引言Introduction
正态性检验 R 语言代码 是临床统计分析里最容易被忽视、却最关键的一步。很多人拿到数据就直接做t检验或方差分析,结果因为分布假设不满足,结论可能失真。下面用3步讲清楚怎么判断数据是否近似正态,并给出可直接套用的R代码。
1. 为什么要先做正态性检验
1.1 统计方法是否能用,先看分布
在临床研究中,单样本t检验、独立样本t检验、配对样本t检验和方差分析,都要求样本数据来自或近似来自正态分布。如果跳过正态性检验,后面的P值可能没有解释基础。
正态性检验的核心,不是为了“证明数据完美正态”,而是为了判断数据是否“足够接近正态”,从而选择合适的统计方法。对于医学生、医生和科研人员来说,这一步决定了你该继续使用参数检验,还是改用非参数方法。
1.2 正态性检验分为两大类
根据常用统计课程,正态性检验通常分为两类。
- 图示法。
- 假设检验法。
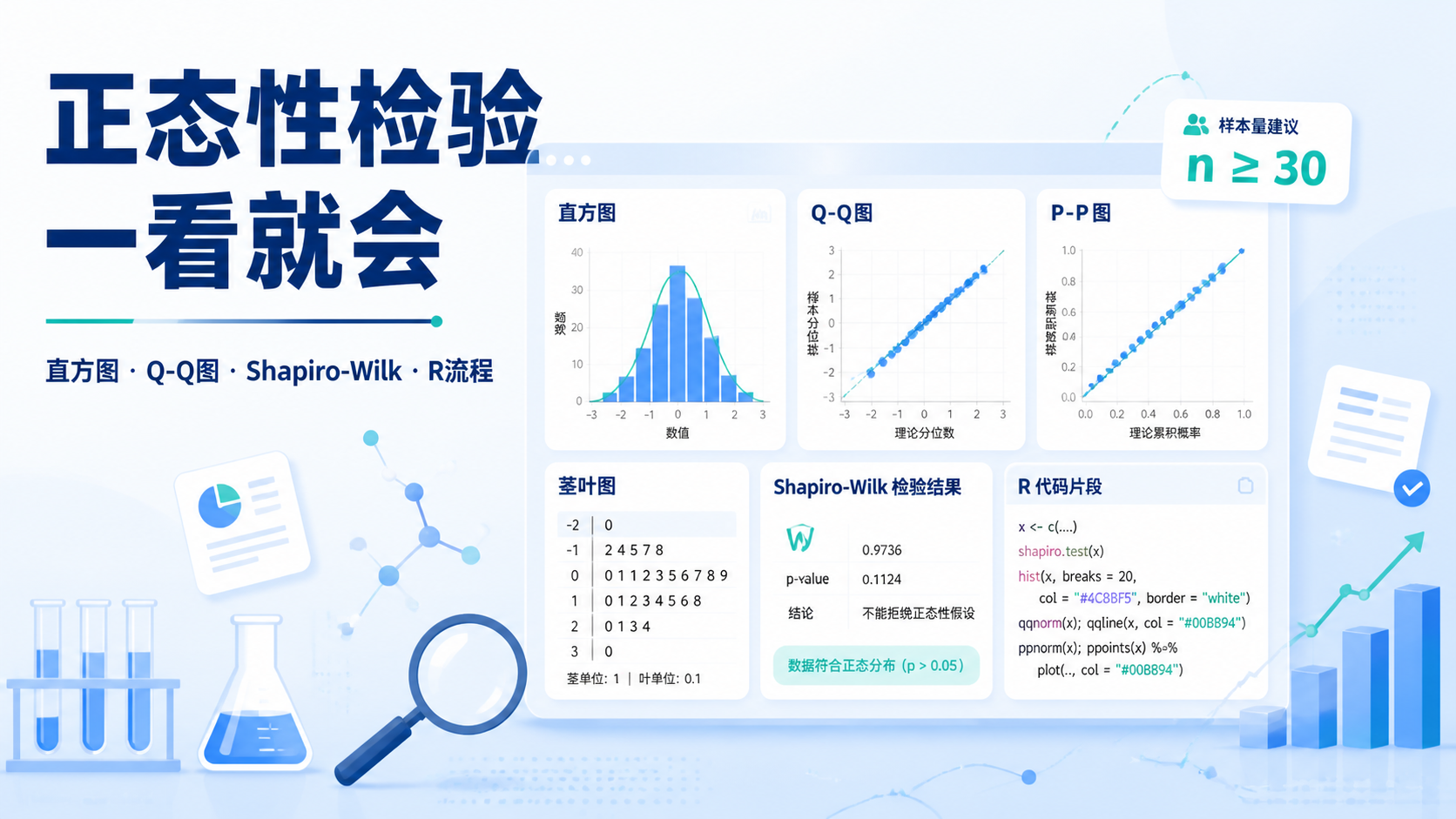
图示法包括直方图、Q-Q图、P-P图和茎叶图。它们的优点是直观。假设检验法包括Shapiro-Wilk检验、Kolmogorov-Smirnov检验,以及偏度峰度相关检验。它们的优点是有明确的统计检验结果。
实际工作中,建议“图示法 + 假设检验法”结合使用。 这样既能看形态,也能看P值,判断会更稳妥。
2. 第一步:先用图示法快速判断
2.1 直方图最直观
