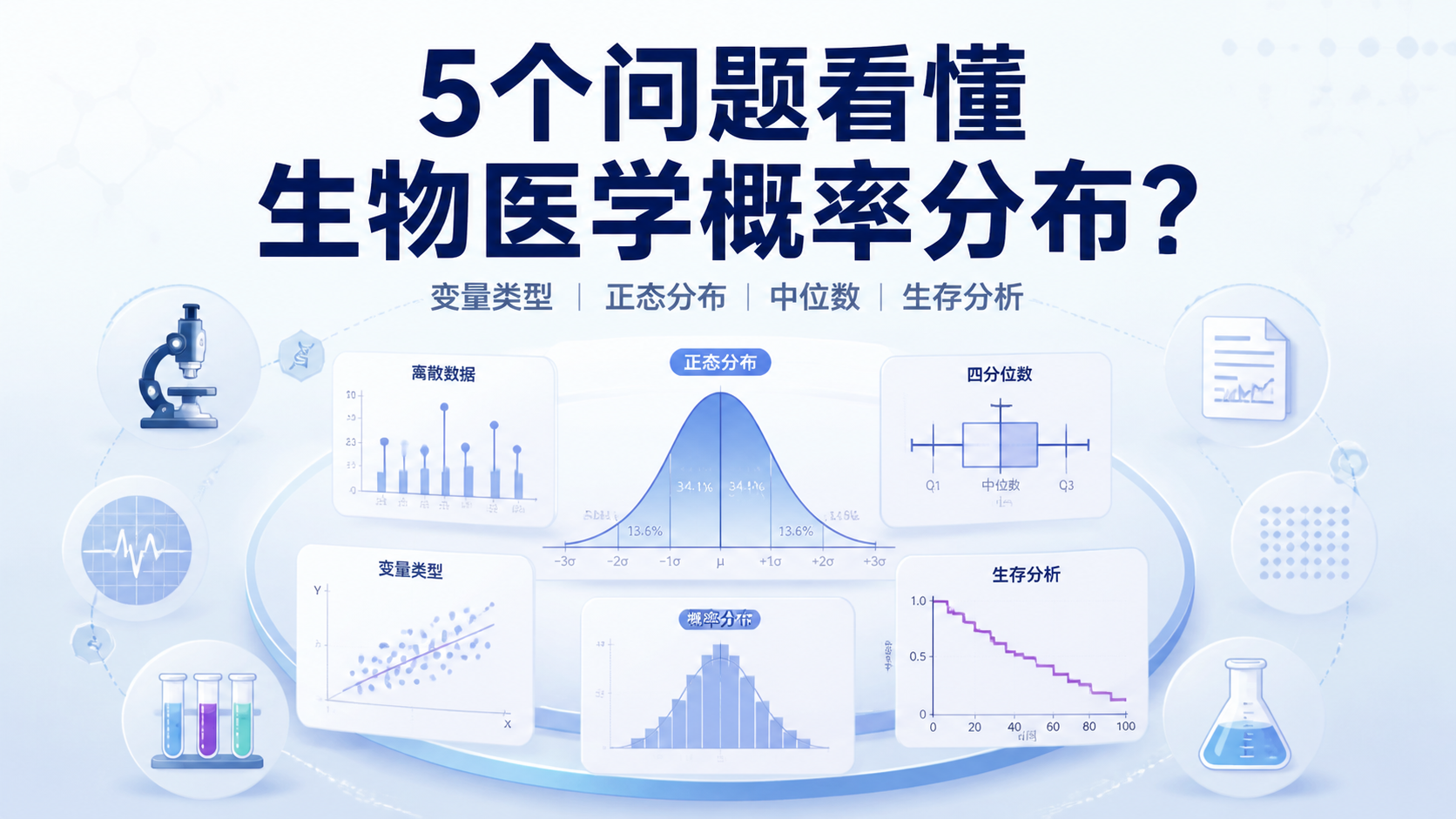
引言Introduction
在生物医学研究中,很多人会先算均值、P值,却忽略了概率分布 本身是否合适。结果就是,描述失真,推断偏差,模型也不稳。对医学生、医生和科研人员来说,真正难点不是“会不会算”,而是什么时候用哪种分布,为什么要这样用 。下面用5个问题,快速看懂生物医学概率分布。
1. 概率分布到底在回答什么问题?
