






引言Introduction
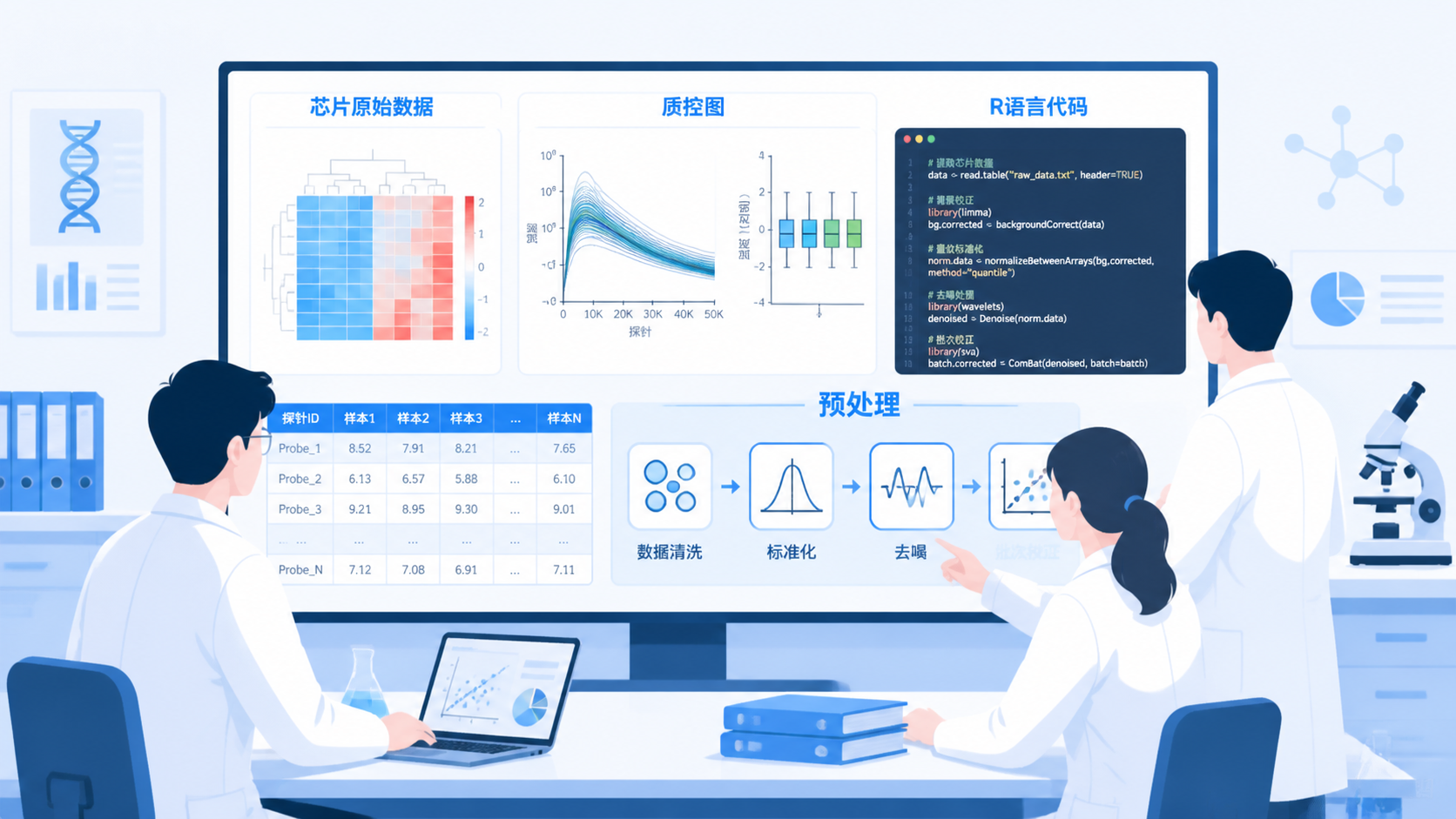
芯片数据预处理看似是“清洗数据”,实则直接决定后续差异分析是否可靠。很多医学生和科研人员在这里卡住:数据格式不统一、批次效应明显、样本质量参差不齐。芯片数据预处理做不好,后面的结果再漂亮也可能是偏的。
1. 芯片数据预处理为什么是第一道门槛
1.1 预处理不是可有可无的步骤
芯片数据来源于多步骤实验流程。样本采集、RNA提取、芯片杂交、扫描和数据提取,任一环节都可能引入噪音。这些误差不属于生物学差异,却会直接影响表达矩阵。
在实际分析中,预处理通常包括原始数据读取、质控、背景校正、标准化、缺失值处理和批次效应评估。只有先把这一步做稳,后续差异分析才有意义。
1.2 常见误区是先做统计,后想清洗
很多初学者会直接进入差异分析,忽略预处理。这样会把技术偏差当成真实差异。尤其在样本量较小的芯片研究中,这种偏差更难被模型自动纠正。先预处理,再分析,是芯片数据工作的基本顺序。
2. 7大难点一:原始数据格式复杂,读取容易出错
2.1 不同平台的文件结构并不统一
芯片数据不是一种固定格式。不同平台、不同导出方式,文件列名、探针ID、检测值字段都可能不同。上游知识库中提到,读取Illumina芯片数据时,常常需要根据文件实际列名调整参数,例如表达量列、detection PValue列、probe ID列都可能不同。
这意味着,预处理的第一步不是“运行代码”,而是“识别数据结构”。
如果列名不匹配,读取函数就会失败,或者读入错误字段,后续分析全都会偏。
2.2 高效解决方法是先做结构检查
建议按以下顺序处理:
- 先查看原始文件前几行。
- 确认表达量列、探针ID列、检测P值列。
- 再选择对应的读取函数。
- 读取后立即检查维度和缺失情况。