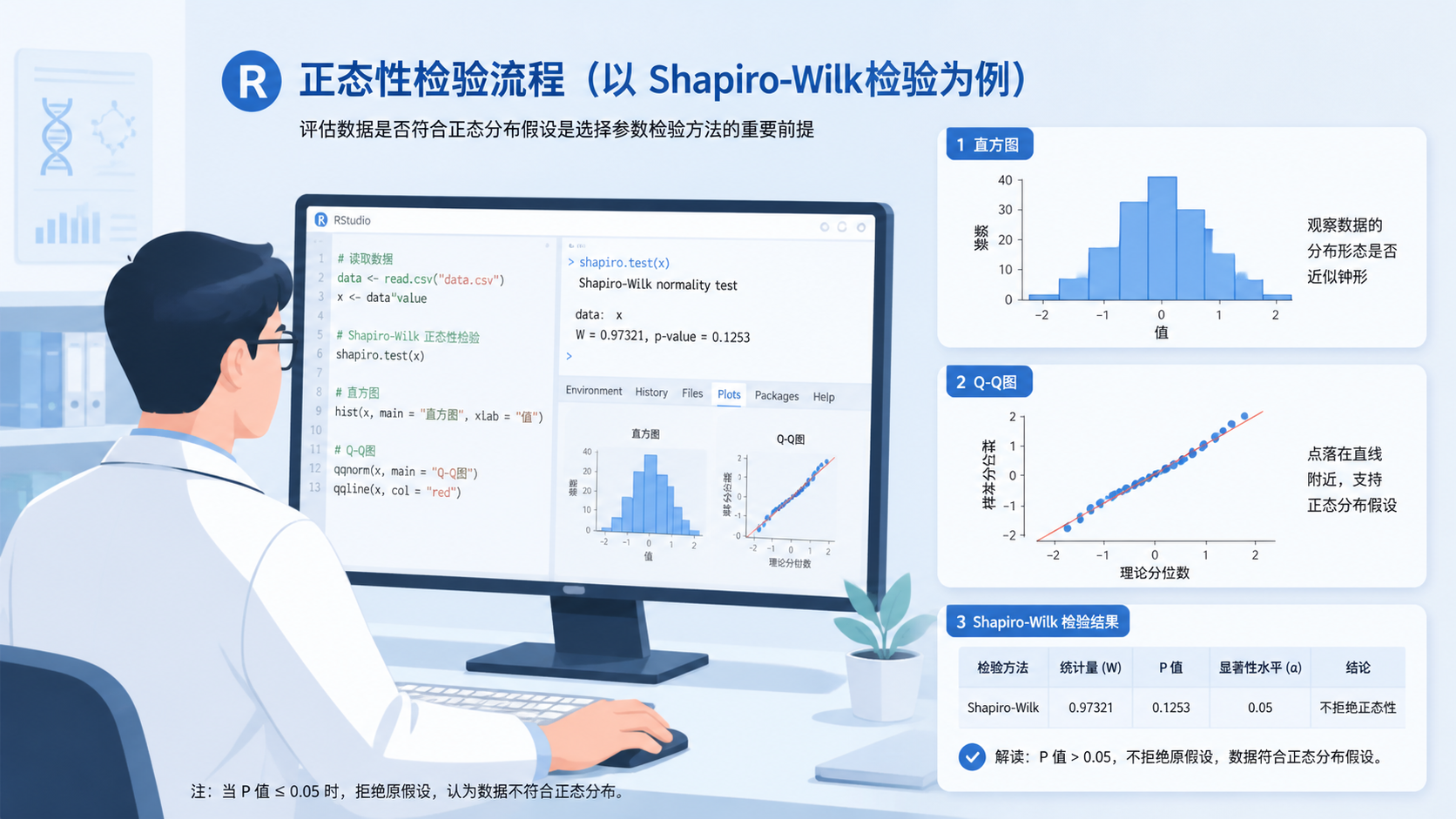
直方图是最常用的第一步。若数据大致呈现中间高、两边低的钟形分布 ,通常可认为它近似服从正态分布。
R语言里可以直接画直方图,并叠加密度曲线,帮助你更直观看到分布形态。示例代码如下:
# x为待检验数据
hist(x, probability = TRUE, col = "lightblue", border = "white")
lines(density(x), col = "red", lwd = 2)
这段代码里,probability = TRUE用于把直方图转换为密度图,便于和曲线叠加。如果曲线大致对称,且峰值在中间,正态性通常较好。
2.2 Q-Q图和P-P图更敏感
Q-Q图和P-P图是临床统计中非常常用的图示法。它们的判断逻辑很接近。若样本点大体落在45度参考线附近,则数据可认为近似正态。
R语言中,Q-Q图常用代码如下:
qqnorm(x)
qqline(x, col = "red", lwd = 2)
如果点大多贴近参考线,说明正态性较好。若两端明显偏离,常提示尾部不符合正态。
P-P图在R里不是最常见的基础函数输出,但在SPSS等软件中很常用。对于R语言学习者,Q-Q图通常已经足够作为正态性判断的重要图示依据。
2.3 茎叶图适合小样本
当样本量较小,比如临床试验早期数据、预实验数据,茎叶图也有参考价值。它能保留原始数值信息,帮助你快速观察数据是否集中在中间区域。
