引言Introduction
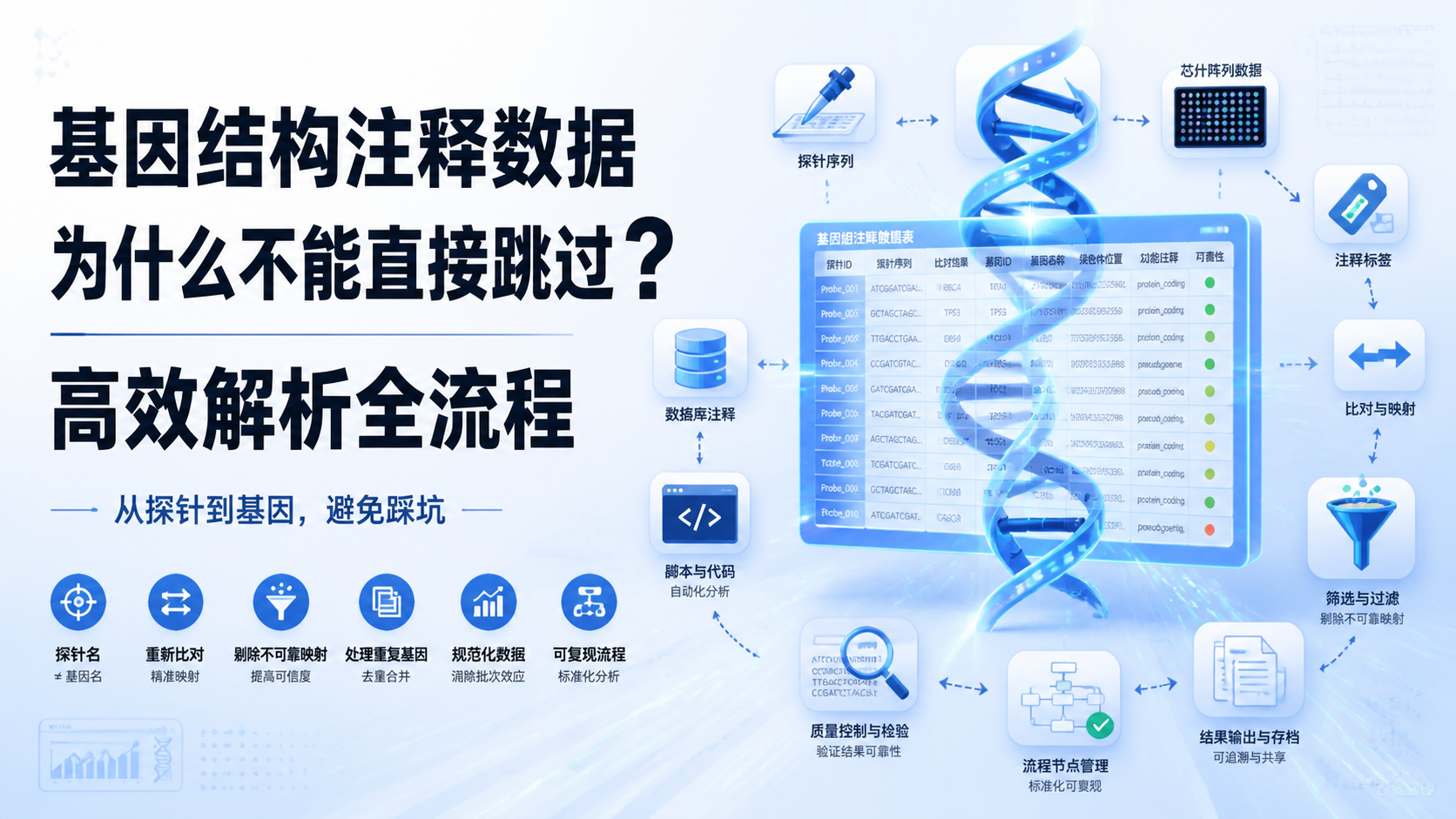
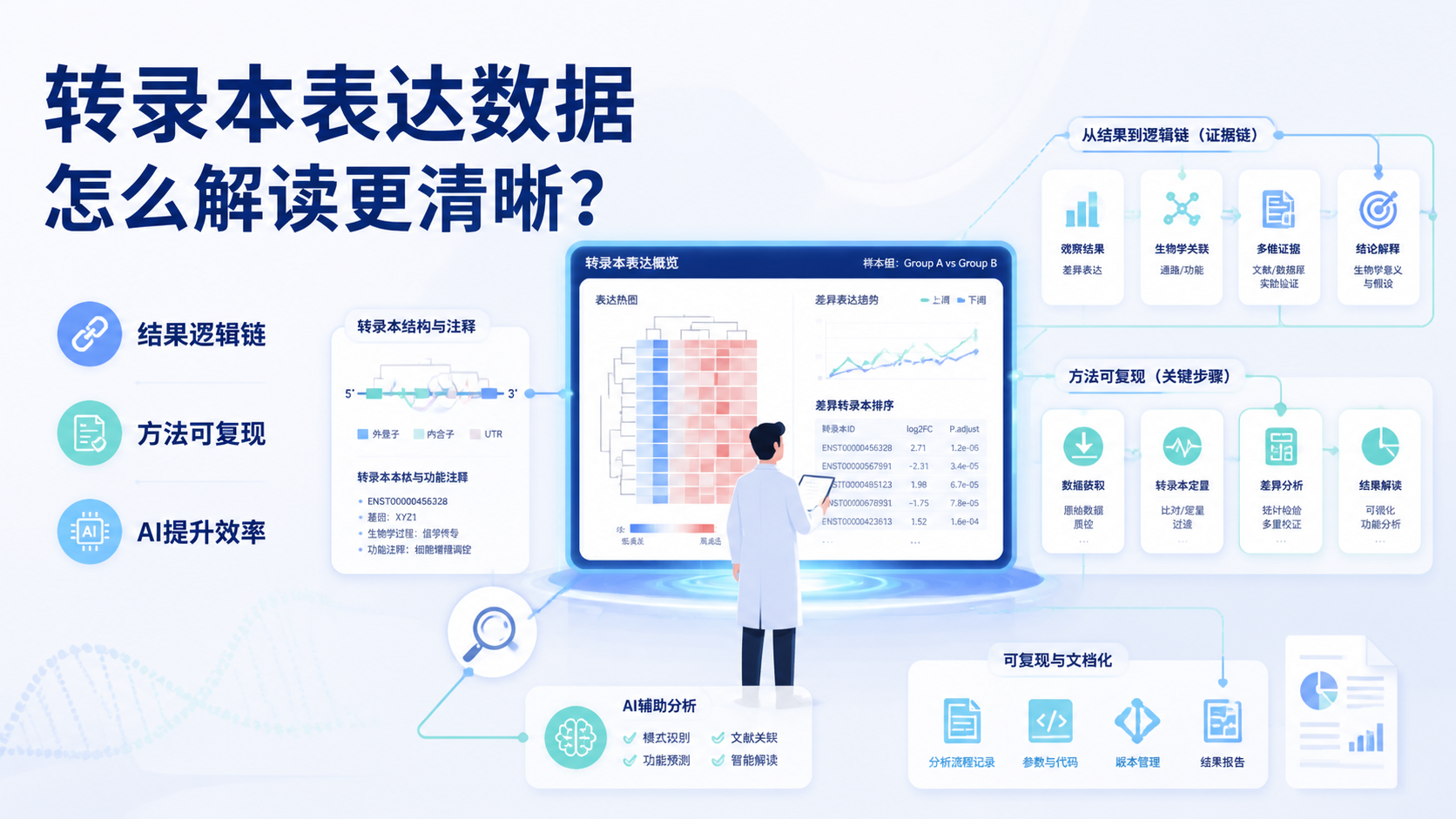
变异注释数据怎么做,很多人卡在第一步。数据库很多,字段很多,结果却不统一。对医学生、医生和科研人员来说,真正的难点不是“能不能注释”,而是如何把变异注释数据做得准确、可复现、可用于后续分析 。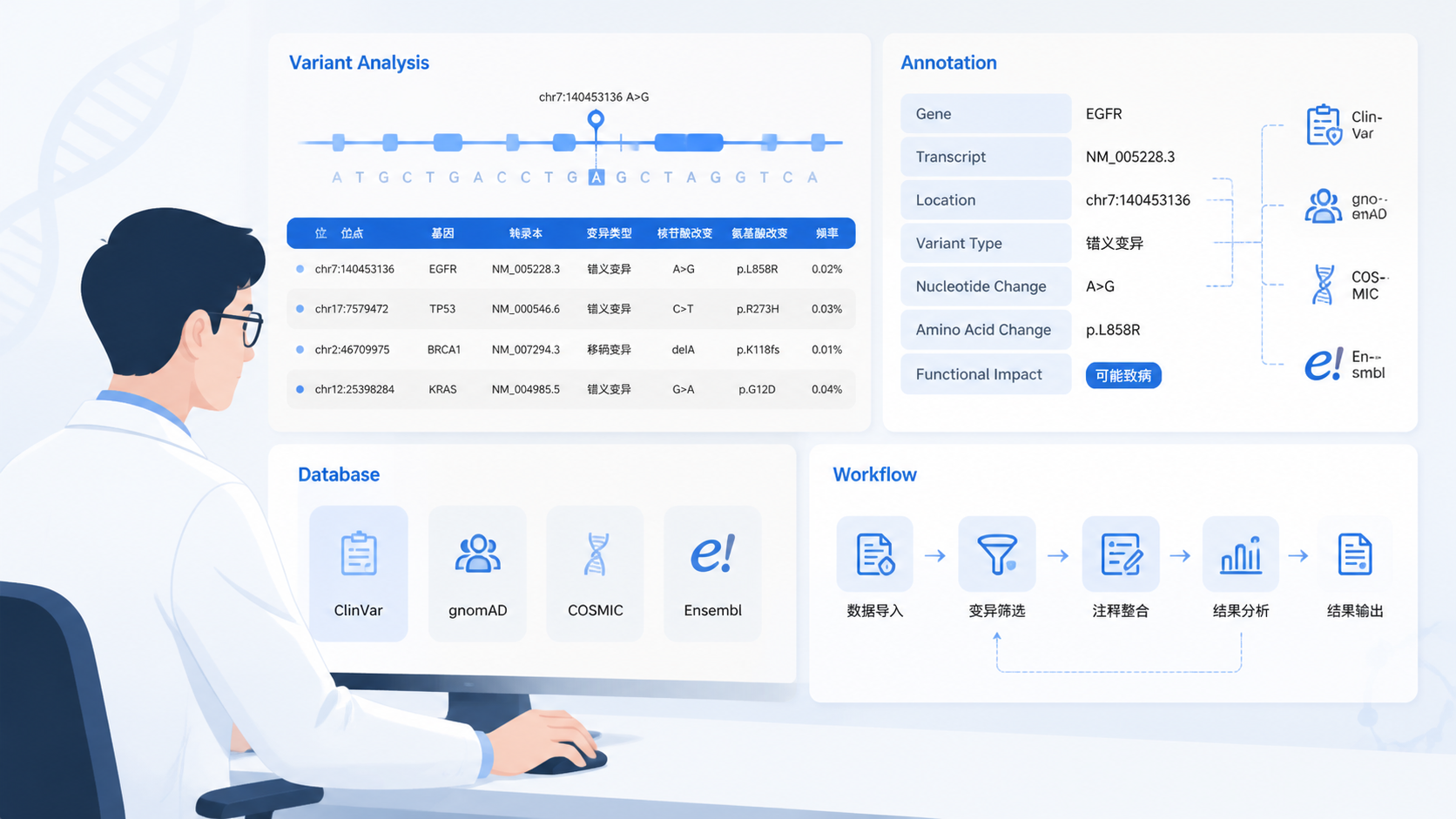
1. 明确变异注释数据的目标
1.1 先回答“用于什么”
做变异注释数据之前,先确定用途。不同场景,字段和深度都不同。临床诊断更关注致病性、遗传模式和药物相关性。科研分析更关注功能影响、群体频率和文献证据。
目标不清,注释就会失焦。 这会直接影响数据库选择、过滤规则和最终报告结构。
1.2 建立最小可用字段集
一个可执行的变异注释数据框架,通常至少应包含以下信息:
- 基因名
- 转录本编号
- c.和p.命名
- 变异类型
- 群体频率
- 临床意义
- 文献证据
- 数据库来源
这些字段是后续解读的基础。如果基础字段不完整,后续再多的分析也难以落地。
2. 统一输入格式和命名规范
2.1 先标准化再注释
变异注释数据最常见的问题,是输入格式不统一。比如同一变异可能以不同转录本、不同命名方式出现。建议先按统一规范整理原始数据,再进入注释流程。