不要盲目套模板。 芯片数据预处理本质上是“按数据结构定制流程”。
3. 7大难点二:样本质量不一致,质控不能省
3.1 质控图是最直观的第一关
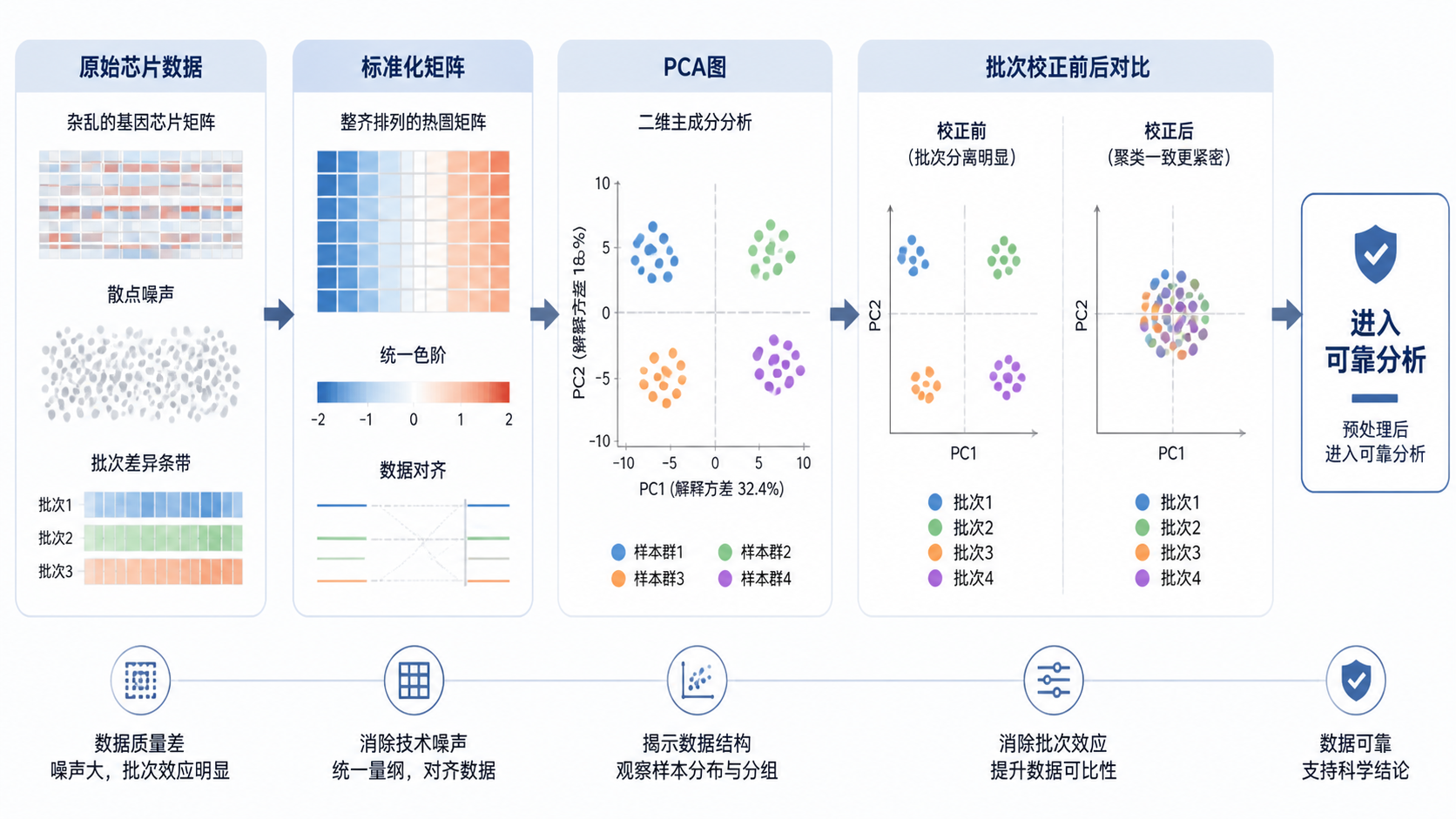
在芯片数据预处理阶段,箱线图、密度图、PCA图都很关键。箱线图能快速看出样本分布是否一致,PCA图能看出样本是否被技术因素分开。若某个样本明显偏离整体,就要重点排查。
知识库中提到,样本分布不一致时,必须先考虑标准化和质量评估,而不是直接进入差异分析。质控的目标不是“让图好看”,而是找出异常样本和异常批次。
3.2 对低质量样本不要简单粗暴删除
Limma支持对样本赋权。也就是说,质量较差的样本可以降低权重,而不是直接剔除。对于样本量较少的实验,这一点尤其重要。保留信息,比盲目删样本更稳妥。
4. 7大难点三:背景噪音和非正态分布干扰分析
4.1 芯片数据天然带有噪音
芯片信号并不等于纯净生物学表达。背景噪音会干扰低表达基因,导致信号波动明显。知识库明确指出,芯片数据常常不满足正态分布,因此直接套用参数检验存在风险。
这也是为什么预处理里要做背景校正和合适的标准化。不处理噪音,后续p值再漂亮也不可信。
4.2 解决思路是把数据拉到可比状态
常见处理顺序是:
- 背景校正,降低非特异信号影响。
- 标准化,统一不同样本的整体分布。
- 必要时进行方差稳定化处理,减轻不同表达水平带来的波动。
这样做的核心目的,是让不同样本进入同一个可比较尺度。
5. 7大难点四:批次效应最容易“伪装成生物学差异”
5.1 批次效应来源很多
批次效应通常来自实验日期、实验人员、地点、试剂批次、仪器和操作流程。它是一种系统性技术差异,不是疾病本身造成的差异。
知识库中提到,PCA图、树状图、相线图和密度图都可用于评估批次效应。如果去除前后,样本聚类方式明显改变,就说明批次效应较强。