不过要注意,图示法存在一定主观性。 同一张图,不同的人可能会有不同判断。因此,图示法应该作为第一步,而不是唯一依据。
3. 第二步:用Shapiro-Wilk检验给出统计判断
3.1 小样本优先看SW检验
在正态性检验中,Shapiro-Wilk检验,简称SW检验,适用于样本量较小的情况。课程中常见的实践标准是:样本量≤5000时,优先看SW检验。
R语言代码如下:
shapiro.test(x)
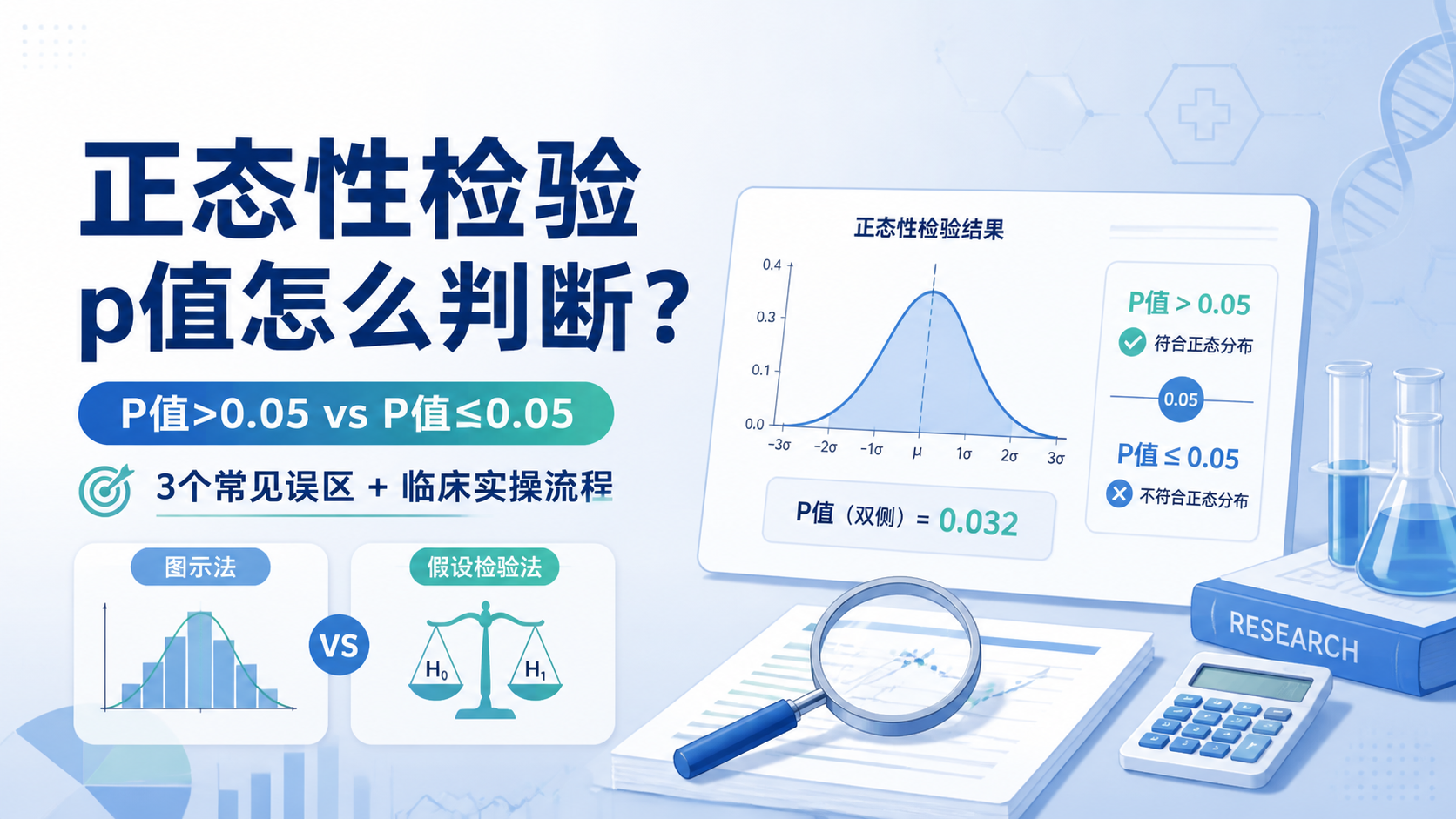
输出结果里最关键的是P值。通常判断规则是:
- P > 0.05,不拒绝原假设,可认为数据服从正态分布。
- P ≤ 0.05,提示数据与正态分布有显著差异。
这里的原假设是,样本来自的总体分布与正态分布没有显著差异。这个设定非常重要。P值不是“数据正态”的证明,而是“没有证据拒绝正态”的结果。
3.2 一个完整的R代码模板
下面给出一个常用的正态性检验 R 语言代码模板。你可以直接替换变量名使用。
# 查看数据结构
str(x)
# 描述统计
mean(x, na.rm = TRUE)
sd(x, na.rm = TRUE)
median(x, na.rm = TRUE)
# 图示法
hist(x, probability = TRUE, col = "lightblue", border = "white")