1.1 它不是“数字长什么样”,而是“数据怎么落”
概率分布的核心,是描述随机变量取值的规律。它告诉我们,数据更可能集中在哪些位置,哪些值出现得少,整体是否对称,是否偏斜,是否有长尾。
在医学研究里,这个问题非常关键。因为同样是连续变量,BMI、年龄、血糖、住院费用,常常呈现不同形态。如果分布判断错了,后面的统计描述和检验方法就可能不合适。
1.2 先看分布,再选方法
上游知识库反复强调,医学统计至少要解决三件事,描述、推断和效应量估计 。而概率分布,正是描述和推断的前提。
常见的逻辑很简单:
- 连续变量且近似正态,常用均值和标准差。
- 连续变量但偏态明显,常用中位数和四分位数。
- 分类变量,常用频数和率。
也就是说,概率分布不是附加项,而是方法选择的起点。
2. 为什么正态分布在医学里这么常见?
2.1 它适合描述“多数居中、少数偏离”的数据
正态分布的特点是中间高、两边低,左右相对对称。很多生物医学指标在一定条件下会接近这种形态,比如部分生理指标、测量误差、群体中的身高分布。
这类数据的均值能代表中心位置,标准差能反映离散程度。均值回答“中心在哪”,标准差回答“离散多大”。
2.2 何时可用均值和标准差
判断时不要只凭经验,要看数据形态。若数据近似正态,常见写法是“均值±标准差”。
例如:
- 某组BMI为 21.0±3.5。
- 这里21.0表示集中趋势。
- 3.5表示波动范围。
上游内容也指出,标准差越大,曲线越扁平,数据越分散;标准差越小,数据越集中。
2.3 什么时候不该硬套正态
工资、住院费用、某些检验指标、住院天数,常出现明显偏态。此时如果还用均值描述,就可能把少数极端值放大,掩盖真实水平。
这也是为什么很多医学论文在偏态数据上改用中位数和四分位数。不是为了“形式更高级”,而是为了让描述更接近真实分布。
3. 中位数、四分位数和频数,分别对应什么分布?
3.1 偏态连续变量更适合中位数
如果数据分布不对称,中心位置更适合用中位数表示。中位数是把数据排序后位于中间的那个值。它不容易被极端值拉偏。
例如工资分布。少数高收入者会把均值拉高,但中位数更能代表“多数人处在哪个水平”。这就是偏态分布下中位数的价值。
3.2 四分位数补充了离散信息
中位数只告诉你“中心”。但如果要描述分布宽度,还需要四分位数。常见是Q1和Q3,也就是25%和75%位置。
论文里常见表达包括:
- 中位数(Q1,Q3)
- 中位数(四分位距)
- 中位数(最小值,最大值)
需要注意,后两种写法容易混淆。必须结合注释或正文判断它到底表示什么。
3.3 分类变量直接看频数和率
无论是二分类、多分类,还是有序分类,通常都可以用频数和百分比描述。
例如:
- 高血压:有/无。
- 分期:I期、II期、III期。
- 病理类型:腺癌、鳞癌、其他。
上游知识库指出,分类资料描述最常用的方式就是频数和率。
这类变量没有连续数值的均值意义,也不必强行做正态假设。
4. 离散型数据为什么常被“特殊处理”?