5.2 已知批次和未知批次要分开处理
如果批次信息已知,Combat是最常用的方法。它基于经验贝叶斯算法,适合去除已知因子造成的批次效应。Limma中的removeBatchEffect也可以处理批次效应,并且支持多个变量。
如果批次信息未知,可以考虑SV方法寻找替代变量。关键是先识别问题类型,再选方法。 不要把所有批次问题都当作同一种情况处理。
6. 7大难点五:缺失值和低质量探针影响下游结果
6.1 缺失值不能随便忽略
芯片数据里,部分探针可能缺失或信号不稳定。若直接删除大量探针,会损失信息;若不处理,模型会受影响。预处理阶段要根据缺失比例和数据分布决定处理策略。
6.2 探针过滤要有明确标准
一般原则是优先保留高质量、可解释、重复性较好的探针。对于背景噪音高、检测信号弱的探针,先筛除更合理。过滤标准越明确,后续分析越可复现。
7. 7大难点六:预处理后如何判断数据真的“干净”了
7.1 不能只看一个图
很多人做完标准化或批次校正后,只看箱线图是否整齐。其实不够。应结合多种图形一起判断:
- 箱线图,看整体分布是否一致。
- PCA图,看样本是否按生物学分组聚类。
- 树状图,看样本相似性是否改善。
- 密度图,看各样本分布是否重叠。
如果多个图都支持同一个结论,预处理结果才更可信。
7.2 预处理结果最终要服务于差异分析
预处理不是终点,而是为了让差异分析更可靠。知识库明确推荐Limma作为芯片差异分析的常用工具。它能把实验设计、批次信息和其他变量纳入线性模型,并通过经验贝叶斯方法提高小样本条件下的检验效能。
8. 7大难点七:方法选错会让预处理白做
8.1 倍数变化法不能替代规范流程
倍数变化法适合初筛,优点是简单、成本低,适合预实验。但它阈值主观,结论简单,可靠性有限。它不能代替完整的芯片数据预处理流程。