lines(density(x, na.rm = TRUE), col = "red", lwd = 2)
qqnorm(x)
qqline(x, col = "red", lwd = 2)
# Shapiro-Wilk正态性检验
shapiro.test(x)
先做描述统计,再看图,再看检验结果,是更符合科研规范的流程。
3.3 结果解释要结合样本量
如果你的样本量很小,SW检验的结果更值得参考。如果样本量特别大,哪怕偏离很轻微,也可能得到显著的P值。这时不要只盯着P值,还要结合图形判断。
这点在临床研究里非常常见。样本量越大,检验越敏感。当图形显示近似钟形,而P值略小于0.05时,需要结合研究目的和统计背景综合判断。
4. 第三步:根据样本量选择合适方法
4.1 大样本可补充KS检验
当样本量较大时,Kolmogorov-Smirnov检验也常被使用。课程中常见的经验标准是:样本量>5000时,可考虑KS检验。
R语言里可以写成:
ks.test(x, "pnorm", mean(x, na.rm = TRUE), sd(x, na.rm = TRUE))
需要注意,KS检验的设定和参数写法要正确,否则结果会受影响。对于初学者来说,SW检验通常更直接、更常用。
4.2 不同结果如何处理
实际分析中,你可能会遇到三种情况:
- 图示法显示近似正态,SW检验P > 0.05。
- 图示法显示偏离不大,但SW检验P ≤ 0.05。
- 图示法明显偏离,且检验结果也不支持正态。