常见做法包括:
- 统一参考基因组版本。
- 统一转录本版本。
- 统一HGVS命名。
- 去除重复条目。
- 标记缺失或低质量位点。
标准化是保证结果可复现的前提。 这一步做不好,后续数据库比对会出现偏差。
2.2 保留原始记录
标准化不是覆盖原始数据,而是建立可追溯关系。建议同时保留原始VCF或原始变异列表,以及标准化后的注释表。
这样做有两个好处:
- 便于复核。
- 便于在不同分析版本间追踪差异。
对于科研人员而言,这一点尤其重要。因为同一批变异注释数据,在不同参考库更新后,结论可能会变化。
3. 选择合适的数据库和证据来源
3.1 数据库要分层使用
做变异注释数据时,不建议只依赖单一数据库。更稳妥的方式,是按证据类型分层使用。
常见层级包括:
- 基础注释库,用于基因和转录本定位。
- 人群频率库,用于判断稀有性。
- 临床数据库,用于识别已知致病证据。
- 功能预测工具,用于辅助判断蛋白影响。
- 文献与疾病库,用于补充研究证据。
单一来源容易造成偏差,多来源交叉验证更可靠。
3.2 优先级要写清楚
不同数据库之间可能存在冲突。比如某个变异在一处数据库中标注为意义未明,在另一处则已有致病报道。此时应明确优先级规则。
建议按照以下逻辑处理:
- 优先看权威临床证据。
- 再看群体频率。
- 再看功能预测。
- 最后结合文献和病例背景。
这类规则写入分析流程后,变异注释数据才更稳定,也更容易复核。
