引言Introduction
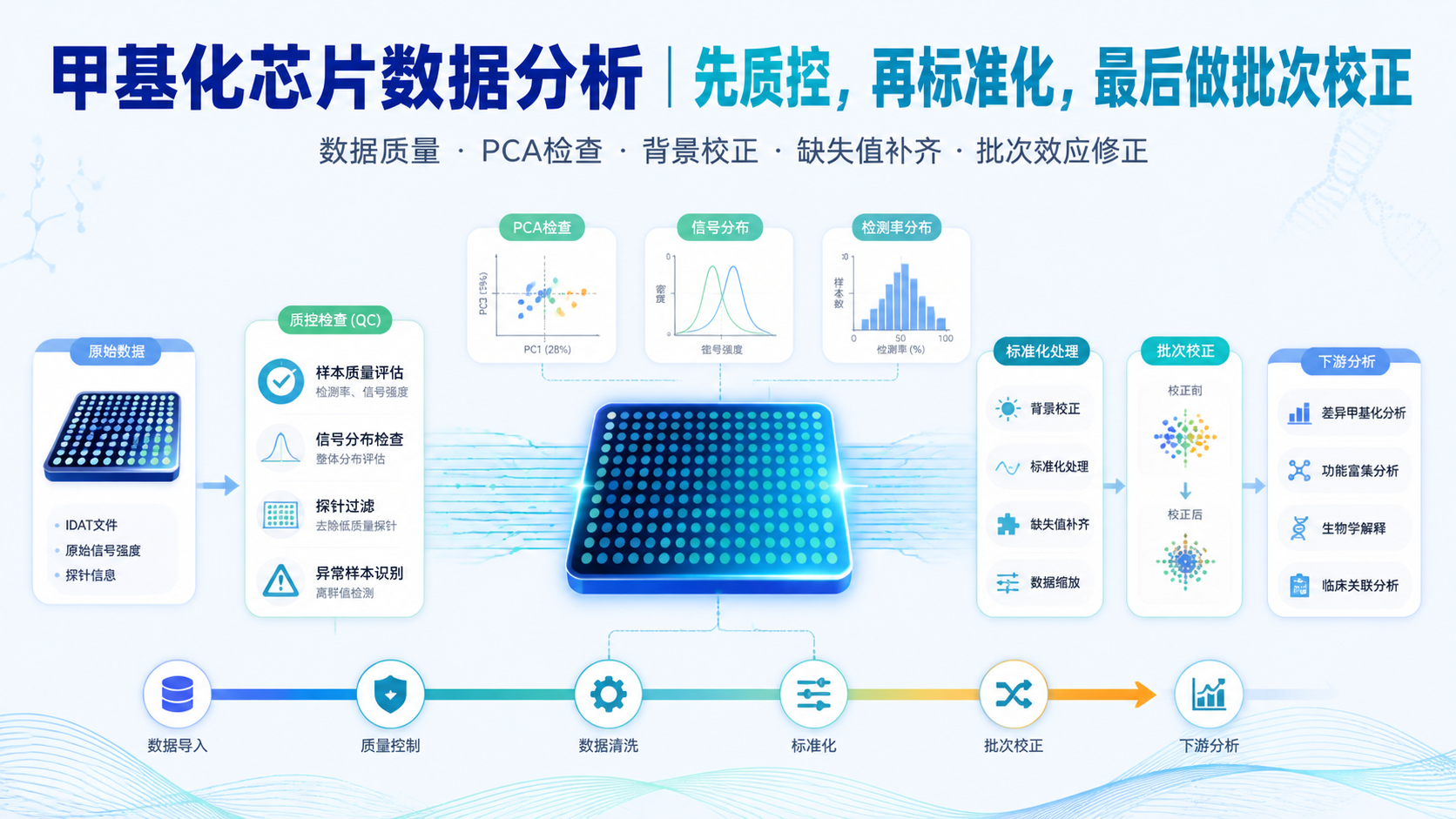
表达谱芯片数据能否可信,关键不在“有没有数据”,而在“误差是否被控制”。很多医学生和科研人员拿到表达谱芯片数据后,常见困惑是:信号看起来都在,为什么结果却不稳定,甚至前后矛盾。问题往往出在质量评估、背景噪音、标准化和差异分析四个环节。
1. 表达谱芯片数据的可信度,先看哪些环节出错
1.1 样本到扫描,任何一步都可能引入误差
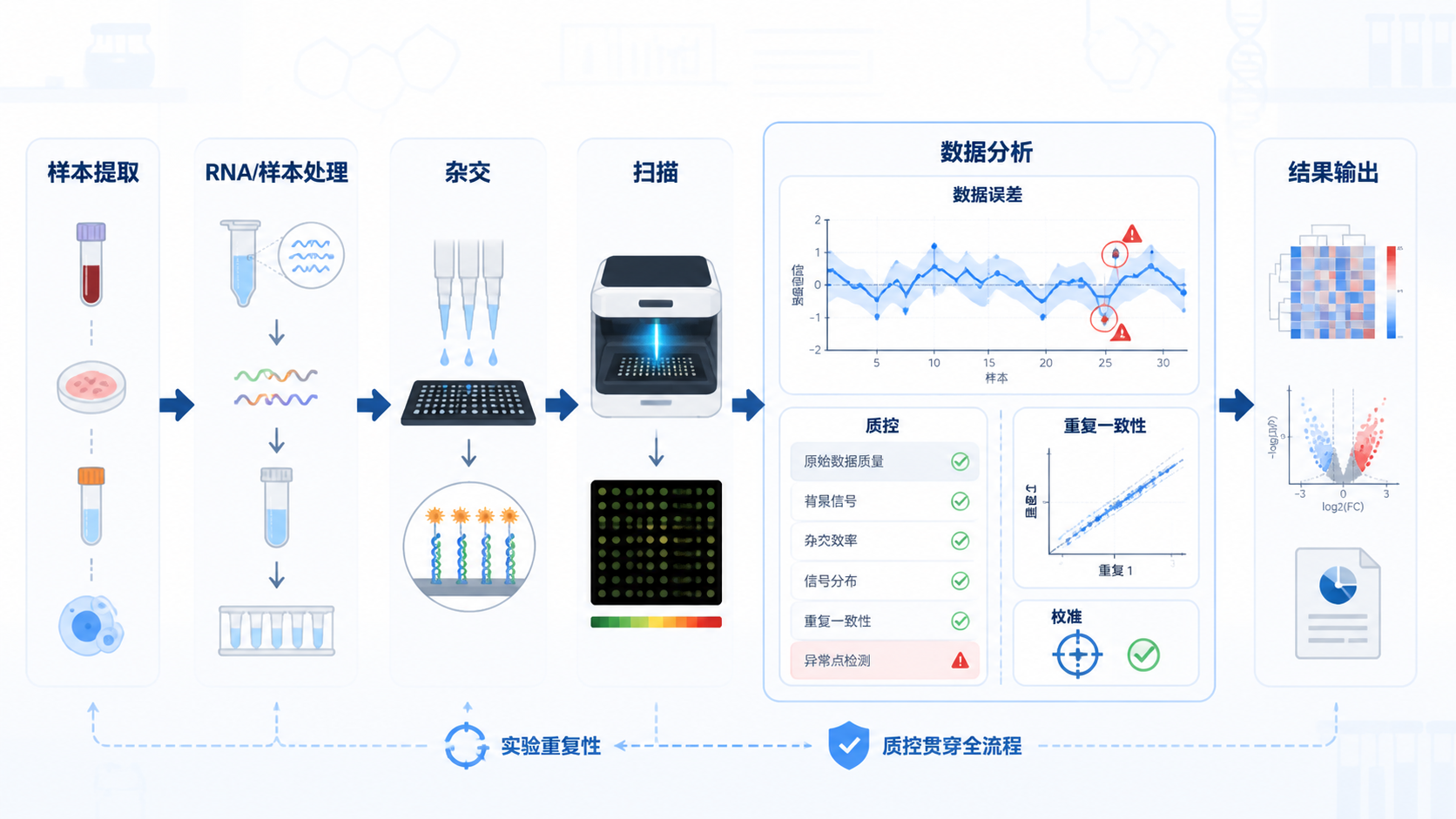
表达谱芯片数据并不是扫描后才开始“出问题”。从样本收集、RNA提取、荧光标记、探针杂交,到图像扫描和图像处理,每一步都可能影响最终结果。因此,芯片数据的可靠性,本质上取决于全流程控制。
如果RNA在实验前已降解,后续再怎么校正,质量也很难真正恢复。
如果某个芯片在扫描时存在微影、污染或局部异常,单个样本就可能偏离整体分布。
如果分组设计本身混入了批次效应,表面上看是生物学差异,实际上可能只是技术偏差。
1.2 单样本异常和分组异常,要分开判断
质量评估不能只看“整体像不像”。它要同时看两个层面。
一是单个样本是否异常。比如芯片图像是否异常、RNA降解是否严重。
二是整个分组是否存在异常样本。比如某个样本的表达分布与其他样本明显不同。
常用的判断手段包括MA plot、密度图、样本间距离、热图、PCA等。
如果异常样本已经明显偏离其他样本,通常应优先排查,必要时剔除。
这一步不是“挑数据”,而是保证后续分析可信。