4.1 离散型数据不是连续值
离散型数据只能取整数,不能无限细分。比如:
- 发作次数。
- 住院次数。
- 48小时内排便次数。
- 手术并发症次数。
这些变量看起来像“数字”,但本质上不是连续变量。
4.2 它有时按连续变量处理,有时按分类变量处理
这类数据是否当作连续变量,要看取值范围和分布。
如果范围较宽,且近似连续,可以近似用均值和标准差。
如果多数集中在0、1、2这类小整数,往往更适合按分类变量处理。
上游知识库给出的判断思路是:离散型数据在某些情况下可按连续型描述,在某些情况下应按分类资料描述。
4.3 关键是“是否会丢失信息”
处理离散型数据时,最重要的问题不是形式,而是信息保留。
- 直接当连续变量,可能简化分析。
- 分层后当分类变量,可能更符合临床解释。
- 但过度分组,也会损失统计效率。
所以在医学研究中,分布判断不能只看技术方便,还要看临床含义。
5. 生存资料和概率分布是什么关系?
5.1 生存分析本质上也是在处理分布
生存资料研究的是“事件何时发生”。事件可以是死亡、复发、进展、再入院。这里的重点不是单纯“发生与否”,而是发生时间的分布 。
Kaplan-Meier法用于估计生存率曲线,本质上就是在估计随时间变化的概率分布。
5.2 中位生存时间不是中位随访时间
这是医学研究里最容易混淆的点之一。
- 中位生存时间 :有一半对象达到终点的时间。
- 中位随访时间 :所有个体随访时长排序后的中位数。
一个是结局时间分布,一个是观察时间分布。两者完全不同。
上游知识库明确指出,中位生存时间是“半数概念”,不是“中位数概念”。
5.3 事件数不足会影响分布估计
生存分析对样本和事件数有要求。若终点事件太少,曲线会不稳定,估计精度也会下降。
知识库建议至少要有一定比例对象出现终点。理想情况下越多越好,至少要能支持中位生存时间的估计,或者保证一定数量事件发生。事件太少,生存分布就很难可靠判断。
6. 如何在论文中正确表达概率分布?
6.1 先判断变量类型,再判断分布
建议按这个顺序写作:
- 先确认变量是连续、分类还是离散。
- 再判断是否近似正态。
- 最后选择描述方式和统计方法。
例如:
- 正态连续变量:均值±标准差。
- 偏态连续变量:中位数(四分位数)。
- 分类变量:n(%)。
这比直接套模板更符合E-E-A-T原则。
6.2 结果部分要写清楚“效应量”
医学统计不能只写“有差异”或“有关联”。还要给出量化结果。知识库强调,应使用OR、RR、HR等效应量回答“多大程度上”。
这意味着,描述分布只是第一步。后面还要进入:
- 组间比较。
- 关联强度。
- 风险估计。
- 生存结局分析。
没有效应量,结论往往不够完整。
6.3 做到可读、可复核、可复现
论文中最好同时交代:
- 数据类型。
- 分布判断依据。
- 采用的统计量。
- 是否进行了正态性检验或图形判断。
- P值和效应量。
这样读者不仅知道结果,还能判断方法是否合理。这就是高质量医学写作的基本标准。
总结Conclusion
生物医学中的概率分布 ,不是抽象数学概念,而是决定“怎么描述、怎么比较、怎么建模”的基础。先判断变量类型,再判断分布形态,才能选对均值、标准差、中位数、四分位数、频数和率。对生存资料,还要进一步理解事件时间分布与中位生存时间的区别。
如果你正在写论文、做课题、整理统计结果,却总担心分布判断不准、方法选错、结果写不规范,可以借助解螺旋 的医学写作与科研支持思路,把统计表达、论文结构和结果呈现一次性理顺。这样更省时间,也更符合临床研究的规范表达。
- 引言Introduction
- 1. 概率分布到底在回答什么问题?
- 2. 为什么正态分布在医学里这么常见?
- 3. 中位数、四分位数和频数,分别对应什么分布?
- 4. 离散型数据为什么常被“特殊处理”?
- 5. 生存资料和概率分布是什么关系?
- 6. 如何在论文中正确表达概率分布?
- 总结Conclusion