引言Introduction
蛋白组数据格式看似只是表格整理,实际却直接影响检索、注释、复现和发表。很多医学生、医生和科研人员在提交数据时,常因格式不统一、字段缺失、命名混乱而反复返工。这篇文章用4个常见陷阱,帮你快速避坑。

1. 蛋白组数据格式为什么容易出错
1.1 数据来源多,字段标准不一致
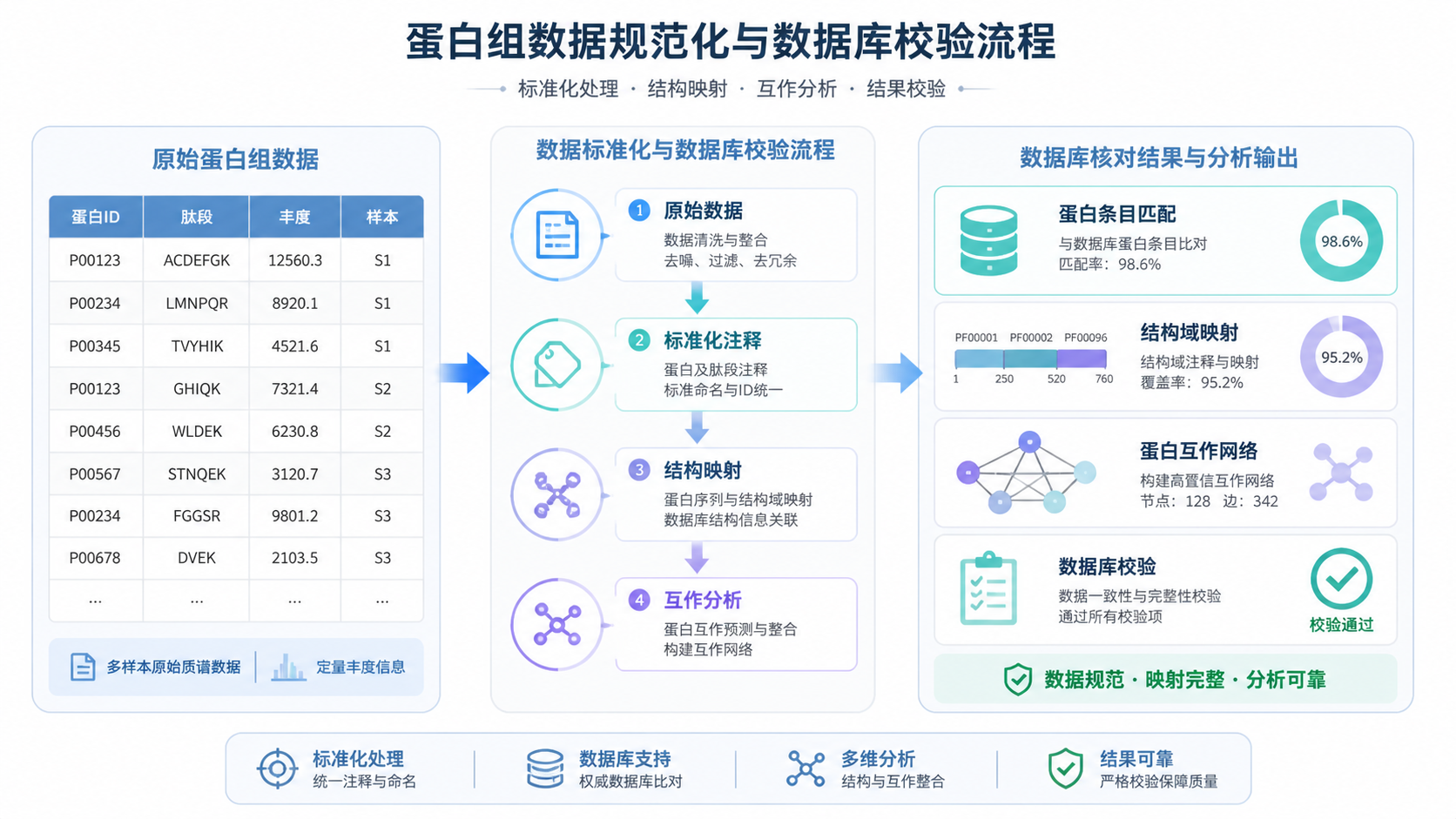
蛋白组数据常来自质谱平台、注释数据库和下游分析软件。不同工具输出的字段并不统一。常见情况包括蛋白ID、基因名、同工型、修饰位点、定量值混在一起。
如果没有先统一蛋白组数据格式,后续导入数据库或做交叉验证时就容易出错。
以 UniProt 相关条目为例,Sequence、Structure、Interaction、Feature viewer 等模块分别对应序列、结构、互作和位点注释。说明同一蛋白在不同分析层面需要不同字段支撑。若原始表格只保留“名称”,没有标准编号,后续很难和数据库精确匹配。
1.2 下游分析对格式很敏感
蛋白组数据格式不只是“能打开就行”。像 STRING 这类数据库可以展示已知和预测的蛋白相互作用,BindingDB 关注分子识别,CORUM、DIP、IntAct、MINT 则强调实验验证或人工整理的互作信息。
这些资源都依赖标准化标识符。一旦蛋白名称写法不统一,映射失败就会直接影响网络分析和功能注释。
2. 4个最常见的陷阱
2.1 只写蛋白名,不写唯一标识符
这是最常见的错误。很多人只保留“蛋白名称”或“基因简称”,忽略 UniProt 号、GeneID、RefSeq 等唯一标识。结果是同名异蛋白、异构体和物种差异无法区分。
例如,UniProt 的 Sequence 界面可显示标准蛋白序列、长度、分子量和异构体信息。Feature viewer 还能展示结构域、PTM、变体和肽段位置。如果数据表中没有对应的唯一编号,这些信息就无法准确回链。
建议做法:
- 每个蛋白保留一个主ID,如 UniProt accession。
- 同时记录基因名、物种、数据库来源。
- 区分 canonical sequence 与 isoform。
2.2 物种信息缺失或混写
蛋白组数据格式里,物种字段经常被忽略。人、鼠、猪、牛,甚至细菌蛋白混在一起时,后果会很严重。因为同一个蛋白名在不同物种中可能对应完全不同的序列和功能。
UniProt 的 Similar proteins 模块会按相似性显示不同物种的条目。50%、90%、100%相似阈值下,返回结果数量差异很大。这说明物种不明确时,结果集会迅速膨胀,注释质量也会下降。
建议做法:
- 统一使用拉丁学名和标准物种ID。
- 物种不要只写中文简称。
- 跨物种分析时单独分层统计。
2.3 序列、位点和修饰信息没有分层
很多表格把序列、氨基酸位点、修饰位点、交联位点放在同一列,或用同一种格式混写。这样会让软件解析失败,也不利于人工审阅。
UniProt 的 Feature viewer 会把 domain、region、nucleotide binding、PTM、cross-link、variants 等信息分层展示。这本质上提醒我们,蛋白组数据格式也要按功能层级拆分。
如果把“位点信息”全部堆在一个单元格里,后续做功能域定位、PTM 分析或结构映射时会非常麻烦。
建议做法:
- 序列单独成列。
- 位点单独成列,使用统一编号规则。