2. 4类常见误差,如何识别
2.1 第一类误差,实验过程误差
这类误差来自实验本身。
包括RNA质量差、杂交效率不稳、扫描异常、局部污染等。
在原始图像中,常能看到整体偏亮、偏暗,或某些局部斑点、涂抹样异常。
课程中提到的做法很直接。可以先查看芯片图像,再结合RNA降解曲线和QC图判断。如果一个样本的RNA降解斜率明显更高,说明降解更严重,后续分析风险也更高。
2.2 第二类误差,背景噪音误差
背景噪音会让检测信号偏离真实表达水平。
这也是为什么不能直接拿原始荧光强度做比较。
背景校正的目标,是利用探针附近的背景强度,修正信号偏差。
需要注意的是,背景校正主要适用于原始数据。
如果数据已经经过背景校正或标准化,再重复处理,反而可能引入新误差。
例如从GEO下载的很多数据,已经是表达矩阵,不建议再次做背景校正。
2.3 第三类误差,系统偏差和批次效应
不同芯片之间、不同批次之间,常会出现系统性偏差。
这类误差不会只影响单个基因,而会影响整组样本的分布。
典型表现包括箱线图中心线不齐、密度图宽窄不一、PCA按批次聚类,而不是按生物分组聚类。
标准化的核心目的,就是让各样本表达分布尽量一致。
常见方法包括基于所有基因的标准化、基于管家基因的标准化,以及基于控制基因的标准化。
在表达谱芯片数据分析中,最常用的是基于所有基因的标准化。
如果拿到原始数据,通常可优先考虑RMA或GCRMA;如果只有表达矩阵,常见做法是quantile normalization。
2.4 第四类误差,统计分析误差
很多研究在这里容易出问题。