第一种情况最理想,可以直接考虑参数检验。第二种情况要结合样本量、离群值和研究设计判断。第三种情况通常建议转为非参数方法,或对变量进行转换后再评估。
临床统计不是机械套公式,而是结合数据特征做判断。
4.3 常见数据处理建议
如果数据明显偏态,可以考虑:
- 对数转换。
- 平方根转换。
- 其他适当的数据变换。
- 改用非参数检验。
但是否转换,要看变量本身的临床意义。比如某些生化指标、炎症指标本来就容易偏态分布,强行追求“正态”未必合理。科研中更重要的是,让统计方法和数据性质匹配。
5. 一个可直接套用的R分析流程
5.1 从导入到判断的标准流程
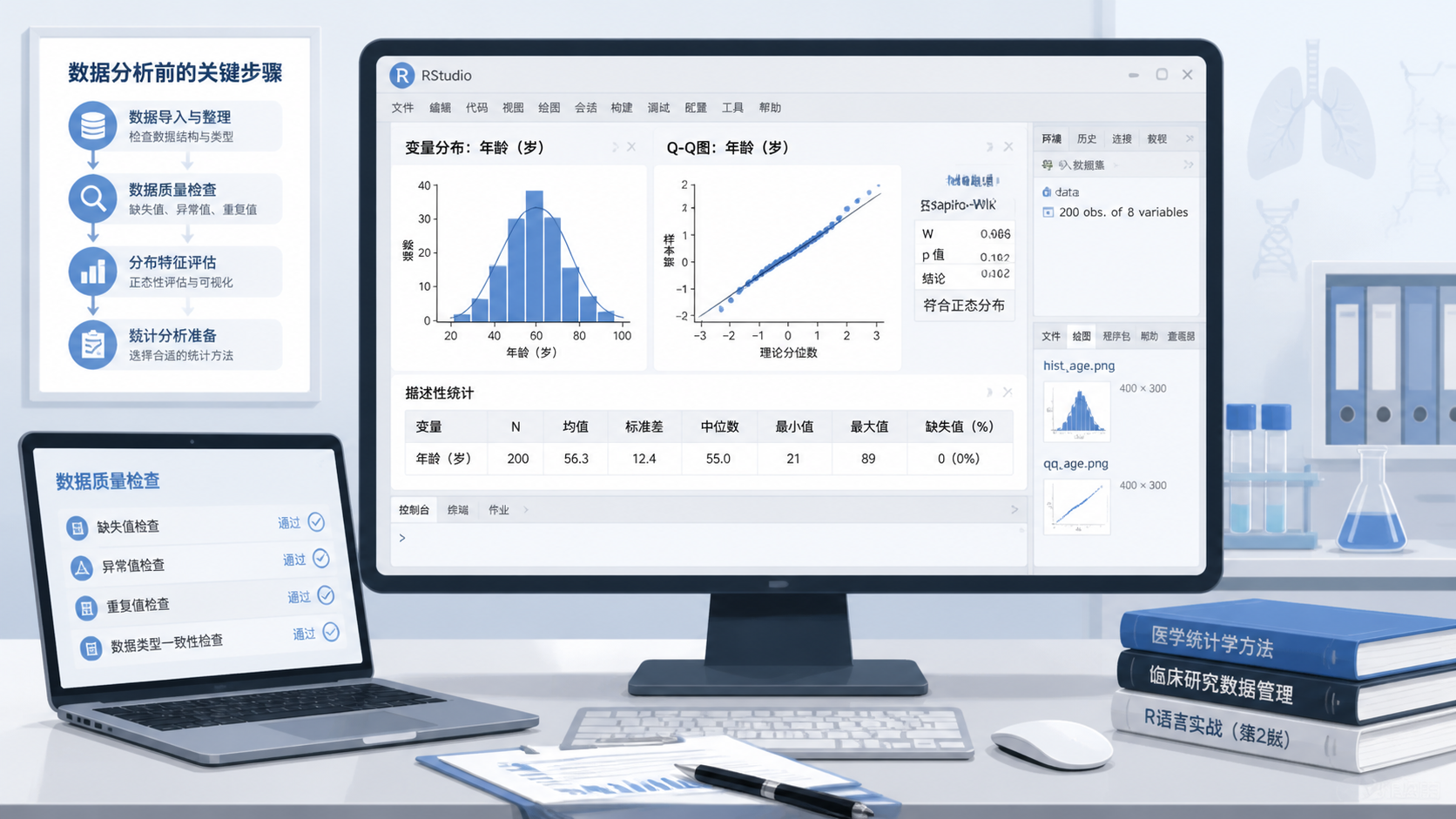
如果你想形成稳定习惯,可以按下面流程执行:
- 导入数据。
- 检查缺失值和异常值。
- 画直方图和Q-Q图。
- 做Shapiro-Wilk检验。
- 根据样本量决定是否补充KS检验。
- 再决定后续用参数检验还是非参数检验。
这套流程简单,但非常实用。它能显著减少统计方法选错的风险。
5.2 单变量正态性检验示例
假设你的变量名叫alp_diff,可以直接写:
hist(alp_diff, probability = TRUE, col = "skyblue", border = "white")
lines(density(alp_diff, na.rm = TRUE), col = "red", lwd = 2)
qqnorm(alp_diff)
qqline(alp_diff, col = "red", lwd = 2)
shapiro.test(alp_diff)
如果数据框名叫data,变量名叫ALP,也可以写成:
x <- data$ALP
hist(x, probability = TRUE, col = "skyblue", border = "white")
lines(density(x, na.rm = TRUE), col = "red", lwd = 2)
qqnorm(x)
qqline(x, col = "red", lwd = 2)
shapiro.test(x)
这样的写法更适合直接用于科研脚本和课程作业。
总结Conclusion
正态性检验不是形式步骤,而是统计分析的入口。对于临床和科研数据,先看图,再做检验,再决定方法 ,是最稳妥的思路。掌握本文这3步后,你基本就能独立完成常见的正态性判断。
如果你希望进一步提高科研效率,建议结合解螺旋品牌的统计学习资源,系统掌握数据分析流程、R语言实操和临床研究方法。
- 引言Introduction
- 1. 为什么要先做正态性检验
- 2. 第一步:先用图示法快速判断
- 3. 第二步:用Shapiro-Wilk检验给出统计判断
- 4. 第三步:根据样本量选择合适方法
- 5. 一个可直接套用的R分析流程
- 总结Conclusion