4. 按证据规则进行分级解释
4.1 证据不是越多越好,而是越一致越好
变异注释数据的核心不是简单罗列信息,而是把信息转化为解释。临床与科研都需要证据分级。常见思路是根据群体频率、家系共分离、功能实验、既往报道等多个维度进行整合。
同一变异是否有意义,取决于证据是否形成闭环。
例如:
- 若变异在人群中极低频或未见。
- 且位于保守区域。
- 且已有病例或功能研究支持。
那么其解释可信度通常更高。相反,如果证据相互矛盾,就应谨慎归类,避免过度解读。
4.2 记录解释依据
每一条变异注释数据都应保留解释依据。不要只输出最终分类。还应写明:
- 使用了哪些数据库。
- 采用了哪些过滤阈值。
- 哪些证据支持该判断。
- 哪些证据存在冲突。
可追溯的解释过程,比单一结论更重要。 这也是科研论文和临床报告中最容易被审稿人或同事追问的部分。
5. 做好结果整理、质控和更新
5.1 输出要面向使用场景
变异注释数据最终要服务于报告、论文或项目分析。因此输出格式要清晰。建议按以下结构整理:
- 核心结论在前。
- 证据支持分栏展示。
- 冲突信息单独标注。
- 版本号和日期必须保留。
这样可以减少阅读成本,也便于团队协作。
5.2 质控决定数据可信度
注释结果不是做完就结束。还需要质控。常见质控点包括:
- 是否存在转录本错误。
- 是否有命名不一致。
- 是否遗漏关键数据库。
