引言Introduction
临床样本数据常见问题是信息散、字段多、检索慢。很多人拿到数据后,不知道先看项目、样本,还是突变位点。如果你也在做肿瘤数据库分析,这篇文章会直接帮你理清临床样本数据的4种专业方法。

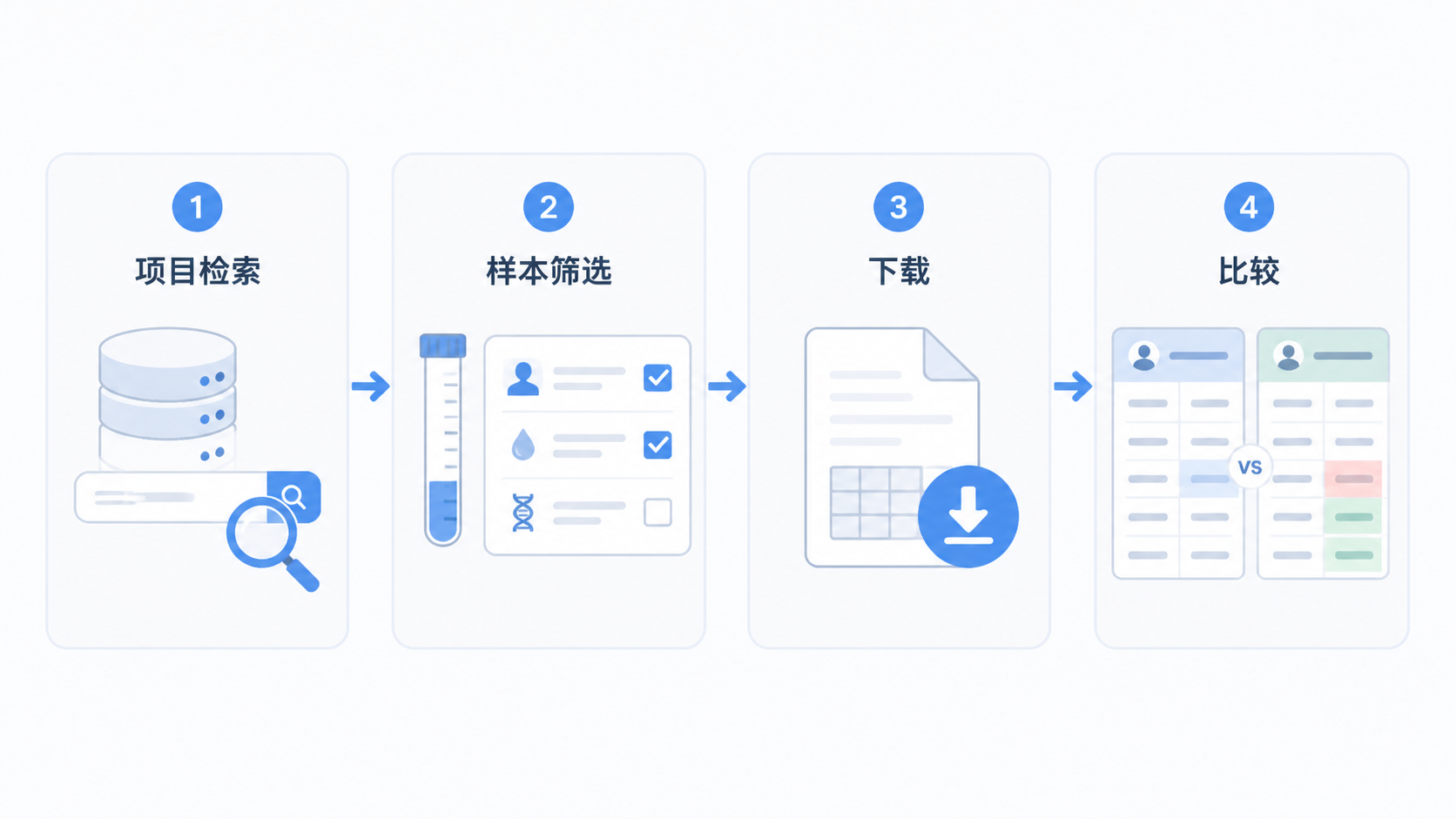
1. 先从项目层面看全局
1.1 项目检索适合回答“有哪些数据”
在 TCGA 数据库中,Projects 是最基础的检索入口。它适合先做全局判断。比如先确认某一癌种是否存在,数据是否充足,项目中包含哪些数据类型。
这一层最适合做“研究可行性筛查”。
例如你想找肺癌相关数据,可以先输入关键词,快速定位对应项目,再查看该项目可用的临床样本数据与分子数据。
1.2 项目页还能直接导出和排序
Projects 页面右下角的表格支持多种操作。你可以按列排序,也可以筛选显示列,还能导出当前表格或全部数据。
常用功能包括:
- 仅显示需要的列
- 按某一列升序或降序排序
- 导出当前显示数据为 tsv
- 导出全部列数据为 json
对临床样本数据解读来说,这一步很关键。
先把项目层面的信息理顺,再进入样本层面,会明显减少后续误判。
2. 再用样本和基因精准检索
2.1 Exploration 适合做精细筛选
Exploration 是更具体的检索模式。它支持按样本名称、样本 ID、基因名、突变点来找数据。对于临床样本数据分析,这一步相当于从“看总表”进入“看个体”。
你可以在这里完成三类常见任务:
- 通过样本名或样本 ID 定位病例
- 通过 Genes 选项卡按基因检索
- 通过 Mutations 选项卡按基因突变位点检索
如果研究问题聚焦到某个基因或某个突变,Exploration 比 Projects 更高效。
2.2 临床信息、基因和突变要分开看
Exploration 页面还支持三个方向的过滤:
- Clinical,查临床信息
- Genes,查基因信息
- Mutations,查突变信息
其中,Mutations 页面对临床样本数据尤其重要。它能显示:
- 突变染色体和坐标
- 突变类型
- 对蛋白翻译的影响
- 受影响人数及比例
- 突变后果严重程度
这意味着你不仅能看到“有没有突变”,还能看到“突变有多常见、后果有多重”。
对科研选题、靶点筛选和队列分层都很有用。
3. 用标准流程下载和核对数据
3.1 Repository 适合做数据下载
如果前两步已经定位到目标数据,Repository 就是下载入口。它支持按文件类型、样本特征和前面检索结果继续筛选,然后统一下载。
常见数据类型包括:
- WXS,全外显子测序
- WGS,基因组测序
- RNA-Seq,转录组数据
- miRNA-Seq,miRNA 数据
- Methylation Array,甲基化芯片
- Reverse Phase Protein Array,蛋白组学
临床样本数据分析前,先确认数据类型是否与研究设计一致。
比如你做表达分析,就应优先看 RNA-Seq,而不是把不同平台混在一起。