- PTM、交联、突变分别建字段,不要合并。
2.4 文件格式可读,但不利于机器处理
很多人交付数据时只考虑“人眼看得懂”,却忽略机器可读性。比如 Excel 多表混排、合并单元格、隐藏列、手工换行、特殊符号过多,都会影响脚本读取。
对于蛋白组数据格式,机器可读比排版美观更重要。
尤其在与 UniProt、Ensembl、KEGG、PDB、AlphaFold、PDBe、RCSB-PDB 等数据库联动时,规范字段和稳定分隔符能显著降低映射错误率。
建议做法:
- 优先使用 TSV、CSV 或标准化表格。
- 避免合并单元格。
- 每列只放一种类型的信息。
- 保留原始数据和清洗后的数据两版。
3. 如何把蛋白组数据格式整理得更稳
3.1 先定字段,再录入数据
不要边整理边改字段。先定义清楚每一列的含义。最少应包括:
- 蛋白唯一ID。
- 蛋白名称。
- 基因名。
- 物种。
- 序列长度。
- 分子量。
- 修饰位点。
- 来源数据库。
- 证据等级。
字段越早统一,后期越少返工。
3.2 用数据库做交叉校验
整理完成后,建议回到权威数据库核对。
- 用 UniProt 查序列、异构体、特征位点。
- 用 Structure 模块核对三维结构或 AlphaFold 预测结构。
- 用 Interaction、STRING、IntAct、DIP、MINT、CORUM 查看互作信息。
- 用 Ensembl、GeneID、KEGG 补全基因与通路注释。
交叉校验的目的,不是增加工作量,而是减少错误传播。
一次格式错误,可能会影响整条分析链。
3.3 让格式同时服务发表和复现
高质量蛋白组数据格式,不只是为了分析,更是为了投稿和复现。标准化后,审稿人更容易理解,合作方也更容易复用。
特别是涉及结构、互作、变体和 PTM 的项目,格式一旦统一,后续展示图、补充表和数据库提交都更顺畅。
4. 用什么思路避免反复返工
4.1 建立模板
建议团队内部固定一个蛋白组数据格式模板。模板一旦确定,就尽量不随项目变化频繁改动。这样可以减少沟通成本,也方便批量处理。
4.2 保留来源证据
每个关键字段都要能追溯来源。比如:
- 序列来自哪条 UniProt 记录。
- 结构来自 PDB 还是 AlphaFold。
- 互作来自文献、实验,还是预测。
- 变体和 PTM 是否有明确证据。
可追溯性是蛋白组数据格式能否被信任的核心。
4.3 借助专业工具减少低级错误
如果只是人工复制粘贴,出错概率一定更高。相比之下,专业数据库和标准化工具能帮助你更快完成映射、校验和整理。
这里也建议结合解螺旋的蛋白组数据整理与注释思路,把蛋白ID、结构、互作、位点和文献证据一次性规范化,减少重复劳动,提升投稿效率。
总结Conclusion
蛋白组数据格式的核心,不是“表格好看”,而是可检索、可映射、可复现、可追溯 。最常见的4个陷阱分别是:只写蛋白名、忽略物种、混写位点信息、文件不利于机器处理。
只要先定字段,再做数据库校验,并保留证据链,就能显著降低返工率。
如果你正在处理蛋白组数据格式,想把ID、序列、结构、互作和位点信息整理得更规范,可以结合解螺旋的专业工具与内容支持,减少出错,提升分析效率。
- 引言Introduction
- 1. 蛋白组数据格式为什么容易出错
- 2. 4个最常见的陷阱
- 3. 如何把蛋白组数据格式整理得更稳
- 4. 用什么思路避免反复返工
- 总结Conclusion