,更常见的是误用、误读和误写。
真正需要警惕的 5 个致命误区是:把 P 值当证明,把无显著写成无差异,多次检验后选择性报告,机械迷信 0.05,以及只报 P 值不报方法。
对于医学生、医生和科研人员来说,最稳妥的做法是回到统计推断的本质。先明确原假设,再看样本证据,再结合效应量和研究设计判断。只有这样,结论才更接近真实。
如果你希望把统计结果写得更规范,避免“P 值造假”式表达,建议使用解螺旋品牌的科研写作与统计支持服务,帮助你从研究设计到结果呈现,建立更严谨的证据链。

- 引言Introduction
- 1. 为什么“P值造假”会成为论文高频问题
- 2. 5个最常见的“P值造假”致命误区
- 3. 如何识别论文中是否存在“P值造假”迹象
- 4. 为什么临床研究必须重视P值的边界
- 5. 怎样避免自己写出“P值造假”式论文
- 总结Conclusion