不是差异分析方法不行,而是前面质控没做好,后面再精细统计也救不回来。
例如样本量太少、组内变异过大、异常样本未处理,都会影响p值和假阳性率。
在差异分析中,Limma是最常用也最稳妥的方法之一。
它用线性模型纳入实验设计信息,还能结合经验贝叶斯方法处理小样本问题。
但前提是输入数据必须足够干净。
否则,模型越复杂,误差传播越明显。
3. 怎么判断表达谱芯片数据是否可用
3.1 先看原始质量,再看标准化效果
一个可靠的数据集,应该同时满足两个条件。
第一,原始数据没有明显异常样本。
第二,标准化后样本分布更加一致,批次效应被明显压低。
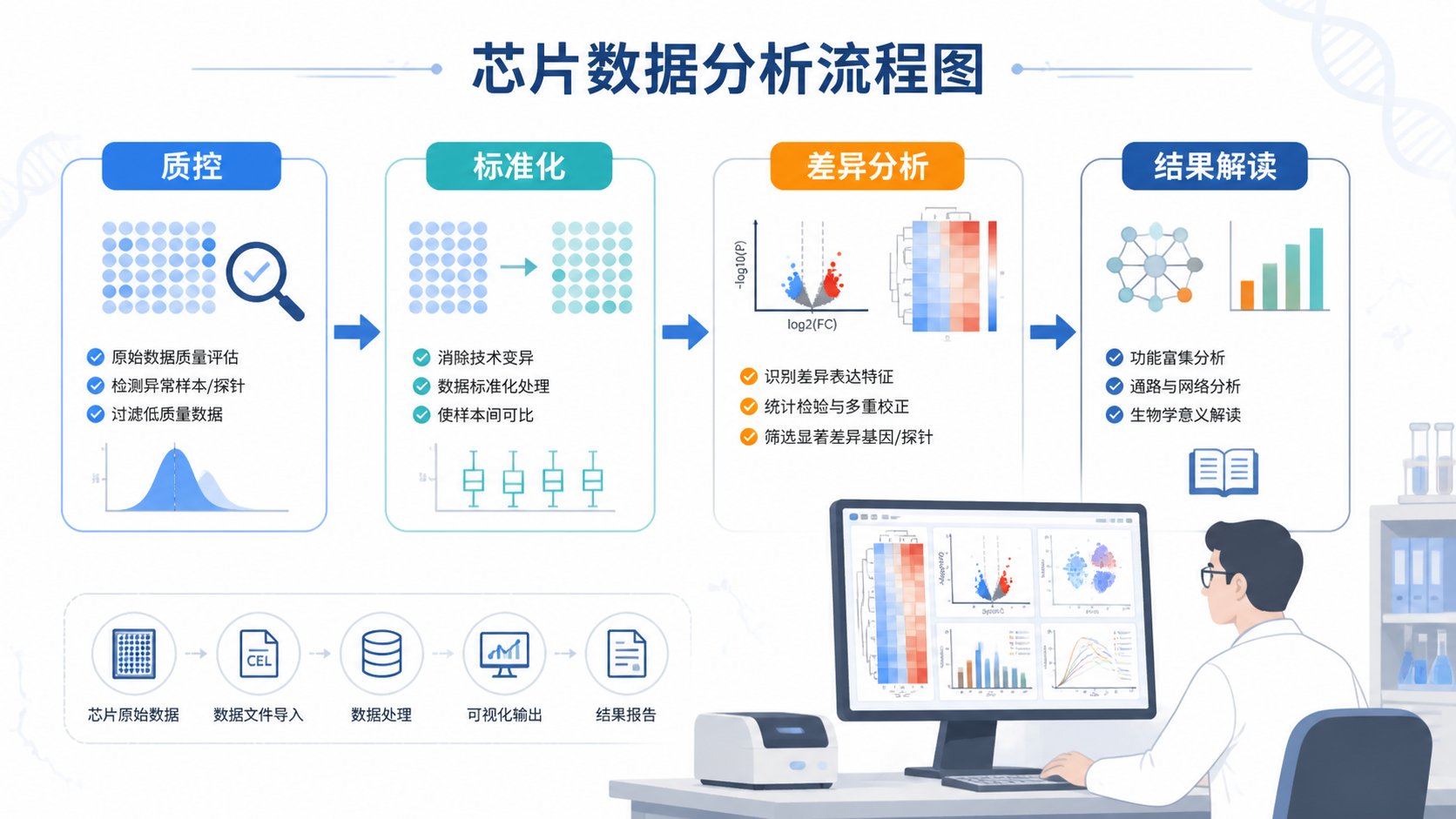
常用的判断顺序可以参考下面这套流程。
- 查看芯片图像。
- 检查RNA降解。
- 看箱线图和密度图。
- 做PCA或样本距离分析。
- 再进行背景校正和标准化。
- 最后进入差异分析。
如果标准化后PCA仍按批次分组,而不是按实验分组,说明数据仍存在明显技术偏差。
3.2 不是所有异常都能靠标准化修正
这是表达谱芯片数据分析里最容易被忽略的一点。
标准化能修正“分布偏移”,但修正不了“样本已坏”。
比如RNA严重降解、芯片扫描污染、样本混入错误,这些问题很难通过算法彻底补救。
因此,评估时不要只盯着校正结果。
要回看原始图像、降解曲线和质量报告。
能修的修,不能修的就果断剔除。
这比保留“看起来很多”的样本更重要。
4. 为什么很多高质量研究仍在用表达谱芯片数据
4.1 优势在于定量稳定和分析成熟