8.2 参数法、非参数法和Limma各有定位
t检验和方差分析适合满足前提条件的数据,但芯片样本通常不大,方差估计不稳定。非参数方法对分布要求低,但敏感性往往不如参数法。
相比之下,Limma更适合芯片数据。它利用线性模型、经验贝叶斯和多重检验校正,能够在样本量较少时保持较好的稳健性。对大多数芯片项目来说,Limma是更可靠的下游分析框架。
8.3 预处理和差异分析要衔接一致
一个常见错误是先用某种方式强行校正,再在下游模型里重复校正。比如不推荐先用removeBatchEffect处理后,再把同样的批次因素放进差异模型里反复修正。更合理的做法是从设计阶段就明确变量,减少重复变换。
结尾Conclusion
芯片数据预处理的核心,不是做得多,而是做得对。原始格式识别、质控、背景校正、标准化、批次效应处理、缺失值控制和结果验证,这7个环节决定了数据是否可用于后续差异分析。如果前处理不稳,后面的统计只是“修饰错误”。
对于医学生、医生和科研人员来说,最有效的路径是把预处理流程标准化,再用可靠的方法进入差异分析。Limma、Combat、SV等工具各有适用场景,关键在于根据数据特点选择。若你希望更高效地完成芯片数据预处理与下游分析,可以借助解螺旋 的课程与工具体系,把复杂流程拆成可执行步骤,减少试错成本。
- 引言Introduction
- 1. 芯片数据预处理为什么是第一道门槛
- 2. 7大难点一:原始数据格式复杂,读取容易出错
- 3. 7大难点二:样本质量不一致,质控不能省
- 4. 7大难点三:背景噪音和非正态分布干扰分析
- 5. 7大难点四:批次效应最容易“伪装成生物学差异”
- 6. 7大难点五:缺失值和低质量探针影响下游结果
- 7. 7大难点六:预处理后如何判断数据真的“干净”了
- 8. 7大难点七:方法选错会让预处理白做
- 结尾Conclusion