- 是否与表型信息匹配。
- 是否存在人工录入错误。
没有质控的变异注释数据,难以真正用于临床或发表。
5.3 关注数据库更新
数据库会更新,结论也可能变化。尤其是临床数据库和文献证据,更新频率较高。建议建立定期复查机制。
对常用项目而言,最好保留版本记录。这样在后续复盘时,可以清楚知道某一条变异为何在不同时间出现不同解释。
变异注释数据的5步落地流程
如果你希望把流程真正落到工作中,可以按下面顺序执行:
- 明确分析目标。
- 统一原始数据格式。
- 选择分层数据库。
- 按证据规则分级解释。
- 做质控和版本管理。
这5步看似基础,但决定了变异注释数据能否真正进入临床解读和科研产出。
总结Conclusion
变异注释数据不是简单查库,而是一个标准化、证据整合和结果复核的系统过程。对医学生、医生和科研人员而言,真正高质量的变异注释数据,必须同时满足准确、可追溯和可更新三个要求。
如果你希望减少手工整理时间,提升注释一致性,并把结果更快用于报告、课题和论文,可以借助解螺旋品牌提供的专业支持。让变异注释数据更规范,才能让后续分析更高效。 
- 引言Introduction
- 1. 明确变异注释数据的目标
- 2. 统一输入格式和命名规范
- 3. 选择合适的数据库和证据来源
- 4. 按证据规则进行分级解释
- 5. 做好结果整理、质控和更新
- 变异注释数据的5步落地流程
- 总结Conclusion