与测序相比,表达谱芯片数据有自己的应用场景。
它的定量通常更稳定,实验和分析流程也更成熟。
对部分低丰度转录本、FFPE样本或需要快速完成项目的研究,芯片仍然有价值。
此外,芯片平台历史悠久,很多经典公开数据都来自芯片。
这意味着它在回顾性分析、队列整合和文献复现中仍然很常见。
4.2 关键不在平台,而在数据治理
很多人问“表达谱芯片数据靠谱吗”,其实真正该问的是:
数据有没有经过规范的质控和标准化。
有没有异常样本识别。
有没有合理的差异分析策略。
一套好的分析流程,往往比平台本身更决定结果可信度。
对于科研人员来说,真正高效的做法不是跳过质控,而是把质控前置。
先筛掉明显异常样本,再做背景校正和标准化,最后进入差异分析。
这样得到的结果,才更接近真实生物学信号。
总结Conclusion
表达谱芯片数据并非天然“靠谱”或“不靠谱”。它的可信度,取决于你是否识别并控制了四类误差:实验过程误差、背景噪音误差、系统偏差误差和统计分析误差。只要质控到位,标准化合理,差异分析得当,表达谱芯片数据依然可以产生稳定、可复现的结论。
如果你正在做芯片数据分析,建议优先使用解螺旋的系统化学习和工具支持,把质控、标准化和差异分析一步步做扎实。这样不仅能减少返工,也能提高论文结果的可信度与说服力。
- 引言Introduction
- 1. 表达谱芯片数据的可信度,先看哪些环节出错
- 2. 4类常见误差,如何识别
- 3. 怎么判断表达谱芯片数据是否可用
- 4. 为什么很多高质量研究仍在用表达谱芯片数据
- 总结Conclusion