3.2 文件格式和工作流不能忽略
数据下载后,还要看文件格式和分析流程。常见格式包括:
- VCF,变异文件
- BAM 或 SAM,比对文件
- 表达矩阵文件
- 临床记录文件
同时,工作流也很重要。比如 BWA、STAR2、MuSE、BCGSC 等流程不同,处理结果会受影响。同类数据尽量使用相同流程比较,减少技术偏差。
对于临床样本数据,最常见的错误不是“找不到数据”,而是“下载了不适合比较的数据”。
4. 先验证,再分析,最后比较
4.1 Analysis 适合多数据集横向比较
TCGA 还有 Analysis 模式,最多可比较 3 个数据集的基本信息。它不是单纯查找,而是用于对比。
这一步适合回答:
- 不同项目之间差异是否明显
- 数据规模是否接近
- 是否适合继续做联合分析
对于临床样本数据,比较前先看项目构成,是避免后续模型失真的前提。
4.2 临床样本数据常见的4个判断标准
在正式分析前,建议按下面4步筛查:
-
疾病是否对应
研究肿瘤就不要混入非肿瘤队列。 -
物种是否一致
人、鼠、鼠类数据不能直接合并。 -
样本分组是否合理
有无对照组,分组是否清楚,比例是否接近。 -
平台和类型是否统一
芯片、测序、单细胞、甲基化不能随意直接合并。
这4项看似基础,但几乎决定了临床样本数据能不能用。
5. 解读时要抓住这几个核心细节
5.1 临床样本数据不是越多越好
样本数量重要,但不是唯一标准。对于不同研究类型,样本需求不同。比如转录组研究在小样本下仍可能成立,但基因组突变分析通常更依赖更大的样本量。
样本数少不等于不能做,关键是研究设计是否匹配。
5.2 先看临床字段,再看分子字段
做临床样本数据分析时,建议先确认以下信息:
- 性别
- 生存状态
- 分期
- 病种
- 复发或死亡结局
- 随访时间
然后再进入基因、突变、表达和蛋白层面。
这样更符合临床研究逻辑,也更利于后续做生存分析、分层分析和预测模型。
5.3 导出前先确认权限
TCGA 部分数据属于 controlled-access。也就是说,不是所有文件都能直接下载。没有账号时,尽量选择 open 数据。
这是很多初学者最容易忽略的一点。
如果前期不确认权限,后面会浪费大量时间。
结论Conclusion
临床样本数据解读难,核心不是“数据太多”,而是“没有按正确层级进入”。最稳妥的路径是:先看 Projects 做全局筛查,再用 Exploration 做样本和基因精查,随后通过 Repository 下载并核对格式,最后借助 Analysis 做数据比较。这4种专业方法能显著提高临床样本数据的可用性和研究效率。
如果你希望进一步提升检索、筛选和数据整合效率,可以直接借助解螺旋 的科研学习与分析资源,把复杂的临床样本数据流程标准化。少走弯路,才能更快进入可发表的分析阶段。
- 引言Introduction
- 1. 先从项目层面看全局
- 2. 再用样本和基因精准检索
- 3. 用标准流程下载和核对数据
- 4. 先验证,再分析,最后比较
- 5. 解读时要抓住这几个核心细节
- 结论Conclusion